|
Relationship
Relationships and Keys
A relationship is an association between two or more tables. Relationships are expressed in the data values of the primary and foreign keys.
A primary key is a column or columns in a table whose values uniquely identify each row in a table. A foreign key is a column or columns whose values are the same as the primary key of another table. You can think of a foreign key as a copy of primary key from another relational table. The relationship is made between two relational tables by matching the values of the foreign key in one table with the values of the primary key in another.
Keys are fundamental to the concept of relational databases because they enable tables in the database to be related with each other. Navigation around a relational database depends on the ability of the primary key to unambiguously identify specific rows of a table. Navigating between tables requires that the foreign key is able to correctly and consistently reference the values of the primary keys of a related table. For example, the figure below shows how the keys in the relational tables are used to navigate from AUTHOR to TITLE to PUBLISHER. AUTHOR_TITLE is an all key table used to link AUTHOR and TITLE. This relational table is required because AUTHOR and TITLE have a many-to-many relationship.
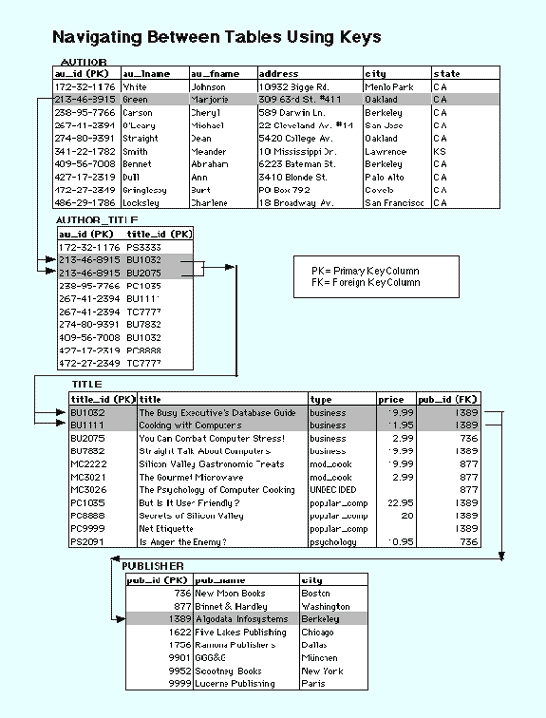
Data Integrity
Data integrity means, in part, that you can correctly and consistently navigate and manipulate the tables in the database. There are two basic rules to ensure data integrity; entity integrity and referential integrity.
The entity integrity rule states that the value of the primary key, can never be a null value (a null value is one that has no value and is not the same as a blank). Because a primary key is used to identify a unique row in a relational table, its value must always be specified and should never be unknown. The integrity rule requires that insert, update, and delete operations maintain the uniqueness and existence of all primary keys.
The referential integrity rule states that if a relational table has a foreign key, then every value of the foreign key must either be null or match the values in the relational table in which that foreign key is a primary key.
Relational Data Manipulation
Relational tables are sets. The rows of the tables can be considered as elements of the set. Operations that can be performed on sets can be done on relational tables. The eight relational operations are:
Union
The union operation of two relational tables is formed by appending rows from one table with those of a second table to produce a third. Duplicate rows are eliminated. The notation for the union of Tables A and B is A UNION B.
The relational tables used in the union operation must be union compatible. Tables that are union compatible must have the same number of columns and corresponding columns must come from the same domain. Figure1 shows the union of A and B.
Note that the duplicate row [1, A, 2] has been removed.
Figure1: A UNION B
[img1]
Difference
The difference of two relational tables is a third that contains those rows that occur in the first table but not in the second. The Difference operation requires that the tables be union compatible. As with arithmetic, the order of subtraction matters. That is, A - B is not the same as B - A. Figure2 shows the different results.
Figure 2: The Difference Operator
[img2]
Intersection
The intersection of two relational tables is a third table that contains common rows. Both tables must be union compatible. The notation for the intersection of A and B is A [intersection] B = C or A INTERSECT B. Figure3 shows the single row [1, A, 2] appears in both A and B.
Figure3: Intersection
[img3]
Product
The product of two relational tables, also called the Cartesian Product, is the concatenation of every row in one table with every row in the second. The product of table A (having m rows) and table B (having n rows) is the table C (having m x n rows). The product is denoted as A X B or A TIMES B.
Figure 4: Product
[img4]
The product operation is by itself, not very useful. However, it is often used as an intermediate process in a Join.
Projection
The project operator retrieves a subset of columns from a table, removing duplicate rows from the result.
Selection
The select operator, sometimes called restrict to prevent confusion with the SQL SELECT command, retrieves subsets of rows from a relational table based on a value(s) in a column or columns.
Join
A join operation combines the product, selection, and, possibly, projection. The join operator horizontally combines (concatenates) data from one row of a table with rows from another or the same table when certain criteria are met. The criteria involve a relationship among the columns in the join relational table. If the join criterion is based on equality of column value, the result is called an equijoin. A natural join, is an equijoin with redundant columns removed.
Figure 5 illustrates a join operation. Tables D and E are joined based on the equality of k in both tables. The first result is an equijoin. Note that there are two columns named k; the second result is a natural join with the redundant column removed.
Figure 5: Join
[img5]
Joins can also be done on criteria other than equality.
Division
The division operator results in columns values in one table for which there are other matching column values corresponding to every row in another table.
Figure 6: Division
[img6]
|
