|
원본 출처 : http://korea.internet.com/channel/content.asp?cid=209&nid=10725
이글은 오라클 OCP 기출문제에 대해 해석과 더불어 풀어 놓은 것은 옮겨 놓은 것입니다. 문제의 해석이라는 관점보다는 기초 공부하시는 분들 한번 읽어 보시면 도움이 되리라는 생각에 올려 둡니다.
================================================
공략 포인터
Oracle7.3부터 Oracle8, Oracle8i 트랙에 이르기까지 유일하게 버전 구분 없이 공통적으로 출제되는 과목이다.
모든 사람들이 가장 쉽다고 공감하는 만큼 조금만 신경을 쓰면 어렵지 않게 패스할 수 있다. 그러나 만약 이 과목에서 낙방한다면 테스트 센터에서 성적표를 나눠주는 직원의 눈빛을 영원히 잊을 수 없고 직장에서는 얼굴을 들고 다니기 힘들 것이다. 쉬운 과목일수록 실력을 확실히 갈고 닦아야 한다.
이 글을 읽는 분이라면 SQL에 대해서 어느 정도의 지식은 가지고 있을 것이라 생각된다. SQL은 처음에는 별 것 아닌 것 같지만 깊이 들어갈수록 그 절묘함에 경탄하지 않을 수가 없다.
SQL의 기본은 한방 정신이다. C++로 프로그램을 만들면 수 십만 라인으로 이루어졌다고 자랑할 수 있겠지만 SQL의 세계에서는 그런 얘기를 했다가는 무시 당하기 십상이다. SQL은 모든 작업을 단 한번의 명령으로 끝내야만 전문가 레벨로 등극할 수 있는데 하나의 명령으로 할 수 있는 작업을 여러 개의 명령으로 처리하면 그 만큼 성능 저하가 확연히 드러나기 때문이다.
PL/SQL은 오라클 고유의 언어로 SQL에 절차형 언어의 성격을 부여하여 부족한 기능을 채워주는 역할을 한다. 오라클로 향하는 모든 길은 PL/SQL로 통한다고 해도 과언이 아닐 만큼 중추적인 요소이므로 오라클을 속속들이 알기 위해서는 PL/SQL에 대해서 통달할 필요가 있다. 물론 이 과목에서는 제목에도 나와있듯이 PL/SQL에 대한 기초적인 지식만을 평가하므로 마음 편하게 준비하길 바란다.
자, 이제부터 실전 문제를 풀어보도록 하자.
관계형 데이터베이스와 오라클
1-1. 제니퍼는 마이애미 주립대학 건축학과에 재학 중인데 새 학기가 시작되면서 졸업 논문을 담당할 지도 교수를 결정해야 한다. 건축학과에는 총 300명의 학생과 28명의 교수가 있으며 4명을 제외한 24명 중에서 세부 전공에 따라 지도 교수를 선택할 수 있다. 일단 지도교수를 선택하면 바꿀 수 없으므로 신중하게 결정해야 한다. 이 때 학생과 지도 교수 간의 관계는 어떻게 표현될 수 있는가?
a. M:1
b. 1:M
c. 1:1
d. M:M
<해설>
모델링이 실무에서는 매우 중요한 분야이지만 본 시험은 DBA를 위한 것이기 때문에 기본적인 엔터티(Entity) 간의 관계 정도만 알아두면 된다.
이 문제에서는 학생과 지도 교수가 엔터티에 해당되는데 이들의 관계는 모델링을 전혀 모르는 상태에서도 곰곰이 생각해 보면 쉽게 알 수 있다.
각 지도 교수는 한 명 이상의 학생을 가르치지만 각 학생은 단 한 명의 지도 교수를 선택해야 한다. 따라서 학생은 M 이고 지도 교수는 1 인 관계에 놓여있음을 알 수 있다.
정답 : (a) (<- 마우스로 정답 부분을 선택하세요)
비슷한 문제를 하나 더 풀어보자.
1-2. 위의 문제에서 각 지도 교수 밑에는 세 명의 조교가 있으며 이 들이 교대로 돌아가면서 학생들의 논문 작성을 도와주고 있다. 그렇다면 학생과 조교 간의 관계는 어떻게 표현될 수 있는가?
a. M:1
b. 1:M
c. 1:1
d. M:M
<해설>
각 학생은 세 명의 조교로부터 돌아가면서 배우게 되고 각 조교는 여러 명의 학생들을 도와주게 된다. 따라서 학생과 조교는 M:M 관계임을 알 수 있다. 단, M:M 관계는 관계형 데이터베이스에서 직접적으로는 지원되지 않고 상세개념모델 단계에서 분할됨을 유념해야 한다.
정답 : (d) (<- 마우스로 정답 부분을 선택하세요)
1-3 캘리포니아에 위치한 스털링 엔지니어링이란 회사에서 인사관리 시스템을 만들기 위한 기초 작업으로 다음과 같이 ERD를 작성하였다. 이 그림에 나타난 부서와 신입사원 간의 관계를 가장 잘 표현한 것은? (정답은 두 가지)
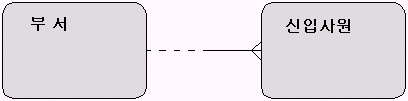
a. 각 부서는 한 명 이상의 신입사원을 배치 받을지도 모른다.
b. 각 신입사원은 한 곳 이상의 부서에 소속될지도 모른다.
c. 각 부서는 단 한 명의 신입사원을 반드시 배치 받아야 한다.
d. 각 신입사원은 단 하나씩의 부서에 반드시 소속되어야 한다.
<해설>
마치 언어 인지력을 테스트하는 문제 같다. 실제 시험에서는 영문으로 출제되므로 영어 표현을 알아두는 것이 좋다.
한글 영문
하나 이상 one or more
단 하나씩 one and only one
실 선 solid line
점 선 dashed line
까마귀 발 crow’s foot
한 부서는 여러 명의 신입사원을 받을 수 있으므로 신입사원은 부서에게 까마귀 발, 즉 하나 이상의 관계로 연결되지만 신입사원이 전혀 배정되지 않는 부서도 있을 것이므로 선택 사양은 점선(maybe)으로 표현된다.
한 신입사원은 동시에 여러 부서에 배치될 수 없고 오직 한 부서에만 배치될 수 있으므로 단 하나씩(one and only one) 관계로 부서에 연결되며 반드시 어떤 부서에는 반드시 배치되어야 하므로 선택 사양은 실선(must be)으로 표시된다.
정답 : (a) (d) (<- 마우스로 정답 부분을 선택하세요)
오늘부터 실전 문제 풀이로 들어갔다. 문제와 관련된 질문은 이 곳 의견게시란을 이용해 주기 바란다.
기본적인 SQL문 작성하기
2-1. SQL에서 사용되는 논리 연산자 중에서 우선 순위가 가장 높은 것은?
a. AND
b. OR
c. NOT
d. 모두 같다.
<해설>
연산자는 크게 산술 연산자, 비교 연산자, 논리 연산자로 분류할 수 있다(집합 연산자는 용도가 다르므로 제외). 이 세 가지 연산자 간의 우선 순위는 아래와 같다.
산술 연산자 > 비교 연산자 > 논리 연산자
그리고 논리 연산자의 우선 순위는
NOT > AND > OR
이다. 연산자 우선 순위는 확실하게 외워두지 않으면 시험에서 혼동하기 쉬우므로 꼭 기억해 두기 바란다.
정답 : (c) (<- 마우스로 정답 부분을 선택하세요)
2-2. 다음 보기 중에서 모든 데이터타입에 대하여 적용할 수 있는 연산자는? (정답은 두 가지)
a. +
b. LIKE
c. NOT
d. BETWEEN … AND …
<해설>
+는 산술 연산자이다. 문자열에 대해서는 ‘Larry’ + ‘Ellison’ 이라고 표현할 수 없으며 대신 ‘Larry’ || ‘Ellison’ 과 같이 기술해야 한다.
LIKE는 패턴 매칭에 사용되지만 아래와 같이 숫자 컬럼에 대해서도 이용할 수 있다. 숫자 컬럼에 대해서 사용하면 오라클 내부적으로 숫자 컬럼을 문자열 타입으로 변환해서 처리하므로 정상적으로 수행된다. 단, 타입 변환이 일어나므로 숫자 컬럼에 걸려 있는 인덱스는 사용할 수 없음을 주의해야 한다.
SELECT *
FROM emp
WHERE empno LIKE ‘79%’
NOT은 논리 연산자이기 때문에 어떠한 조건에 대해서만 사용할 수 있다.
BETWEEN이나 부등호 기호는 숫자나 날짜 뿐 아니라 문자열에도 사용할 수 있다. 이 때에는 사용 중인 문자집합(Characterset)에 따라서 비교 방법이 결정된다.
정답 : (b) (d) (<- 마우스로 정답 부분을 선택하세요)
2-3. 다음 중에서 에러가 발생하지 않는 SELECT 문은?
a. SELECT ename, DISTINCT empno FROM emp
b. SELECT *, ALL empno FROM emp
c. SELECT DISTINCT empno, DISTINCT ename FROM emp
d. SELECT ALL * FROM emp
<해설>
DISTINCT와 ALL 키워드는 SELECT 리스트의 처음에 한 번만 나와야 한다. 이들은 SELECT 리스트의 중간에 위치할 수 없으며 여러 번 사용해서도 안 된다.
ALL은 디폴트 값이므로 꼭 명시할 필요는 없다. DISTINCT는 동일한 레코드는 한 번만 보여주는 옵션으로 서브쿼리를 이용하는 방법보다 속도가 빠르기 때문에 테이블에 존재하는 중복된 레코드를 제거할 때 자주 사용된다.
정답 : (d) (<- 마우스로 정답 부분을 선택하세요)
2-4. SQL문에서 주석을 추가할 때 사용되는 기호는? (정답은 두 가지)
a. /*, */
b. ++
c. --
d. //
e. ##
<해설>
/*, */는 주석을 여러 줄에 걸쳐서 쓸 때 많이 사용되고 한 줄에만 쓴다면 --을 사용하는 것이 간편하다. C++과 혼동해서 //를 선택하지 않도록 주의해야 한다.
참고로 SQL 스크립트에서 각 SQL 문 사이에 주석을 표시할 때에는 REMARK 명령을 써야 하고 스키마 객체에 대한 주석을 만들 때에는 COMMENT 명령을 사용한다.
정답 : (a) (c) (<- 마우스로 정답 부분을 선택하세요)
2-5. DEPT 테이블에는 총 4 건의 데이터가 들어 있다.
DEPTNO DNAME LOC
10 ACCOUNTING NEW YORK
20 RESEARCH DALLAS
30 SALES CHICAGO
40 OPERATIONS BOSTON
이 때 다음 SELECT 문을 실행할 경우 몇 건의 데이터가 출력되는가?
SELECT *
FROM dept
WHERE deptno NOT IN (10, 20, NULL)
a. 0
b. 1
c. 2
d. 3
e. 4.
<해설>
이 SELECT 문을 NOT IN 대신 AND 연산자로 풀어 써 보자.
SELECT *
FROM dept
WHERE deptno != 10 AND deptno != 20 AND deptno != NULL
NULL과의 연산은 || 연산자를 제외하고는 모두 NULL로 처리되므로 deptno != NULL 의 결과는 NULL이고 이 값과의 AND 연산도 NULL이 된다. 따라서 연산의 최종 결과가 NULL이므로 WHERE 조건을 만족시키는 데이터는 하나도 없다.
정답 : (a) (<- 마우스로 정답 부분을 선택하세요)
데이터의 정렬과 필터링
3-1. 다음 SELECT 문을 실행했을 때 나올 수 있는 결과로 적합한 것은?
SELECT name
FROM mammal
WHERE name LIKE ‘%L#_%’ ESCAPE ‘#’
a. WILD_CAT
b. CARL_SMITH
c. BILL#_CLINTON
d. LARRY BIRD
<해설>
와일드 카드 문자에 대한 문제다. 와일드 카드 문자는 어떠한 경우에도 사용될 수 있는 문자로 트럼프로 치자면 조커가 여기에 해당된다. SQL과 DOS의 와일드 카드 문자를 비교해 보면 쉽게 이해할 수 있다.
DOS SQL
문자열 * %
단일문자 ? _(underscore)
%는 길이와는 상관 없이(0도 포함) NULL을 제외한 모든 문자열을 대변할 수 있고 _는 하나의 문자만을 대치할 수 있다.
와일드 카드 문자의 기능을 사용하고 싶지 않을 때에는 와일드 카드 문자 앞에 이스케이프 문자를 추가하면 되는데 위에서는 ESCAPE 옵션을 사용해서 직접 원하는 이스케이프 문자(#)를 지정하였다.
위 SELECT 문의 의미는 이름(name)에 ‘L_’라는 단어가 들어 있는 모든 데이터를 찾으라는 뜻이다. LIKE는 패턴 매칭에 사용되는 연산자로 문자열 검색에 매우 유용하게 쓰인다.
정답 : (b) (<- 마우스로 정답 부분을 선택하세요)
3-2. 내림 차순(Descending Order)으로 데이터를 출력할 때 NULL 값이 들어 있는 레코드는 어떤 순서로 나타나는가?
a. 정렬되지 않는다.
b. 쿼리 결과에서 제외된다.
c. 정렬된 컬럼의 맨 처음에 나타난다.
d. 정렬된 컬럼의 맨 뒷부분에 나타난다.
<해설>
내림 차순은 큰 값부터 작은 값 순서로 출력하는 것으로 먼저 NULL의 의미를 잘 이해해야 한다. NULL이란 0이나 아무것도 없는 것이 아니라 결정 되지 않은 상태를 의미한다. NULL을 0과 같이 취급하면 이 문제를 맞출 수 없다.
NULL은 수학에서의 무한대와 종종 비교되기도 하는데 의미는 다르지만 상당히 설득력 있는 비교 방법이다. 이 문제에서 NULL을 무한대라고 가정하면 정답을 찾을 수 있다.
위의 SELECT 문을 실행하면 NULL이 들어 있는 레코드가 가장 먼저 출력되고 그 다음에 나머지 데이터가 내림 차순으로 나타난다.
정답 : (c) (<- 마우스로 정답 부분을 선택하세요)
3-3. 다음 SELECT 문을 실행했을 때 출력될 수 있는 데이터는? (정답은 두 가지)
SELECT sal
FROM emp
WHERE sal < 1000 AND sal > 3000 OR sal BETWEEN 1500 AND 2500 OR sal IN (950, 4000)
a. 800
b. 1500
c. 2000
d. 3000
e. 3500
<해설>
WHERE 조건에 사용되는 연산자의 우선 순위는 이전 섹션에서 설명한 바와 같이 비교 연산자(여기서는 BETWEEN…AND…)가 논리 연산자보다 앞서고 논리 연산자는 NOT > AND > OR 의 순서로 적용된다. 따라서 WHERE 조건을 괄호를 이용해서 다시 써보면 다음과 같이 3 개의 조건문을 OR로 묶은 형태가 된다.
WHERE (sal < 1000 AND sal > 3000) OR
(sal BETWEEN 1500 AND 2500) OR
(sal IN (950, 4000))
첫 번째 라인은 논리적으로 불가능한 것이므로 항상 FALSE가 된다.
세 번째 라인에 해당되는 보기는 없다.
따라서 두 번째 라인의 조건을 만족시키는 보기만을 고르면 된다.
정답 : (b) (c) (<- 마우스로 정답 부분을 선택하세요)
3-4. 다음 SQL 문에서 에러가 발생하는 부분은?
a. SELECT e.empno, emp.ename, d.dname
b. FROM emp e, dept d
c. WHERE e.deptno = d.deptno
d. AND sal > 1500
<해설>
테이블 에일리어스(Alias)에 관한 것으로 본 섹션에 해당되는 문제는 아니지만 이 곳에서 소개하는 것이 좋을 것 같다.
FROM 절을 보면 emp 테이블은 e, dept 테이블은 d라고 에일리어스를 선언하였다. 테이블 에일리어스는 FROM 절에서 여러 개의 테이블을 사용할 때 컬럼의 이름이 중복되는 것을 방지하고 간단하게 표현하기 위해서 사용된다. 그런데 일단 테이블 에일리어스를 선언하였다면 원래의 테이블 이름 대신 반드시 테이블 에일리어스를 사용하도록 되어 있다.
따라서 SELECT 리스트의 emp.ename 부분에서 에러가 발생하며 e.ename으로 변경해주어야 한다.
정답 : (a) (<- 마우스로 정답 부분을 선택하세요)
내장함수의 종류와 단일 로우 함수
4-1. emp 테이블의 ename 컬럼은 VARCHAR2(10)으로 정의되어 있다. 다음 중에서 에러가 발생하는 SQL 문을 모두 골라라. (정답은 두 가지)
a. SELECT LENGTH(ename) FROM emp
b. SELECT NVL(ename, ‘ ’) FROM emp
c. SELECT TRUNC(ename) FROM emp
d. SELECT ROUND(ename) FROM emp
e. SELECT SUBSTR(ename, 1, 20) FROM emp
<해설>
SQL에서 제공하는 함수는 크게 그룹 함수와 단일 로우 함수(single row function)로 나눌 수 있다. 그러면 이렇게 함수를 나누는 기준은 무엇일까?
그룹 함수는 여러 레코드로부터 자료를 모아서 하나의 레코드를 만들어 내지만 단일 로우 함수는 각 레코드마다 별도의 레코드를 반환한다는 차이점이 있다.
스칼라 함수라고도 불리는 단일 로우 함수의 종류에 대한 문제도 출제된 적이 있으므로 알아두는 것이 좋다. 단일 로우 함수에는 숫자 함수, 문자 함수, 날짜 함수, 변환 함수, 기타 함수가 있으며 그 중에서 문자 함수의 개수가 가장 많다.
각 함수에는 적절한 타입의 파라미터를 넘겨주어야 하며 처리할 수 없는 타입의 파라미터가 들어오면 에러가 발생한다.
LENGTH는 문자열에 들어 있는 글자 수를 알려주는 함수인데 사용 중인 문자 집합(character set)에 따라서 동일한 파라미터라도 다른 결과가 나올 수 있다. 예를 들어 KO16KSC5601을 사용중이라면 LENGTH(‘무궁화’)의 결과는 3이 나오지만 US7ASCII를 사용한다면 6이 나오게 된다. 특히 한글과 영문이 섞여 있는 경우에는 원하는 결과를 끌어내기가 쉽지 않다. 따라서 글자 수가 아니라 정확한 바이트 수를 얻고자 한다면 LENGTH 대신 LENGTHB 함수를 사용해야 한다.
NVL은 NULL을 원하는 다른 값으로 변환하는 함수이다. 위의 보기에서는 ename 컬럼의 데이터가 NULL이라면 결과로 ‘ ‘를 반환한다. NVL은 NULL 데이터 처리를 위해서 즐겨 사용되지만 습관적으로 사용하는 것은 바람직하지 않다.
TRUNC와 ROUND는 숫자와 날짜는 지원하지만 문자열에는 사용할 수 없다. 각각은 내림과 반올림 기능을 하는데 숫자일 때에는 지정한 소수점 위치로 내림과 반올림을 하고 날짜일 때에는 지정한 포맷 모델(년, 월, 일 등)에 따라 내림과 반올림을 수행한다.
SUBSTR은 주어진 문자열의 일부분을 추출하는 함수로 역시 문자집합에 따라서 다른 결과가 나타나므로 대신 SUBSTRB 함수가 사용되기도 한다.
정답 : (c) (d) (<- 마우스로 정답 부분을 선택하세요)
4-2. 다음 중에서 결과가 DATE 타입인 것은? (정답은 두 가지)
a. SYSDATE + 1
b. SYSDATE + TO_DATE(’01-JAN-90’, ‘DD-MON-YY’)
c. ROUND(SYSDATE)
d. MONTHS_BETWEEN(SYSDATE, TO_DATE(’01-NOV-01’, ‘DD-MON-RR’))
<해설>
날짜에 숫자를 더하거나 뺄 때에는 숫자의 기본 단위는 날(Day)로 처리된다. 따라서 SYSDATE + 1 은 내일 이 시간, SYSDATE – 1은 어제 이 시간을 뜻한다. 만약 지금부터 한 시간 후를 표현하려면 SYSDATE + 1/24 라고 하면 된다.
날짜와 날짜를 더하는 연산은 그 의미나 결과가 모호한 관계로 지원되지 않는다. (b)의 SQL문을 실행하면 ORA-975 에러가 발생한다.
MONTHS_BETWEEN는 두 날짜 사이의 기간을 개월 단위로 알려주는 함수이다.
정답 : (a) (c) (<- 마우스로 정답 부분을 선택하세요)
4-3. 다음 SELECT문을 실행했을 때 어떤 결과가 나오는가?
SELECT TRUNC(TO_DATE(’05-APR-01’, ‘DD-MON-RR’), ‘MONTH’)
FROM dual
a. 30-APR-01
b. 01-APR-01
c. 01-MAY-01
d. 01-JAN-01
e. 31-DEC-01
<해설>
TRUNC 함수에서 포맷 모델로 MONTH를 사용했으므로 그 달의 가장 첫 번째 날을 반환하게 된다. 주어진 날짜가 2001년 4월 5일이므로 그 달의 첫 번째 날인 2001년 4월 1일이 정답이다.
만약 포맷 모델을 지정하지 않고 그냥 TRUNC(SYSDATE)와 같이 사용한다면 날짜 타입의 시간:분 파트가 00:00으로 리셋되는 효과만 발생한다. 따라서 날짜 타입에 들어 있는 시간:분 파트가 서로 달라서 비교가 되지 않는 문제를 해결할 때 사용할 수 있다. 이 것은 TRUNC(SYSDATE,’DD’)라고 지정한 것과 같은 의미인데 실수로 TRUNC(SYSDATE, ‘DAY’)라고 하면 그 주(Week)의 첫 번째 날을 뜻하게 되므로 주의해야 한다.
4-4. SELECT 문에서 단일 로우 함수를 사용할 수 없는 곳은?
a. SELECT 리스트
b. WHERE 절
c. START WITH 절
d. CONNECT BY 절
e. ORDER BY 절
f. 보기에 없음
<해설>
오라클 7.0에서는 SELECT 리스트에 단일 로우 함수를 사용하는 기능이 지원되지 않아서 불편한 점이 많았다. 그래서 오라클 7.1 버전이라면 한 문장으로 처리할 일도 여러 개의 SQL문으로 나누어야 하는 어려움이 있었다.
이제 웬만한 곳에는 대부분 단일 로우 함수를 사용할 수 있다.
정답 : (f) (<- 마우스로 정답 부분을 선택하세요)
4-5. 다음 함수 또는 연산의 결과가 NULL인 것은?
a. CONCAT(‘DALLAS’, NULL)
b. REPLACE(‘NEW YORK’, ‘YORK’, NULL)
c. DUMP(NULL || NULL)
d. ‘COUNTRY’ || NULL
e. NVL(0, NULL)
<해설>
모든 단일 로우 함수는 NULL 파라미터가 들어오면 자동으로 NULL을 반환하도록 되어 있다. 단 다음 4개의 함수들은 예외적으로 이 규칙을 따르지 않는다.
CONCAT, NVL, REPLACE, DUMP
물론 이 함수들의 결과도 NULL이 나올 수 있지만 NULL 파라미터에 대해서 무조건적으로 NULL을 반환하지 않고 주어진 연산을 수행한다.
CONCAT은 두 개의 파라미터를 받아서 || 연산을 하는 함수이므로 (a)의 결과는 ‘DALLAS’이다.
REPLACE는 첫 번째 파라미터 문자열에서 두 번째 파라미터의 패턴을 찾은 다음 세 번째 파라미터로 대치한다. 따라서 (b)의 결과는 ‘NEW ‘가 된다.
DUMP는 주어진 파라미터의 데이터 타입 코드와 길이, 그리고 내부적으로 어떻게 이루어져 있는지를 8진수, 10진수, 16진수 등의 형태로 출력해 준다. 많은 데이터를 입력하다 보면 눈에 보이지 컨트롤 문자가 잘못 들어가는 경우가 있는데 이 때 DUMP 함수를 사용하면 문제의 데이터를 확인할 수 있다. 이외에도 DUMP 함수는 다양한 용도로 사용된다.
정답 : (c) (<- 마우스로 정답 부분을 선택하세요)
JOIN
5-1. self join에 해당되는 SQL 문은?
a. SELECT e.ename, d.dname
FROM emp e, dept d
WHERE e.deptno = d.deptno
b. SELECT e.ename, d.dname
FROM emp.e, dept d
WHERE e.deptno(+) = d.deptno
c. SELECT e1.ename, e2.ename
FROM emp e1, emp e2
WHERE e1.mgr = e2.empno
d. SELECT e.ename, d.dname
FROM emp e, dept d
WHERE e.deptno != d.deptno
<해설>
조인이 없다면 관계형 데이터베이스는 존재할 수 없었을 만큼 관계형 데이터베이스에서 조인이 차지하는 비중은 절대적이다. 이 섹션에서는 조인에 관한 가장 기본적인 사항을 다루도록 하겠다.
self join은 한 테이블 내의 컬럼끼리 조인하는 것을 말한다. 그렇다면 왜 그런 작업이 필요할까?
(c)의 emp 테이블을 예로 들어 보면 empno 컬럼에는 직원의 직원 번호가 들어있고 mgr 컬럼에는 그 직원 상사의 관리자 번호가 들어있다. 그런데 관리자 번호 또한 직원 번호에 해당되기 때문에 이 둘을 조인하면 각 직원의 관리자 레코드를 찾을 수 있는 것이다.
정답 : (c) (<- 마우스로 정답 부분을 선택하세요)
5-2. equality join을 설명한 것으로 옳은 것은?
a. 한 개의 테이블만 사용할 수 있다.
b. 두 개의 테이블만 사용할 수 있다.
c. 두 개 이상의 테이블을 사용할 수 있다.
d. SELECT 리스트에 있는 컬럼만을 조인하여 비교할 수 있다.
<해설>
equality join은 줄여서 equi-join 이라고도 하는데 = 기호를 이용해서 컬럼을 비교하는 것을 말한다.
equality join은 한 개의 테이블을 사용하는 self join을 비롯해서 두 개 또는 그 이상의 테이블을 가지고 조건을 지정할 수 있다. 일반적으로 FROM 절에 n 개의 테이블이 존재한다면 WHERE 절에서는 n-1 개의 조인 조건을 지정하게 된다.
그리고 조인에 사용되는 컬럼이 꼭 SELECT 리스트에 있을 필요는 없다.
정답 : (c) (<- 마우스로 정답 부분을 선택하세요)
5-3. outer join을 설명한 것으로 옳은 것은?
a. (+) 기호는 일치하는 레코드가 부족한 쪽에 표기한다.
b. simple join(equi-join)의 결과를 축소한 것이다.
c. 두 테이블의 모든 레코드를 가져오고자 할 때 사용한다.
d. 한 테이블의 모든 레코드를 가져오고자 할 때 사용한다.
<해설>
outer join은 simple join의 결과에 덧붙여서 추가적으로 한 테이블로부터 상대편 테이블과 일치하는 데이터가 없는 나머지 레코드를 가져오기 위해서 사용된다.
outer join의 결과는 항상 simple join의 결과를 포함하므로 simple join의 결과는 outer join 결과의 부분 집합에 해당된다.
정답 : (a) (<- 마우스로 정답 부분을 선택하세요)
5-4. emp, dept 테이블에는 아래와 같은 데이터가 들어 있다.
(emp 테이블)
ENAME DEPTNO
SMITH 20
ALLEN 30
WARD 30
JONES 20
MARTIN 30
BLAKE 30
CLARK 10
SCOTT 20
KING 10
TURNER 30
ADAMS 20
JAMES 30
FORD 20
MILLER 10
(dept 테이블)
DEPTNO DNAME LOC
10 ACCOUNTING NEW YORK
20 RESEARCH DALLAS
30 SALES CHICAGO
40 OPERATIONS BOSTON
다음 SELECT 문을 실행했을 때 출력되는 레코드의 개수는?
SELECT e.ename, d.dname
FROM emp e, dept d
WHERE e.deptno(+) = d.deptno
a. 4
b. 14
c. 15
d. 64
<해설>
dept 테이블에는 4개의 부서가 있지만 emp 테이블에서는 3개의 부서만 사용하고 있다. 따라서 emp 테이블에 있는 14 건의 레코드에 대한 결과가 출력된 다음에 마지막으로 emp 테이블에서 사용하지 않는 dept 테이블의 dname(deptno=40)이 하나 더 출력된다. 이 때 deptno=40에 해당되는 ename 값은 없으므로 ename은 NULL로 나타난다.
정답 : (c) (<- 마우스로 정답 부분을 선택하세요)
5-5. outer join 조건식에서 사용할 수 없는 연산자는? (정답은 두 가지)
a. AND
b. OR
c. =
d. IN
<해설>
outer join을 쓸 때에는 기본적으로 = 과 AND 연산자를 사용하며 OR나 IN 연산자를 사용하면 ORA-1719 에러가 발생한다.
정답 : (b) (d) (<- 마우스로 정답 부분을 선택하세요)
GOUP 함수
-1. 다음 SQL문에서 에러가 발생하는 곳은?
a. SELECT deptno, AVG(sal)
b. FROM emp
c. WHERE AVG(sal) < 3000
d. HAVING deptno > 0
e. GROUP BY deptno
<해설>
그룹 함수는 AVG(평균), MAX(최대값), SUM(합계) 등과 같이 여러 개의 레코드로부터 하나의 결과를 도출해 내는 함수이다.
그룹 함수는 그 특성상 GROUP BY 절과 함께 사용되는 경우가 많으며 만약 GROUP BY 절을 지정하지 않으면 주어진 전체 레코드를 대상으로 작업을 한다..
위의 SQL문을 작성한 사용자의 의도를 추정해보면 평균 연봉이 3000만원 이하인 부서를 대상으로 해서 각 부서의 부서 번호와 평균 급여를 보려는 것으로 파악된다.
그러나 WHERE 절에는 단일 로우 함수는 사용할 수 있지만 그룹 함수는 사용할 수 없다는 제약이 있기 때문에 이 문장을 실행하면 ORA-934 에러가 발생한다. 그렇다면 원하는 결과를 얻기 위해서 어떻게 수정해야 할까?
GROUP BY에 의한 결과를 필터링 할 때에는 WHERE 대신 HAVING 절을 사용해야 한다. HAVING과 GROUP BY는 어느 것을 먼저 써도 상관없지만 보통 HAVING을 뒤에 쓰는 것이 관례이다. 위의 문제에서는 혼란을 주기 위해서 의도적으로 HAVING을 앞에 두었다.
HAVING 절에서 무의미한 deptno > 0 를 제거하고 AVG(sal) < 3000 과 같이 조건을 추가하면 원하는 결과를 구할 수 있다.
참고로 WHERE sal < 3000 이라고 하면 급여가 3000 미만인 직원의 레코드를 먼저 배제시키기 때문에 GROUP 함수의 결과에는 반영되지 않는다. 즉, WHERE 조건에서 일차적으로 데이터를 걸러낸 다음에 GROUP BY에 의한 작업이 수행되고 마지막으로 HAVING 절을 통해서 한번 더 걸러지게 된다.
정답 : (c) (<- 마우스로 정답 부분을 선택하세요)
6-2. emp 테이블의 sal 컬럼에 다음과 같은 데이터가 들어 있다.
1000
2000
3000
1000
2000
4000
다음 SQL문을 실행했을 때 출력되는 결과는?
SELECT AVG(DISTINCT sal)
FROM emp
a. 1000
b. 2000
c. 2500
d. 3000
e. 4000
<해설>
그룹 함수에도 DISTINCT와 ALL 옵션을 사용할 수 있다.
ALL은 디폴트 옵션으로 데이터를 있는 그대로 처리하며 실제 코딩에서 명시하는 경우는 드물다.
DISTINCT 옵션을 지정하면 중복된 데이터는 계산에서 제외시킨다. 현재 sal 컬럼에는 6건의 레코드가 들어 있는데 중복된 2건을 제외하면 1000,2000,3000,4000 의 4건의 레코드로 압축된다. 따라서 결과는 (1000 + 2000 + 3000 + 4000) / 4 = 2500이 된다.
만약 ALL 옵션을 사용했다면 결과는 (1000 + 2000 + 3000 + 1000 + 2000 + 4000) / 6 = 2166.6667 이 된다.
정답 : (c) (<- 마우스로 정답 부분을 선택하세요)
6-3. 다음 그룹 함수 중에서 NULL 값을 무시하지 않고 처리하는 함수는?
a. COUNT(*)
b. SUM
c. AVG
d. MAX
e. STDDEV
<해설>
COUNT(*)를 제외한 모든 그룹 함수에서 NULL 데이터는 무시된다. COUNT 함수의 경우에도 COUNT(*)가 아니라 COUNT(컬럼명)과 같이 쓰면 NULL을 처리하지 않는다. 모든 컬럼이 NULL인 레코드는 있을 수 없다는 것을 생각해보면 COUNT(*)를 사용했을 때 모든 레코드에는 NULL이 아닌 컬럼이 반드시 하나 이상 존재하므로 그 레코드를 카운트 하는 것은 당연함을 알 수 있다.
NULL과 관련된 문제는 언제 어디서나 단골로 출제되므로 각별히 신경 쓰기 바란다.
정답 : (a) (<- 마우스로 정답 부분을 선택하세요)
6-4. 다음은 GROUP BY를 이용한 SQL문과 실행 결과이다.
SELECT d.dname, AVG(e.sal)
FROM emp e, dept d
WHERE e.deptno(+) = d.deptno
GROUP BY d.dname
DNAME AVG(E.SAL)
ACCOUNTING
2916.66667
OPERATIONS
RESEARCH
2175
SALES
1566.66667
이 SQL문에 다음과 같은 ORDER BY 절을 추가하려고 한다. 보기 중에서 옳은 것을 골라라.
ORDER BY d.dname DESC
a. GROUP BY를 쓰면 기본적으로 오름 차순으로 정렬된다.
b. ORDER BY 절에서 내림 차순으로 정렬하라고 되어있지만 GROUP BY가 우선하므로 결과는 오름 차순으로 나타난다.
c. ORDER BY절과 GROUP BY 절을 동시에 쓸 수 없으므로 에러가 발생한다.
d. ORDER BY절은 WHERE 절과 GROUP BY 절 사이에 써야 한다.
<해설>
GROUP BY 및 ORDER BY와 관련해서 몇 가지 중요한 단편적인 사항을 모아보았다.
ORDER BY와 마찬가지로 GROUP BY절에서도 기본적으로 오름 차순으로 정렬된다.
정렬할 때에는 ORDER BY가 GROUP BY를 오버라이드(override, 의미를 살리기 위해서 영문 그대로 씀) 하기 때문에 ORDER BY와 GROUP BY의 정렬 순서가 다르다면 ORDER BY에 지정한 순서로 나타난다. 따라서 이 SQL 문에서는 내림 차순으로 표시된다.
ORDER BY와 GROUP BY는 당연히 함께 사용할 수 있으며 ORDER BY는 GROUP BY 보다 뒤쪽에 표기해야 한다.
참고로 GROUP BY에는 컬럼 에일리어스를 쓸 수 없지만 ORDER BY에는 쓸 수 있다는 점도 알아두면 좋겠다.
정답 : (a) (<- 마우스로 정답 부분을 선택하세요)
서브쿼리
7-1. 다음 SQL 문에서 에러가 발생하는 곳은?
a. SELECT ename
b. FROM emp
c. WHERE deptno =
d. (SELECT deptno FROM emp WHERE sal > 1000)
<해설>
한 SQL 명령 안에 SELECT 문이 포함되어 있을 때 이 SELECT 문을 가리켜 서브쿼리라고 부른다. 서브쿼리에는 하나의 값만을 반환하는 서브쿼리(single row subquery), 여러 개의 값을 반환하는 서브쿼리(multiple value subquery), 서브쿼리를 포함하고 있는 부모 SQL문에 속한 테이블을 참조하는 상관형 서브쿼리(correlated subquery) 등이 있다.
서브쿼리는 부모 SQL 문 없이는 존재할 수 없기 때문에 일명 캥거루 쿼리라고도 불린다. 다만 캥거루하고 다른 점이라면 캥거루 주머니 속의 새끼 캥거루가 또 다른 새끼 캥거루를 품을 수는 없지만 서브쿼리에서는 가능하다는 것이다. 즉, 서브쿼리는 다른 서브쿼리를 중첩해서 포함할 수도 있다. 이와 같이 서브쿼리 내에 또 다른 서브쿼리가 있는 경우를 가리켜 중첩 서브쿼리(nested subquery)라고 한다.
위의 문제는 단일 로우 서브쿼리에 대한 것이다. WHERE 조건에서 = 연산자를 사용하였고 서브쿼리 내에서 부모 쿼리를 참조하지 않기 때문에 단일 로우 서브쿼리를 만들려고 한 것임을 알 수 있는데 단일 로우 서브쿼리는 여러 개의 레코드를 반환하면 에러가 발생할 수 밖에 없다. 따라서 서브쿼리에서 = 연산자나 ROWNUM 등을 사용해서 하나의 레코드만을 반환하도록 변경해야 한다.
정답 : (d) (<- 마우스로 정답 부분을 선택하세요)
7-2. emp 테이블에 다음과 같은 데이터가 들어 있다.
EMPNO ENAME DEPTNO SAL
7369 SMITH 20 800
7499 ALLEN 30 1600
7521 WARD 30 1250
7566 JONES 20 2975
7654 MARTIN 30 1250
7698 BLAKE 30 2850
7782 CLARK 10 2450
7788 SCOTT 20 3000
7839 KING 10 5000
7844 TURNER 30 1500
7876 ADAMS 20 1100
7900 JAMES 30 950
7902 FORD 20 3000
7934 MILLER 10 1300
[/pre]
아래의 SQL문 중에서 에러가 발생하는 것을 골라라.
a. SELECT ename, sal FROM emp e
WHERE sal < ( SELECT AVG(sal) FROM emp
WHERE e.deptno = deptno)
b. SELECT ename FROM emp
WHERE deptno = (SELECT deptno FROM emp
WHERE sal > 1000)
c. SELECT ename FROM emp
WHERE deptno NOT IN (SELECT deptno FROM emp
WHERE empno < 7000)
d. SELECT ename FROM emp
WHERE deptno = (SELECT deptno FROM emp
WHERE empno = 7900)
<해설>
(a)는 상관형 서브쿼리(correlated subquery)이다. 상관형 서브쿼리는 부모 테이블을 참조하므로 부모 테이블을 선언할 때 반드시 에일리어스를 만들어 주어야 한다. 상관형 서브쿼리의 특징은 부모 테이블의 각 레코드에 대해서 서브쿼리가 매번 수행된다는 점이다. 따라서 데이터가 많을 경우 그 만큼 시스템에 큰 부하가 걸리게 되므로 유의해야 한다.
(b)는 앞의 문제와 같은 내용이므로 설명은 생략하기로 한다.
(c)의 서브쿼리는 여러 개의 결과 값을 반환하지만 NOT IN 연산자를 이용하기 때문에 정상적으로 수행된다. 이와 같이 다중 값 서브쿼리(multiple value subquery)를 처리할 때에는 NOT IN 또는 IN, EXISTS 등의 연산자를 사용할 수 있다.
(d)의 서브쿼리는 한 개의 결과만을 반환하므로 정상적으로 실행된다.
정답 : (b) (<- 마우스로 정답 부분을 선택하세요)
7-3. 서브쿼리에 대한 설명으로 옳은 것은?
a. SELECT 문에만 사용할 수 있다.
b. 중첩시키는 깊이에는 제한이 없다.
c. 반드시 하나의 값만을 반환해야 한다.
d. 부모 쿼리와 연관되어서는 안 된다.
e. WHERE 절에 서브쿼리를 사용한 경우를 인라인 뷰(inline view)라고 부른다.
f. 없 음
<해설>
서브쿼리는 SELECT 뿐 아니라 UPDATE, DELETE 등에서도 사용할 수 있기 때문에 (a)는 정답이 아니다.
서브쿼리의 중첩 레벨에는 일부 제약이 있다. 최상위의 FROM 절에서 사용되는 서브쿼리의 중첩 레벨에는 아무런 제한이 없지만(이론상) WHERE 절에서는 최대 255단계까지 가능하다. 따라서 (b)도 정답이 될 수 없다.
서브쿼리에는 하나의 값만을 반환하는 것(single row subquery) 외에도 여러 개의 값을 반환하는 것도 있다(multiple value subquery). 그러므로 (c)도 틀린 답이다.
상관형 서브쿼리는 부모 쿼리와 연결되어 동작하므로 (d)도 정답이 아니다.
인라인 뷰는 FROM 절에서 테이블이나 뷰 대신 사용되는 것으로 뷰를 별도로 만들지 않고 직접 FROM 절에 기술한 것이다. CREATE VIEW 명령으로 뷰를 만들어서 사용할 때 보다 약간의 성능 향상을 꾀할 수 있고 실제로 써보면 매우 편리하기 때문에 중독성이 강한 기능이다.
정답 : (f) (<- 마우스로 정답 부분을 선택하세요)
7-4. 다음 SQL 문에서 에러가 발생하는 곳은?
a. SELECT ename FROM emp
b. WHERE deptno =
c. (SELECT deptno FROM dept
d. WHERE dname IN (‘RESEARCH’, ‘SALES’)
e. ORDER BY deptno)
<해설>
WHERE 조건의 서브쿼리에서 ORDER BY 절을 사용할 수 없다는 것은 워낙 많이 알려졌기 때문에 이제 모르는 사람은 없을 것이다. 서브쿼리에서 여러 개의 값을 반환하더라도 그 순서가 아무런 의미를 갖지 못하므로 ORDER BY를 허용할 필요가 없음을 알 수 있다. 반면 FROM 절에 사용되는 서브쿼리에서는 ORDER BY를 지원한다.
정답 : (e) (<- 마우스로 정답 부분을 선택하세요)
SQL*Plus 의 활용법
8-1. SQL*Plus에서 다음 명령을 실행했을 때 에러가 발생하는 곳은?
a. ACCEPT vempno NUMBER PROMPT ‘Enter Employee Number : ‘
b. SELECT ename, sal
c. FROM emp
d. WHERE empno = vempno;
<해설>
SQL*Plus는 SQL 명령을 실행할 수 있는 가장 기본적인 프로그램으로 오라클을 사용하면서 항상 가까이 하게 되는 프로그램이기도 하다.
SQL*Plus를 사용하면 못하는 작업이 없으나 복잡한 SQL 명령을 외워야 한다는 번거로움이 있다. 그래서 OEM과 같은 GUI 도구들이 많이 나와 있지만 여전히 편리한 GUI 도구를 거부하고 SQL*Plus로 모든 작업을 처리하는 사람들도 많다. 마치 윈도우 환경에서도 도스 프롬프트가 사랑 받는 것과 비슷하다고 할 수 있다.
SQL*Plus는 별도의 매뉴얼까지 나와있을 정도로 지원하는 옵션이 다양하기 때문에 본 강좌에서 제공하는 문제 만으로는 그 기능을 모두 섭렵하기가 불가능하므로 꼭 매뉴얼을 참조하기 바란다.
SQL*Plus와 비슷한 프로그램으로 서버 매니저가 있다. SQL*Plus는 오라클 초창기부터 꾸준히 명맥을 이어오고 있지만 SQL*DBA를 대체하면서 등장했던 서버 매니저는 이제 오래지 않아 다시 사라질 예정이라고 한다. 앞으로는 SQL*Plus가 서버 매니저의 기능을 대신하게 되므로 그 중요성이 한 층 배가되었다.
여기서는 SQL*Plus에서 가장 중요한 분야인 변수에 대해서 알아보자. SQL*Plus에서 사용할 수 있는 변수에는 크게 3 가지가 있다.
1) 시스템 변수(system variable)
2) 사용자 변수(user variable)
3) 바인드 변수(bind variable)
시스템 변수는 SQL*Plus의 각종 환경을 설정할 때 사용되는 것으로 예를 들면 페이지 당 라인수, 숫자 컬럼의 폭, 컬럼 헤더의 출력 여부 등을 SET 명령을 이용해서 지정할 수 있으며 변수 값을 확인할 때에는 “SHOW 변수 이름” 명령을 사용한다.
사용자 변수는 SQL 문에서 반복적으로 사용하기 위해서 만드는 변수이다. DEFINE 명령을 이용하면 문자열 변수만을 만들 수 있고 숫자나 문자, 날짜 타입의 변수를 만들기 위해서는 ACCEPT 명령을 써야 한다. 사용자 변수를 SQL 문에서 사용할 때에는 앞에 & 또는 && 기호를 붙여서 표시하는데 이를 가리켜 대체 변수(substitution variable)라고 부른다. 변수 값은 “DEFINE 변수 이름” 명령으로 확인할 수 있으며 그냥 “DEFINE” 이라고 실행하면 모든 사용자 변수에 대한 내용이 출력된다.
바인드 변수는 SQL*Plus와 PL/SQL 프로그램 간의 데이터 교환을 위해서 사용되는 것으로 VARIABLE 명령을 사용해서 만들며 변수 이름 앞에 : 기호를 붙여서 표시한다. 변수 값을 확인할 때에는 “PRINT 변수 이름” 명령을 이용한다.
이 문제에서는 ACCEPT 명령을 사용해서 vempno 라는 사용자 변수를 선언하였다. PROMPT 명령을 함께 사용했으므로 키보드로부터 vempno 값을 입력 받는다.
그런데 사용자 변수를 사용하는 WHERE 절에서 변수 앞에 & 기호를 붙이지 않았기 때문에 에러가 발생한다. 변수 앞에 & 기호가 없으므로 vempno를 변수가 아닌 컬럼 명으로 인식하게 되고 vempno라는 컬럼이 없으므로 결과적으로 에러 처리되는 것이다. 참고로 ACCEPT 명령으로 vempno를 선언하지 않고 바로 SQL 문에서 사용하면 &vempno 변수를 만났을 때 사용자로부터 키 입력을 받게 된다.
정답 : (d) (<- 마우스로 정답 부분을 선택하세요)
8-2. 다음 문장을 실행하면 컬럼 헤더는 어떻게 나타나는가?
SELECT e.ename, d.dname “Department”
FROM emp e, dept d
WHERE e.deptno = d.deptno
a. e.ename d.dname
b. ename “Department”
c. E.ENAME Department
d. ENAME Department
e. ENAME DEPARTMENT
<해설>
오라클에서는 각종 키워드나 객체 이름에서 대소문자를 구분하지 않는다. 만약 명시적으로 소문자를 사용하고 싶다면 쌍 따옴표(“)를 사용해야 한다.
위에서는 컬럼 에일리어스로 “Department”라고 지정했으므로 컬럼 헤더도 Department라고 표시된다. 만약 쌍 따옴표를 빼고 Department라고만 했다면 DEPARTMENT로 표시될 것이다.
정답 : (d) (<- 마우스로 정답 부분을 선택하세요)
8-3. dept 테이블에 다음과 같은 데이터가 들어있다.
DEPTNO DNAME LOC
10 ACCOUNTING NEW YORK
20 RESEARCH DALLAS
30 SALES CHICAGO
40 OPERATIONS BOSTON
아래의 SQL 문을 실행하면 deptno 값을 두 번 물어보는데 처음에는 10을 입력하고 두 번째는 20을 입력하였다면 결과로 몇 개의 레코드가 출력되는가?
SELECT dname
FROM dept
WHERE deptno = &deptno OR deptno = &deptno
a. 0
b. 1
c. 2
d. 3
e. 4
<해설>
대체 변수(substitution variable)에 관한 문제다. &deptno와 같이 미리 정의되지 않은 변수를 SQL 문에서 사용하면 사용자로부터 키 입력을 받아서 변수와 대체하게 된다. 이 변수가 SQL 문에서 사용될 때 마다 매번 키 입력을 받는데 처음에는 10, 두 번째는 20을 입력하였다면 WHERE 조건은 다음과 같이 완성된다.
WHERE deptno = 10 OR deptno = 20
잘못 생각하면 두 개의 &deptno가 10 또는 20 중의 하나로 통일될 것이라고 착각하기 쉽다. 만약 &deptno 대신 &&deptno라고 지정했다면 &&deptno에 처음 값을 입력할 때 DEPTNO라는 이름의 변수가 정의되기 때문에 그 이후부터는 &deptno나 &&deptno를 만나더라도 변수 값을 물어보지 않는다. “DEFINE DEPTNO” 명령을 실행해보면 DEPTNO 라는 사용자 변수가 생성되어 있음을 확인할 수 있다.
정답 : (c) (<- 마우스로 정답 부분을 선택하세요)
8-4. SQL*Plus에서 SET AUTOCOMMIT ON 명령의 의미는?
a. SQL*Plus를 종료할 때 자동으로 커밋한다.
b. SQL*Plus가 비정상적으로 종료되어도 자동으로 커밋한다.
c. SQL문을 실행할 때 마다 자동으로 커밋한다.
d. 시스템 상태에 따라서 오라클이 커밋 시점을 자동으로 결정한다.
<해설>
SET AUTOCOMMIT ON이란 INSERT, UPDATE, DELETE 등과 같은 SQL 문을 실행할 때 마다 자동으로 커밋한다는 뜻이다. 디폴트는 물론 OFF 이다.
SQL*Plus에서 작업을 하다가 커밋하지 않은 상태에서 EXIT로 빠져나간다면 작업 내용은 자동으로 커밋되지만 SQL*Plus 프로세스를 KILL 시키면 작업 내용은 롤백된다.
정답 : (c) (<- 마우스로 정답 부분을 선택하세요)
일반적인 데이터처리
9-1. DML에 해당되지 않는 것은? (정답은 네 가지)
a. DELETE
b. CREATE TABLE
c. SELECT
d. LOCK TABLE
e. TRUNCATE
f. UPDATE
g. EXPLAIN PLAN
h. INSERT
i. RENAME
j. GRANT
<해설>
SQL 명령은 크게 다음의 3가지로 분류된다.
1) DCL(Data Control Language) – GRANT, REVOKE 등
2) DML(Data Manipulation Language) – SELECT, UPDATE, DELETE 등
3) DDL(Data Definition Language) – CREATE TABLE, DROP TABLE 등
여기에 TCO(Transaction Control Operations)를 추가하면 4가지가 된다.
DML은 데이터를 처리하는 명령으로 SELECT, UPDATE, DELETE, INSERT, EXPLAIN PLAN, LOCK TABLE 이상 6개 밖에 되지 않으므로 암기해 두는 것이 좋다. 특히 SQL 명령의 실행 계획을 보기위해서 사용하는 EXPLAIN PLAN과 테이블에 락을 거는 LOCK TABLE 명령도 DML임을 기억해야 한다.
TCO는 트랜잭션 처리와 관련된 명령으로 COMMIT, ROLLBACK, SAVEPOINT 등이 있다.
정답 : (b) (e) (i) (j) (<- 마우스로 정답 부분을 선택하세요)
9-2. 다음과 같은 일련의 작업을 수행할 때 에러가 발생하는 위치는? 단, dept 테이블에는 아무런 제약 조건이 설정되어 있지 않다고 가정한다.
a. SAVEPOINT A;
b. INSERT INTO dept VALUES (50, ‘HR’, ‘BOSTON’);
c. SAVEPOINT B;
d. TRUNCATE TABLE bonus;
e. DELETE dept WHERE ROWNUM=1;
f. ROLLBACK TO SAVEPOINT A;
g. INSERT INTO dept VALUES(50, ‘HR’, ‘NEW YORK’);
<해설>
SAVEPOINT란 작업 중간 중간에 설치하여 원한다면 다시 그 시점으로 트랜잭션을 돌려놓기 위한 방편으로 일종의 책갈피에 해당된다. 그런데 SAVEPOINT는 트랜잭션이 종료되면 모두 없어지므로 (d)의 TRUNCATE 문에 의해서 SAVEPOINT A, B는 효력을 잃게 된다. 따라서 (f)에서 존재하지 않는 SAVEPOINT A를 사용하려고 하기 때문에 에러가 발생한다.
정답 : (f) (<- 마우스로 정답 부분을 선택하세요)
9-3. salgrade 테이블의 모든 레코드를 삭제하는 명령으로 옳은 것은? (정답은 두 가지)
a. DELETE salgrade;
b. DELETE * salgrade;
c. DELETE * FROM salgrade;
d. TRUNCATE TABLE salgrade;
e. TRUNCATE salgrade;
<해설>
테이블의 내용을 모두 삭제할 때에는 DELETE와 TRUNCATE TABLE 명령을 사용할 수 있다. TRUNCATE는 테이블이나 클러스터의 데이터를 모두 삭제할 때 사용되는 DDL로 롤백 세그먼트를 사용하지 않기 때문에 속도가 매우 빠르다는 장점이 있다. 데이터가 많은 경우에는 DELETE와 TRUNCATE 명령의 속도 차이가 극명하게 드러나지만 TRUNCATE는 한번 실행한 후에는 다시 돌이킬 수 없음을 잊어서는 안 된다.
정답 : (a) (d) (<- 마우스로 정답 부분을 선택하세요)
9-4. 다음 중에서 옳게 기술된 SQL문은?
a. INSERT INTO temp_bonus AS SELECT * FROM bonus
b. UPDATE bonus SET comm := 500 WHERE ename = ‘SMITH’
c. INSERT INTO bonus VALUES('SMITH', NULL, 3000, NULL)
d. COMMIT TO SAVEPOINT SP1;
<해설>
(a)의 INSERT 문은 서브쿼리를 사용해서 bonus 테이블의 데이터를 temp_bonus 테이블로 복사하는 것이다. 그런데 CREATE TABLE AS SELECT … 명령에서는 AS를 사용하지만 INSERT 문에서는 AS를 사용하지 않는다.
(b)의 UPDATE 문에서는 SET comm := 500 부분에 오류가 있다. UPDATE에서 SET으로 새로운 값을 할당할 때에는 := 대신 = 기호를 사용해야 한다.
ROLLBACK TO SAVEPOINT란 명령은 있지만 COMMIT TO SAVEPOINT 명령은 존재하지 않는다. 따라서 (d)도 잘못된 문장이다.
정답 : (c) (<- 마우스로 정답 부분을 선택하세요)
테이블의 생성과 관리
10-1. 다음 중에서 테이블 이름에 들어갈 수 있는 문자는? (정답은 세 가지)
a. %
b. $
c. _(underscore)
d. @
e. #
f. ?
<해설>
테이블을 비롯한 객체의 이름을 결정할 때에 반드시 지켜야 할 규칙(naming convention)이 있는데 중요한 것을 몇 가지 들면 다음과 같다.
1) 대소문자를 구별하지 않는다.
2) 첫 글자는 반드시 사용중인 문자 집합에서 지원하는 알파벳이어야 한다.
3) _, $, # 을 제외한 특수 기호를 사용할 수 없다.
4) 최대 길이는 30자로 제한된다(한글은 15자). 단, 데이터베이스와 데이터베이스 링크는 예외적으로 각각 8자, 128자.
이전에도 얘기했듯이 쌍 따옴표를 사용하면 위의 제약 조건 중에서 4)를 제외한 나머지는 적용되지 않는다. 하지만 가급적 기본 규칙을 지켜주는 편이 문제의 소지가 적을 것이다.
테이블과 인덱스 등은 서로의 이름 공간(name space)이 다르기 때문에 동일한 이름을 갖는 것이 허용된다. 그러나 서로 다른 성격의 객체라고 하더라도 이름이 같으면 혼란스러울 수 있으므로 적절한 접두어를 사용해서 구분하는 것이 바람직하다.
참고로 문자 집합이 US7ASCII 상태라고 하더라도 쌍 따옴표를 사용하면 테이블 이름을 얼마든지 한글로 만들 수 있다.
정답 : (b) (c) (e) (<- 마우스로 정답 부분을 선택하세요)
10-2. dept 테이블을 복사해서 dept_new라는 새로운 테이블을 만들려고 한다. 다음 설명 중에서 옳은 것은? (정답은 두 가지)
a. SQL*Plus의 COPY 명령을 사용해서 작업할 수 있다.
b. CREATE TABLE dept_new AS SELECT * from dept 명령을 사용하면 된다.
c. (b)의 명령을 사용하면 dept 테이블에 걸려 있던 모든 제약 조건까지 복사된다.
d. (b)의 명령을 사용하면 dept 테이블에 걸려 있던 모든 인덱스도 복사된다.
e. (b)의 명령에서 dept_new 테이블의 컬럼 타입을 변경할 수도 있다.
<해설>
테이블을 복사할 때에는 SQL*Plus의 COPY 명령이나 CREATE TABLE … AS SELECT 명령을 이용한다. COPY는 복사를 위한 전문 명령답게 LONG 컬럼을 가지고 있는 테이블도 복사할 수 있는 등 좀 더 다양한 기능을 가지고 있다.
CREATE TABLE … AS SELECT 명령으로 테이블을 복사하면 제약 조건은 NOT NULL만 복사되며 PRIMARY KEY, FOREIGN KEY 등과 같은 다른 제약 조건은 복사되지 않으므로 별도로 생성해 주어야 한다. 또한 기존의 테이블에 걸려 있는 인덱스도 복사되지 않으며 복사하면서 컬럼 타입이나 크기를 변경할 수도 없다.
정답 : (a) (b) (<- 마우스로 정답 부분을 선택하세요)
10-3. 다음과 같이 테이블을 만들려고 했을 때 에러가 발생하는 이유는?
CREATE TABLE emp
(id NUMBER PRIMARY KEY,
ename VARCHAR2(10),
seq CHAR,
gender VARCHAR2,
reg VARCHAR2(1))
a. NUMBER 타입의 크기를 지정하지 않았기 때문에
b. CHAR 타입의 크기를 지정하지 않았기 때문에
c. VARCHAR2 타입의 크기를 지정하지 않았기 때문에
d. VARCHAR2 타입의 최소 크기는 2 이상이므로
e. 에러가 발생하지 않는다
<해설>
CHAR 타입은 고정 길이 문자열이고 VARCHAR2 타입은 가변 길이 문자열 타입이다. VARCHAR2 타입은 저장된 데이터와 길이 정보가 함께 기록되므로 CHAR에 비해서 약간의 오버헤드가 존재하지만 문자열의 길이가 일정하지 않은 경우에도 낭비되는 공간이 없기 때문에 디스크를 크게 절약할 수 있다.
CHAR 타입은 크기를 지정하지 않았을 경우에는 디폴트 1로 설정되지만 VARCHAR2 타입은 반드시 크기를 지정해 주어야 한다. 그리고 VARCHAR2 타입의 크기가 1인 경우는 CHAR로 선언하는 것에 비해서 길이 정보가 차지하는 공간만 낭비되기 때문에 VARCHAR2 타입의 길이는 1로 선언할 수 없다고 알고 있는 경우가 있지만 실제로는 1로 선언할 수 있다.
NUMBER 타입은 크기를 지정할 수도 있고 지정하지 않을 수도 있는데, 크기를 지정하지 않으면 들어오는 데이터에 따라서 크기가 가변적으로 변하므로 데이터의 크기를 예측할 수 없는 경우에 이용하면 저장 공간을 효율적으로 활용할 수 있다.
정답 : (c) (<- 마우스로 정답 부분을 선택하세요)
10-4. dept 테이블에 4건의 데이터가 들어있는데 부서 이름이 변경되면서 VARCHAR2(14)로 선언되어 있는 dname 컬럼의 크기가 부족하게 되었다. dname 컬럼의 크기를 VARCHAR2(30)으로 늘리는 방법으로 옳은 것은?
a. ALTER TABLE dept (dname VARCHAR2(30))
b. MODIFY TABLE dept (dname VARCHAR2(30))
c. ALTER TABLE dept MODIFY(dname) TO VARCHAR2(30)
d. ALTER TABLE dept MODIFY (dname VARCHAR2(30))
e. 테이블에 데이터가 들어 있으므로 확장할 수 없다.
<해설>
컬럼의 크기를 확장할 때에는 데이터가 들어있어도 무방하지만 크기를 축소시키는 작업은 테이블에 데이터가 전혀 없거나 또는 해당 컬럼에 NULL 값만 들어 있는 경우에 한해서 허용된다. 컬럼의 크기를 변경할 때에는 ALTER TABLE <테이블 명> MODIFY 명령을 사용한다.
정답 : (d) (<- 마우스로 정답 부분을 선택하세요)
제약 조건
11-1. 다음 SQL 문에서 잘못된 곳은?
a. CREATE FORCE VIEW viewemp
b. AS SELECT empno, ename, sal, deptno
c. FROM emp
d. WHERE sal > 2000 and deptno = 10
e. WITH CHECK OPTION AND WITH READ ONLY
<해설>
뷰는 테이블이나 다른 뷰에 기초하여 만드는 가상의 테이블이다. 뷰에는 실제의 데이터가 저장되는 것이 아니라 단지 뷰를 만드는 SQL 문만 가지고 있으면서 뷰를 사용할 때 딕셔너리에 저장된 SQL 문을 이용하여 원래의 테이블을 사용하는 명령으로 확장되어 실행된다. 위의 SQL 문의 잘못된 부분을 수정해서 뷰를 만든 다음에 딕셔너리를 보면 다음과 같이 소스 텍스트가 들어 있음을 알 수 있다.
SELECT TEXT
FROM USER_VIEWS
WHERE VIEW_NAME='VIEWEMP';
TEXT
-----------------------------------
SELECT empno, ename, sal, deptno
FROM emp
WHERE sal > 2000 and deptno = 10
WITH CHECK OPTION
뷰를 이용하면 원래의 테이블을 사용하는 SQL 문을 만들어 내기 위한 파싱 작업에 약간의 오버헤드가 걸린지만 일반적으로 SQL 문의 수행 시간에 비하면 파싱 시간은 무시할 정도이기 때문에 직접 테이블을 사용하는 SQL 문과 비교했을 때 속도 문제는 거의 발생하지 않는다고 볼 수 있다.
뷰를 사용하는 이유는 여러 가지가 있다. 예를 들면 복잡한 조인으로 얽혀 있는 SQL 문을 사용자들이 간단하게 쓸 수 있도록 한다거나 또는 테이블의 중요한 컬럼을 노출시키지 않음으로써 보안을 강화하는 목적으로도 사용된다.
(a)를 보면 뷰를 만들 때 FORCE 옵션을 사용하였는데 FORCE를 지정하면 뷰가 참조하는 테이블이 아직 존재하지 않거나 참조할 권한이 없는 경우에도 일단 뷰를 생성한다. 물론 FORCE를 이용해서 만들더라도 실제로 뷰를 사용하기 위해서는 뷰에서 참조하는 객체가 모두 만들어져 있어야 한다.
뷰를 통해서도 원래의 테이블에 제한적이지만 데이터를 추가하거나 수정, 삭제할 수 있는데 WITH CHECK OPTION을 사용하면 뷰가 SELECT 할 수 있는 레코드에 한해서 추가, 수정, 삭제할 수 있다. 그리고 WITH READ ONLY는 뷰를 SELECT 이외의 용도로는 사용할 수 없도록 한다. 따라서 이 두 가지 옵션은 서로 상충된 의미를 가지고 있기 때문에 함께 사용할 수는 없다.
정답 : (e) (<- 마우스로 정답 부분을 선택하세요)
11-2. 다음 중 뷰에 대한 설명으로 옳지 않은 것은? (세 가지)
a. 뷰를 만들 때에는 여러 개의 테이블을 참조할 수 있다.
b. 뷰는 참조하는 테이블과 같은 테이블스페이스에 저장된다.
c. 다른 뷰를 참조하는 뷰도 만들 수 있다.
d. 뷰에도 인덱스를 만들 수 있다.
e. 조인을 사용해서 만든 뷰를 통한 데이터 추가, 수정, 삭제는 불가능하다.
<해설>
뷰는 하나의 테이블이나 뷰를 참조해서 만들 수도 있고 여러 개의 테이블을 조인해서 만들기도 한다. 특별한 뷰에는 데이터 분할을 위한 파티션 뷰와 관계형 테이블을 객체로 포장하는 오브젝트 뷰가 있는데 여기서는 다루지 않는다.
뷰에는 데이터가 저장되는 것이 아니라 단지 시스템 테이블스페이스의 데이터 딕셔너리에 SELECT 문을 가지고 있을 뿐이다. 따라서 뷰에 대한 모든 정보는 시스템 테이블스페이스에 저장되므로 (b)는 옳지 않다.
뷰는 SELECT 문에 불과하므로 뷰에 직접 인덱스를 만들 수는 없으며 뷰가 참조하는 테이블에 걸려있는 인덱스를 그대로 사용하게 된다. 그러므로 만약 인덱스가 필요하다면 뷰에서 참조하는 테이블에 인덱스를 만들어야 한다.
과거에는 뷰를 만들 때 조인을 사용하면 뷰를 통한 데이터 변경이 불가능했지만 현재는 조인을 사용한 경우에도 제한적이지만 뷰를 통한 데이터의 추가, 변경, 삭제 작업을 할 수 있다. 자세한 내용은 다른 과목에서 다루기로 한다.
정답 : (b) (d) (e) (<- 마우스로 정답 부분을 선택하세요)
11-3. 다음 SQL 문에서 에러가 발생하는 곳은?
a. CREATE TABLE emp
b. (empno NUMBER(4) PRIMARY KEY,
c. ename VARCHAR2(10) CHECK (ename = UPPER(ename)),
d. hiredate DATE CHECK (hiredate <= SYSDATE)
e. sal NUMBER(8,3) UNIQUE,
f. comm NUMBER(8,3) CHECK (comm > 1000) DISABLE,
<해설>
CHECK 제약 조건은 사용자가 원하는 비즈니스 룰을 적용할 때 많이 사용된다. 다른 제약 조건도 마찬가지이지만 CHECK 제약 조건을 이용하면 테이블에서 자체적으로 잘못된 데이터를 걸러내므로 응용 프로그램에서 처리할 일을 많이 감소시킬 수 있다. CHECK 제약 조건에서 사용할 수 없는 것은 다음과 같다.
1) 다른 레코드를 참조하기 위한 쿼리를 사용할 수 없다
2) SYSDATE, USER, UID, USERENV 등의 함수를 사용할 수 없다.
3) ROWNUM, CURRVAL, NEXTVAFL 등의 가상 컬럼(pseudocolumns)을 사용할 수 없다.
한 가지 특이한 점은 다른 NULL 연산과는 달리 CHECK 제약 조건의 계산 결과가 NULL 인 경우에도 만족한 것으로 평가된다는 것이다. 즉, 위에서 약 comm 컬럼의 값이 NULL 이라면 (comm > 1000) 수식은 성립될 수 없으므로 NULL이 되지만 CHECK 제약 조건을 만족시키게 된다.
그리고 CHECK 제약 조건을 만들 때 DISABLE 이라고 지정했기 때문에 제약 조건은 생성되지만 나중에 ENABLE 시킬 때 까지는 역할을 수행하지 않는다.
정답 : (d) (<- 마우스로 정답 부분을 선택하세요)
11-4. emp 테이블의 deptno 컬럼에 FOREIGN KEY를 설정해서 dept 테이블의 deptno 컬럼을 참조하려고 한다. 이 때 부모 테이블인 dept 테이블의 레코드가 삭제되었을 때 자동으로 연관된 emp 테이블의 레코드까지 삭제하려면 FOREIGN KEY를 어떻게 만들어야 하는가?
a. ALTER TABLE emp MODIFY (deptno NUMBER(2) CONSTRAINT fk_deptno FOREIGN KEY(deptno) REFERENCES dept(deptno) ON DELETE CASCADE)
b. ALTER TABLE emp MODIFY (deptno NUMBER(2) CONSTRAINT fk_deptno REFERENCES dept(deptno) ON DELETE CASCADE)
c. ALTER TABLE emp ADD CONSTRAINT fk_deptno FOREIGN KEY(deptno) REFERENCES dept(deptno)
d. ALTER TABLE emp ADD CONSTRAINT fk_deptno FOREIGN KEY(deptno) REFERENCES dept(deptno) ON DELETE CASCADE
<해설>
ON DELETE CASCADE 옵션을 주지 않고 FOREIGN KEY를 만들면 부모 테이블의 레코드를 삭제할 때 그 레코드를 참조하는 자식 테이블의 레코드가 존재하면 에러가 발생하게 된다. 그러나 이런 상황이 반복되면 작업하기가 불편하기 때문에 ON DELETE CASCADE 옵션을 사용할 수가 있다. FOREIGN KEY를 만들면서 ON DELETE CASCADE 옵션을 지정해 주면 부모 레코드가 삭제될 때 자동으로 자식 레코드까지 삭제된다.
정답 : (d) (<- 마우스로 정답 부분을 선택하세요)
|
