SELECT
지금까지 데이터를 구축했다면 그 데이터들을 어떻게 효율적으로 뽑아내느냐 하는 것은 SELECT문을 어떻게 쓰느냐에 관건이 걸려 있다. SELECT는 테이블뿐만이 아니라 VIEW에서도 할 수 있다. 그 점 유념하고 VIEW의 개념에 대해서는 조금 뒤에 다시 설명하도록 하겠다.
SELECT [ALL|DISTINCT [ON column] ]
expression [ AS name ] [, ...]
[ INTO [TEMP] [TABLE] new_table ]
[ FROM table
[alias ] [, ...] ]
[ WHERE condition ]
[ GROUP BY column [, ...] ]
[ HAVING condition [, ...] ]
[ { UNION [ALL] | INTERSECT | EXCEPT } select ]
[ ORDER BY column [ ASC | DESC ] [, ...] ]
[ FOR UPDATE [OF class_name...]]
[ LIMIT count [OFFSET|, count]]
역시 굉장히 복잡한 구조를 가지고 있다. 하나 하나 순서대로 설명하도록 하겠다.
WHERE
SELECT는 하나 또는 여러개의 테이블에서 레코드를 리턴하게 되며 이는 WHERE절에서 정의한 조건을 만족하는 레코드만 가져오도록 되어 있으며 만약 WHERE절을 생략했을 경우 모든 레코드를 다 가져오게 된다.
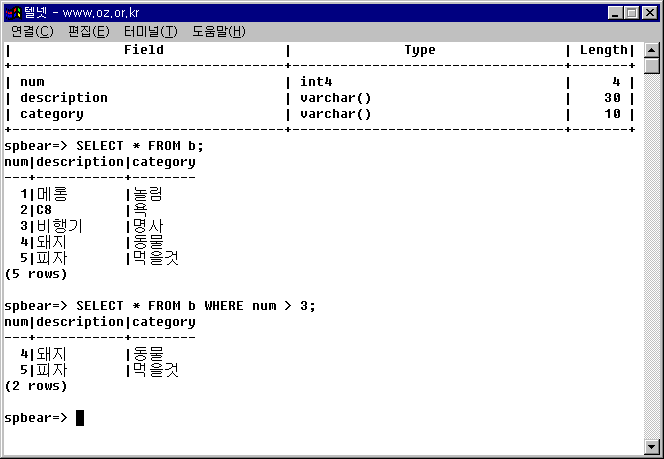
예제 3-21. SELECT... WHERE 예제
SELECT * FROM b; SELECT * FROM b WHERE num > 3;
그림 3-23. SELECT... WHERE 실습.
Expression
expression이 오는 자리는 SELECT한 레코드의 컬럼 이름이 올 수 있으며, 수식등이 올 수 있다. 컬럼이 오는 곳에 SQL구문에서 지원하는 함수등을 사용할 수도 있다. 대표적으로 쓰이는 함수는 max(), min(), sum(), avg(), count()등이 있다. 만약 모든 컬럼을 다 출력하고 싶을 경우는 *를 사용하면 된다. 그리고 셀렉션 된 컬럼의 이름을 변경하고 싶다면 AS를 사용하면 변경 시킬 수 있다. 예제를 보도록 하자.
예제 3-22. Expression의 여러 예제
SELECT num FROM b; SELECT 3+5; SELECT 3+5 AS result;
그림 3-24. Expression 실습.
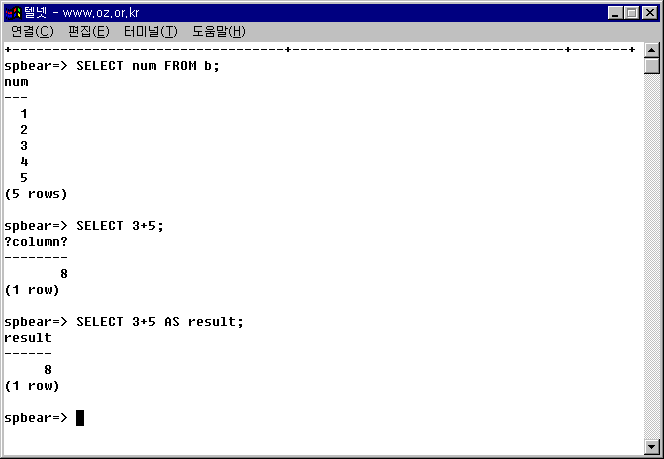
아래 결과에서 보면 알 수 있겠지만 3+5한 결과는 ?column?이라는 이상한 이름의 컬럼으로 리턴되고 있다. 이러한 것을 막기 위해 AS를 사용하여 컬럼명을 명확하게 해주는 것이다.
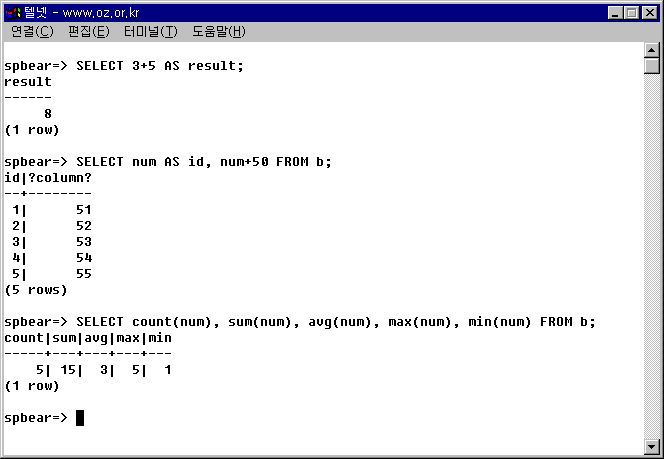
예제 3-23. 또 다른 예제
SELECT num AS id, num+50 FROM b; SELECT count(num), sum(num), avg(num), max(num), min(num) FROM b;
그림 3-25. Expression 실습.
DISTINCT
DISTINCT는 SELECT된 레코드중에서 중복되는 레코드를 제거해 준다. 반대로 ALL은 중복에 관계없이 모든 레코드를 다 가져온다. DISTICT나 ALL을 사용하지 않으면 기본적으로 ALL을 적용시킨다. DISTINCT ON은 특정 컬럼에 대해서만 DISTINCT를 적용하는 것이다. 예제를 보도록 하자.
우선 DISTINCT예제를 적용시킬 수 있도록 다음의 쿼리를 주어 임의의 중복값을 만들자.
예제 3-24. DISTINCT의 예제를 위한 중복값 생성
INSERT INTO b VALUES(6, '피자', '먹을것'); INSERT INTO b VALUES(4, '돼지', '동물');
그림 3-26. 실습을 위한 임의중복 레코드 만들기.
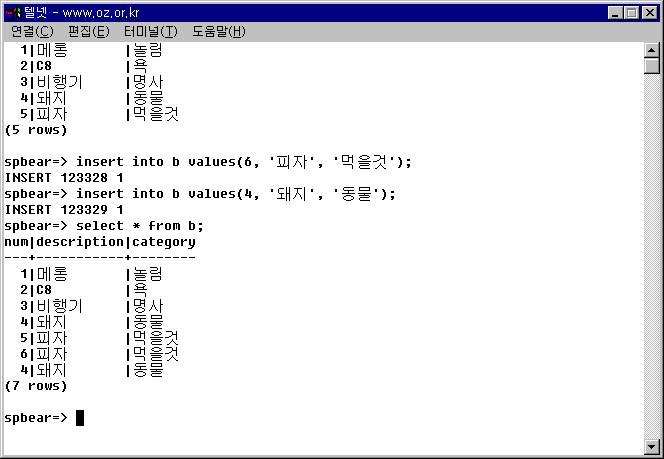
위와 같이 SELECT를 그냥 사용하면 SELECT ALL과 동일한 결과를 얻을 수 있기 때문에 모든 레코드를 출력한다. 이제 DISTINCT를 적용해 보도록 하자.
예제 3-25. DISTINCT를 적용한 SELECT쿼리
SELECT DISTINCT * FROM b;
그림 3-27. DISTINCT의 실습.
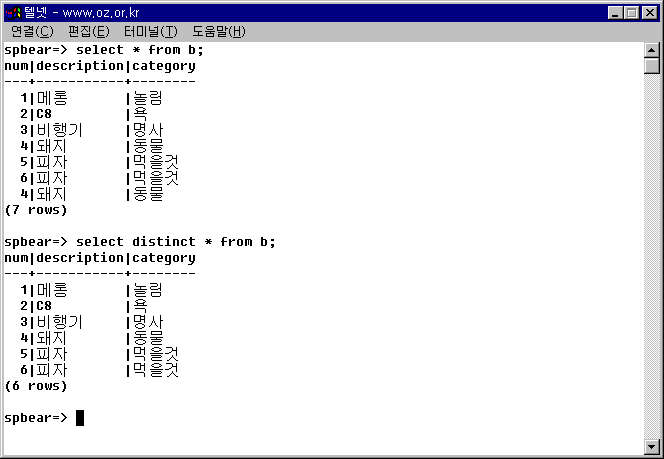
결과에서 볼 수 있듯이 이번에는 6개의 레코드만이 출력되었다. 선택하는 모든 컬럼이 중복되는 (4, 돼지, 동물)의 항목이 하나만 선택된 것이다. 이번에는 DISTINCT ON을 적용해 보도록 하자.
예제 3-26. 하나의 항목에만 DISTINCT를 적용시킨 쿼리
SELECT DISTINCT ON description * FROM b;
그림 3-28. DISTINCT의 실습.
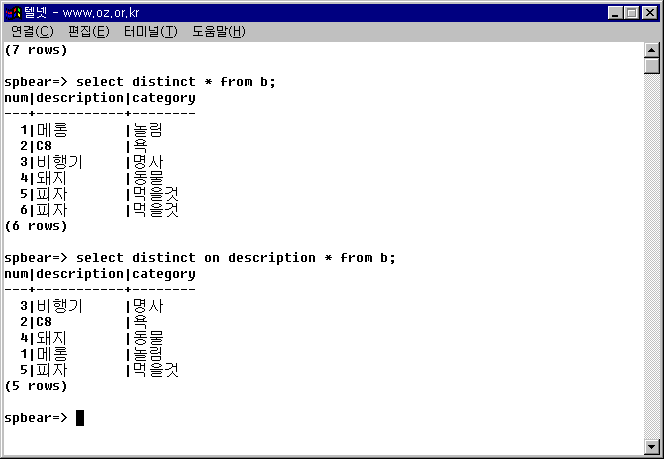
이번에는 5개의 레코드만이 선택되었음을 알 수 있다. 이번에는 description이 중복되는 (6, 피자, 먹을것) 항목이 제거된 채로 선택된 것이다.
GROUP BY
GROUP BY는 유저로 하여금 테이블에 그룹을 나누는 것이다. 예제를 통해 확인 하자. 이때 선택되는 항목은 반드시 GROUP으로 묶은 컬럼이거나 그렇지 않은 컬럼의 경우는 aggregation된 컬럼이어야 한다. 여기서 잠깐 aggregation된 컬럼이란 무엇인가 짚고 넘어가자. 우리가 예전에 SELECT sum(num) FROM b;와 같은 쿼리를 준 적이 있을 것이다. 결과는 b라는 테이블에서 num을 가져와서 모두 더한 결과값만이 출력될 것이다. 이와 같이 실제로는 여러개의 레코드이지만 그 레코드를 하나로 묶어놓은 컬럼을 aggregation된 컬럼이라고 한다. 이것 역시 예제로 공부해 보자.
예제 3-27. GROUP BY를 이용한 예제
SELECT * FROM b GROUP BY category; SELECT num, category FROM b GROUP BY category; SELECT category FROM b GROUP BY category; SELECT count(*), sum(num), category FROM b GROUP BY category;
그림 3-29. GROUP BY의 실습.
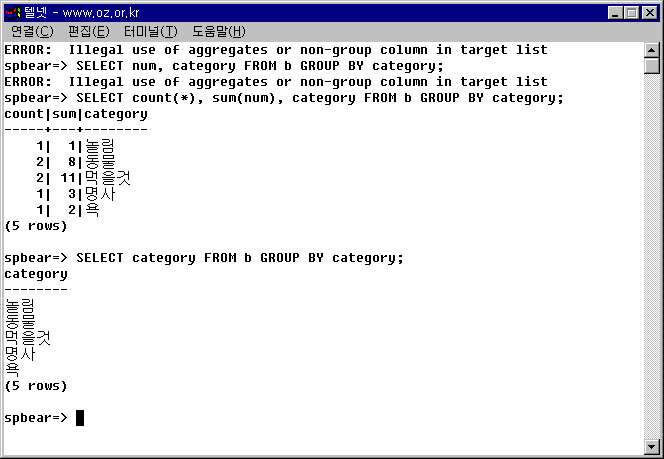
아래 결과를 보면 알 수 있지만 위의 두개의 문장은 에러를 출력한다. *나 num는 aggregation된 컬럼이 아니기 때문에 에러를 발생시키지만, 세번째 쿼리는 정상적으로 동작한다. 이 결과만 보면 DISTINCT하는 것과 동일하겠지만 네번째 쿼리를 보면 어째서 DISTINCT를 쓰지 않고 GROUP BY를 쓰는지 이해할 수 있을 것이다. count(*)를 넣음으로써 GROUP으로 선택된 레코드가 몇개인지 알 수 있고, GROUP으로 묶여진 레코드간의 num를 서로 더하는 것이 가능하다.
좀 더 색다른 예제를 위해 다음의 쿼리를 주고 비교해 보도록 하자.
예제 3-28. GROUP BY의 또 다른 예제
INSERT INTO b VALUES (7, '소', '동물'); SELECT description, category FROM b GROUP BY category, description;
이번에는 두개의 컬럼을 서로 그룹을 지었기 때문에 두개의 컬럼이 서로 다른 경우에만 선택이 된다.
HAVING
HAVING절은 GROUP BY절에서의 WHERE라고 생각하면 이해가 쉽다. 어떠한 그룹을 출력하게 될 것인지 정하게 되는데 이때 조건에 오는 표현식 역시 aggregation양식으로 표현되어야 한다. 예제를 보도록 하자.
예제 3-29. HAVING절의 예제쿼리
SELECT description, category FROM b GROUP BY category, description; SELECT description, category FROM b GROUP BY category, description HAVING count(*)=2;
위의 두개의 쿼리를 비교해 보도록 하자. 첫번째 쿼리는 그룹으로 묶은 모든 컬럼을 가져 오도록 하고 있고, 두번째 쿼리는 그룹내에 두개의 항목이 존재할때 출력하도록 하고 있다.
ORDER BY
ORDER BY절은 선택되어진 결과값에서 특정컬럼을 기준으로 소팅을 하여서 출력하여 준다. ORDER BY는 뒤에 DESC나 ASC가 올 수 있는데 ASC는 오름차순, DESC는 내림차순으로 정렬을 하도록 하는 것이다. 아무것도 지정하지 않는다면 기본적으로 ASC가 적용된다. 예제를 보도록 하자.
예제 3-30. ORDER BY의 예제
SELECT * FROM b ORDER BY num; SELECT * FROM b ORDER BY num DESC;
첫번째 쿼리는 num를 기준으로 오름차순으로 정렬해 주며, 두번째 쿼리는 num컬럼을 기준으로 내림차순으로 정렬해 준다. 첫번째 쿼리는 SELECT * FROM b ORDER BY num ASC; 와 동일하다.
예제 3-31. ORDER BY에서 여러개의 정렬기준 항목 설정
SELECT * FROM b ORDER BY description, category DESC;
이와 같은 쿼리를 줄 수도 있는데, 위와 같은 쿼리는 일단 description에 대해서 정렬을 한 후 만약 descirption이 같은 레코드에 대해서는 category컬럼을 기준으로 내림차순으로 정렬하라는 쿼리이다. 결과는 다음과 같다. (일부서버에서는 한글 인코딩 문제로 한글의 경우 소팅이 제대로 되지 않는 문제가 발생한다. PostgreSQL을 업그레이드 하거나 패치를 해주어야 한다.)
UNION, INTERSECT, EXCEPT
UNION, INTERSECT, EXCEPT는 합집합, 교집합, 차집합과 관련된 쿼리이다. 다음의 예제를 통해 알아보자.
예제 3-32. 예제를 위한 데이터 작성
우선 예제 적용을 위해 기존에 만들었던 a테이블에 데이터를 입력하자.
INSERT INTO a VALUES (3,'피자'); INSERT INTO a VALUES (4,'오징어볶음'); INSERT INTO a VALUES (5,'보신탕'); INSERT INTO a VALUES (7,'소');
이런 후 각각 UNION, INTERSECT, EXCEPT 예를 보도록 하겠다.
우선 UNION부터 살펴보자. UNION은 두 테이블간의 서로 합집합을 만들어 주도록 되어 있다. 이때 두개의 SELECT문장을 UNION시킬때 두개의 SELECT문장에서 선택하는 컬럼의 구조는 동일하여야 한다. 이는 UNION만이 아니라 INTERSECT, EXCEPT도 마찬가지이다.
예제 3-33. UNION의 예제
SELECT num, description FROM b UNION SELECT c1, c2, FROM a;
위에서 보는 바와 같이 두개의 테이블이 서로 합집합이 되었다.
이번에는 INTERSECT이다. INTERSECT는 위에서 언급한대로 교집합의 관계이다.
예제 3-34. INTERSECT의 예제
SELECT num, description FROM b INTERSECT SELECT c1, c2 FROM a;
마지막으로 EXCEPT는 차집합의 관계이다.
예제 3-35. EXCEPT의 예제
SELECT num, description FROM b EXCEPT SELECT c1, c2 FROM a;
이로써 간략하게 SELECT문장에 대해서 살펴 보았다.