|
Identifiers, Authentication, and Directories: Best Practices for Higher Education
http://middleware.internet2.edu/internet2-mi-best-practices-00.html
이 글은 대학에서 LDAP 로 인원 관리시에 구성 방법에 대해서 몇가지 적어 놓은 글로 이럴때 LDAP 를 이런 식으로 사용하는 구나 하는 방법론에 대해서 몇가지 점을 볼수 있습니다. 참조하시기 바랍니다.
Internet2 Middleware Initiative
9 May 2000
This document is a product of the Internet2 Middleware Initiative's Early Harvest workshop, held in Denver in September 1999, and subsequent discussions. This document is a work in progress; it is inappropriate to cite this document as anything other than a work in progress.
Identifiers
"Any problem in Computer Science can be solved with another level of indirection."
— Butler Lampson
"...except the problem of indirection complexity."
— Bob Morgan
Motivation
For the following reasons, it is increasingly important that identifiers be made coherent and consistent throughout the enterprise.
Identifiers are the foundation of the campus middleware infrastructure. If you don't know what to call an entity, you can't find it, and if you can't find it, you can't provide it with services like authentication or directories.
Taking a look at the policies associated with the creation and assignment of IDs will illuminate many of the gray areas that institutions have about who can access particular IT resources.
Separate systems are no longer islands; increasingly, applications and situations require the use of more than one system.
Making one or more central organizations responsible for life-cycle management of these IDs is likely to result in a more coherent and systematic management of the ID space.
If an ID space exists, then departments have the option of leveraging that ID space (both people and groups) and using it in the management of their own local systems. This is likely to make the departmental systems more secure.
If departments can leverage a central ID space, then less departmental sysadmin time will be required to manage IDs and passwords.
If departments are leveraging a central ID space to provide userids and passwords on their local servers, then a central organization at the university can manage that space in times of crisis. This makes the smooth functioning of the ID space less dependent on the uninterrupted availability of particular individuals.
Integrating the various identifiers requires:
Ensuring that there are unique and distinct identifiers to meet the particular requirements of the campus IT environment.
For each enterprise-wide identifier, an explicit set of policies that governs its assignment and use.
Mechanisms to relate the multiple identifiers that an object might have.
A decision about the extent to which local identifiers should be linked to a unique central identifier. Through leveraging a central directory service, many local IDs might, in fact, become central IDs. In an environment with distributed, delegated management, each person may have multiple local IDs. There exists a tradeoff between the effort involved in using a central directory and the value derived from this linkage.
A campus will want, for example, enterprise-wide email addresses, netid logins, and several other identifiers. For each of these identifiers there should be explicit policies; for example, whether the identifier is permanently assigned or can be reissued, who is permitted to assign the identifier, and what applications can read or use the identifier. Given one identifier, such as a person's network ID, it is important to have effective mechanisms to obtain related identifiers, such as the person's email address or local LAN account.
[colorBLUE]Identifier Characteristics
Before we begin the discussion of specific identifiers, we note some important generic characteristics of identifiers.
readability, also known as human-friendliness or lucency. The opposite of lucency is opacity. Can the real-world subject be identified from the value of the identifier? Email addresses are usually lucent; UID’s and barcodes are opaque. If the identifier is to be used by a person, mnemonic and canonical names are desirable. Machines can handle long numeric strings; some peripheral devices prefer bar codes. Human-friendly identifiers are sometimes referred to as "names", with "identifiers" reserved for identifiers that are opaque by design. In this document, "identifiers" refers to both types.
provisioning — Some identifiers can be assigned by distributed locations using local information; others must be computed and assigned centrally. For example, unique IDs are typically centrally provisioned, while hostnames within a DNS space are usually provisioned locally.
metadata — What are the criteria for assignment of the identifier? How is it known what service provides the mapping information for the identifier, that is, resolves the ID into its real-world subject?
persistence — Is the assignment of the identifier to an object permanent? If not, in what ways, or under what circumstances, can the identifier be reassigned? Here it is important to distinguish between reassignability (whether an existing ID value can go to a different subject) and revokability (whether an existing subject can be assigned a different ID value, or be deprived of an ID altogether). For example, UIDs are non-reassignable, SSNs are non-revokable.
capacity — Given the rules on how to form an identifier, how many different instances of the identifier can be formed?
uniqueness (within a given context)
intelligence — Does the identifier have meaningful subfields?
resolver approach — How is the identifier mapped to its associated object?
granularity — How specifically does the identifier denote a collection or component?
format (check digits)
versions — Can the defining characteristics of the identifier change over time?
extensibility — Can the identifier be intelligently extended to be the basis for another identifier?
public visibility — Who can see the identifier?
Needs for Identifiers in Higher Education
As well as different kinds of people (students, faculty, staff, alumni, guests, etc.) there are likely to be several other types of objects, such as printers and groups, whose identifiers will need to coexist with people IDs in the same namespaces. For example, when sending email, it is useful to be able to use email addresses for individuals, group names, and printer names interchangeably in the To: field. Not a lot is known yet about what kinds of separate identifiers will prove best for groups and printers. For this reason, and because how non-people identifiers are used depends heavily on how people identifiers are used, people identifiers are the main type discussed in this document.
In a modern university setting, there are likely to be needs for several types of enterprise-wide people identifiers. Ten such types are discussed here; additional identifiers may be generated by local requirements. A particular identifier may fulfill several functions; for example, a name may serve as both a netid and an email address. Frequently a single ID may be used in several of the roles listed below. In such a case attention must be paid to the fact that different IDs may have different eligibility requirements. For example, if the account name is revokable but the netid is not, there may be problems. Where least-authority authorization is practiced, it is recommended that distinct identifiers be used for different roles; this also helps maintain flexibility in technologies and policies. Where least-authority is not in use, attribute-based authorization is also a reasonable approach.
Identifer Types
unique identifier (UID)
Sometimes called the Universally Unique ID, Primary Unique ID, or Enterprise Unique ID. This is the primary internal identifier, used for file access, group membership, and accounting. A secondary use is archiving institutional electronic records. It is valuable to have this be human-unfriendly, to discourage its inappropriate use. This ID is centrally provided, perhaps with distributed online clients. It is assigned to all current active users of campus electronic resources. The UID should be non-revokable and non-reassignable; hence it needs a large capacity (32 bits minimum). All other identifiers should be either directly or indirectly linked to the UID.
person registry ID
Used to resolve ambiguities on identity; critical to distributed and outreaching activities. It is typically opaque, centrally administered, and eternal, and has a very large capacity. Anyone associated with the institution in any way should have a person registry ID. Although the information about an individual that constitutes his or her person registry ID may be made available to directory services, the application that generates and manages person registry IDs uses a database, not a directory, to store it. It is of particular importance for the person-registry ID to be linked to the UID.
account login
This is the identity associated with primary login to restricted campus resources such as email and the Web. It is closely related to, and often the same as, the...
netid
Both account login and netid are lucent, and for both ownership is proven via an institutional authentication process that is part of a distributed infrastructure. Like the UID, both are centrally provided and are assigned to all current active users of campus electronic resources. Schools differ on whether account login and netid should be reassignable and/or revokable. It is tempting to use these IDs to apply to groups, because they make it possible to know what a group is by looking at its ID. Using these IDs for groups also facilitates web access control. However, assigning account logins and netids to groups allows groups to login, and this may produce audit problems.
Although most campuses make account login and netid the same ID with the same password, this is not always a good idea. While doing so has the advantage of reducing the number of IDs, it may be better to use the netid for broad network access and "gateway" resources like modem pools, reserving the account login ID for specific restricted resources like Web and email. Separating these functions may also require giving these IDs different policies and persistences. Account login and netid can be separated by using the same ID for both, but with a separate password for each set of functions, or by using both different IDs and different passwords.
Social Security number (SSN)
Several factors, including new legal restrictions and growth in the number of foreign students, have made this identifier less useful, but it still has a lot of value.
publicly visible ID (PVI)
With restrictions on the use of SSNs, there is a need for an identifier to use for posting grades publicly, resolving ambiguous directory lookups (e.g., "Which Bob Smith do you want an email address for?"), etc. This "pseudo-SSN" should be human-readable but relatively dumb; it is usually simplest to make it resemble the SSN in form (9 digits) as well as function. In particular, it should not suggest the name of the owner. It is centrally afforded, resolved through a directory, and may be revokable and/or reassignable.
email address
Email addresses tend to be very human-friendly, and can serve as global identifiers in some instances. They are usually centrally provided, and are often resolved via sendmail or LDAP to an account identifier. There is less agreement about whether assignment of an email address should be permanent, although even institutions that recycle email addresses usually retire them for some period of time between uses. Some schools allow people to use additional email aliases or "nicknames"; these are often not guaranteed to be permanent or nonrevokable. One solution is to assign a single persistent email address and take nonpersistent aliases as different email identifiers.
library/departmental ID
There are usually a number of such identifiers with enterprise-wide scope, such as library cards, ID card bar codes, and door access mechanisms. It is desirable to have these linked to some permanent identifier, such as a UID, that can be used to find associated attributes and identities. Library IDs may need to be assigned to individuals who otherwise have no relationship with the institution.
pseudonymous ID
There are instances, mostly in higher education, where a unique but opaque identifier — a pseudonym — is needed for external use. For example, ensuring privacy rights in access to academic resources such as libraries or databases might require a pseudonymous identifier that asserts some association but does not allow the external resource to positively identify the user. The pseudonymous ID is centrally provided and typically opaque. There is no broad consensus about the persistence of this identifier.
administrative system IDs
These typically include employee IDs and student numbers for (often legacy) HR and student info systems. These IDs are typically centrally assigned to part of the campus population, and are reassignable, seldom revoked, and opaque. The organization that assigns these IDs is typically the organization (HR, Registrar) that owns the system in question. Frequently the policies associated with these IDs are not widely understood.
Identifier Relationships and Mapping
Directories (and in particular person registries — see below) are where different types of identifiers are correlated. Often having one ID permits you to get other types of IDs; for example, having an account login may make it possible for you to use an email address. It is important to understand such relationships among IDs.
One way to do this is to go through an ID mapping process, asking (often difficult) questions about the characteristics associated with each ID type to be used. It is often helpful to create an ID mapping table, with rows for the types of ID to be used and columns for relevant characteristics such as primary use, secondary use, lucency, persistence, provisioning, and who is eligible to get the ID. The lists of characteristics and ID types above provide a place to start.
This process can also shed light on the contents of the fields of an X.509 certificate, the CRUD (Create, Read, Update, Delete) matrix used to understand the various roles that individuals and organizations have as data is consolidated within a directory, the RDN for a person within a directory, and many other areas where identifiers are used.
Person Registries
A person registry is a directory or database whose primary functions are identity management, reconciliation ("Is this person the same as that person?"), and cross-indexing ("Given this person's ID on system X, find their ID on system Y.") The person registry can also serve as a reference identifier for other systems. Other types of registries, such as organization registries or group registries, may also exist; registries in general are also referred to as metadirectories. Both directory and metadirectory products often come with person registries.
Person registries come in two varieties: thick and thin. Thick person registries contain lots of details on each individual; thin person registries contain only the system-identifier pairs needed to enable you to find the details elsewhere. As reconciling identities involves not only gathering up identifier strings, but also rationalizing the expression of the interesting relationships (e.g. faculty/staff/students/alumni/affiliates), registries tend to start thin and end up thick.
The person registry may contain more people than the directories it serves; for example, guests on campus may need to be placed in the person registry, but not in enterprise directories. Typically the person registry has feeds from several sources:
The student information system. If that system does not track prospective students, then a feed from the prospective student system is desirable as well.
The personnel system.
Special authorizations. There are many possible inputs to this, including continuing education, athletic recruiting systems, alumni systems, auxiliary applications (camps, contracted services, day care, etc.), research partnerships, guests, and others.
The person registry is activated by a trigger event in the source systems, usually the adding of a new person to a source-system database. The feeds from these systems can be done via batch files or with interactive procedures.
The person registry has two stages in its process.
Determine if a new person entering the registry is really a unique instance or already exists in the system. This is usually done by comparing key elements such as name, date of birth, city of birth, SSN and mother's maiden name.
If the new person is unique, assign them an identifier and enter them into the registry. If the new entrant is an existing person, the source system may be notified and provided with the existing person's registry identifier. If there is uncertainty, the system that initiated the new entrant is notified and an arbitration process is initiated.
A third mode of operation is to update information held within the registry, as with a name change. Since the person registry holds very little volatile information, this is an infrequent and straightforward activity.
The person registry may be operated by a central IT organization or by a sponsoring campus unit such as the Registrar or Personnel. This unit may handle the arbitration process as well. Although there is a real cost in labor to this work, there are major institutional efficiencies to having this focused approach.
Because performance issues are not important, the person registry may be implemented as a database rather than a directory. Unexpected benefits of a person registry may include cleaning up after student information system errors, such as mistyped SSNs. Person registries should be cautious about merging two separate entries into the same real world subject. Once merged, separation is difficult.
Authentication
The three main authentication mechanisms currently in use in higher education are PKI, Kerberos, and passwords. To a first approximation, PKI is the future, Kerberos is the present, and password-based authentication, although it is the past, is likely to linger for quite some time. Some institutions have deployed challenge-response systems (e.g., S/Key, Smart Card), but, due to the expense, this has usually been done only for a small number of highly secure accounts. Experience with exotic methods of authentication (e.g., biometrics) is similarly unavailable. Ideally all routine service authentication should be done via Kerberos v5 or (once we figure out how to do it) X.509 certificates.
While some institutions have deployed X.509 and/or other PKI authentication schemes, for the most part these PKI deployments have generated the certificate, or established the trust relationship, by bootstrapping from an existing password-based authentication scheme. In an environment where people move around a lot, such as a university, the fact that certificates are currently easiest to store on machines, rather than (like passwords) with individuals, presents major problems. Everybody wants personal certificates to be associated with individuals, by means of a house-key or car-key-like device that the individual can easily retain in his or her possession at all times. So far the smartcard and similar systems that make this possible have been too expensive for widespread deployment, but recent hardware developments such as USB make this an obstacle soon to be overcome.
The shortcomings of password-based authentication are well known. However, password-based authentication is still overwhelmingly the dominant type, and is only slowly being replaced by other, superior methods. Other methods often make some use of passwords as well. For example, while using a password once in a secure, three-way authentication mechanism such as Kerberos is far superior to passing a password all the time to every service you want to talk to, poor password management practices can still be a source of problems in a Kerberized environment. For these reasons, the following discussion of authentication best practices focuses on passwords. At the same time, we recognize that passwords are bad — all of these ideas for password management are ways to make them less bad, but they'll always be bad. Campuses should strive to move away from using them.
User-side password management
Precrack new passwords. Standard password cracking programs such as COPS should be used when a user attempts to change a password. With many institutions having large populations of students whose first language is not English, it may be prudent to precrack using non-English as well as English dictionaries.
Confirm that new passwords are different from old ones. Most password-changing programs can be configured to check that the new password differs from the old.
Require a password change when the password may have been compromised. It is helpful to have mechanisms to quantify strength of confidence in passwords, rather than just classifying them as either compromised or uncompromised. It would also be helpful to have a means of presenting this information to users — encouraging a password change whenever confidence drops, but only requiring a change once confidence has dropped below a certain level.
Use shared secrets or a positive photo ID to reset forgotten passwords. Shared secrets are pieces of information that users provide when getting their initial passwords. The traditional shared secret is the user's mother's maiden name. Another approach is to have the user provide several pieces of information when first given a password, and then to require the user to provide some subset of this information (say, two items out of five) in order to change the password. Question-and-answer pairs also make good shared secrets.
Avoid password aging, as it usually does more harm than good. Requiring frequent changes usually causes users to choose passwords that are more obvious, and therefore easier to crack.
Require a minimum length of at least six characters, with character diversity, such as mixing upper and lower case or including non-alphabetic characters, suggested or required. On the other hand, with too high a minimum length, users tend to build passwords from repeated shorter words, leading to easy-to-crack passwords.
Server-side password management
In a non-Kerberized environment, lock the account after repeated unsuccessful attempts to supply a password. The lockdown can be temporary (expires after some fixed period of time) or permanent (a user must contact the central authority to remove the lock).
On the other hand, when using a centrally-administered trusted-third-party scheme such as Kerberos, account lockout policies may result in a broad denial-of-service attack on users. At one university, the GAO has waived the account lockout policy requirement. This decision was based on the use of encryption, pre-cracking of new passwords, and the ability to generate an automated report when a system logs a suspicious number of unsuccessful attempts.
Do not allow cleartext storage or capture of passwords. Use shadow password files.
Maintain audit trails.
Follow proper procedures for superuser/root login, and for changing the root password. Many server-side password management problems are caused by failure to follow universally-accepted system administration best practices. Users with system administrator privileges should have a separate, non-superuser account for day-to-day use, and should take special care with their system administrator account password.
First password assignment
Either US Mail a one-time password or require the user to show up in person with a photo ID (or two). For US Mail, include a time bomb with a short fuse. A variation on this theme used at one institution is to include a student number on the "Welcome to the University" CD that all new students receive, and to make this number a required credential to receive a first password. Demand for new passwords is heavily concentrated around the beginning of each term.
For remote individuals, require an authorized departmental representative to show up in person, as well as a faxed copy of a photo ID from each individual to be given a password. Because people at universities tend to move around a lot (faculty on sabbatical, students on year abroad), and often work at far-flung facilities (staff at the observatory), it is important to have efficient and user-friendly procedures for password assignment for remote users.
Policies: Some institutions restrict the use of an identifier/authentication pair to secure environments. Some require the use of certain identifier/authentication services for particular applications.
It is prudent to have users choose distinct passwords for internal and external accounts. Not only is it difficult to synchronize departmental and central passwords, it is a bad idea even to try. Users should be encouraged to use different passwords for accounts that differ in the level of security provided. Users who wish to disregard this advice and perform "manual password synchronization" are free to do so; this way at least they are aware of the possible consequences. It is best to avoid using LAN passwords for enterprise accounts. We are rethinking the value of single signon for LAN accounts — while single sign-on may be good for the enterprise, the benefits of combining LAN and enterprise signons are uncertain at best.
It is a good idea to have users change their passwords after use from external, unsecured environments. This need not be checked often in order to be helpful. For example, at one institution some timesharing hosts are periodically monitored to determine which users are sending passwords as cleartext. Those users are subsequently notified that their accounts may have been compromised, and they are given detailed information about tools available to secure their connections.
Directories
The problems of making directories work are closely related to the problems of making identifiers and authentication work. One of the principal functions of identifiers is to serve as indices into directories; metadirectories are important as a means of resolving questions about identifiers; X.509 and similar authentication schemes base themselves on directories. When used to provide electronic white pages and similar services, directories are also customers of authentication services. The following discussion focuses on the use of directories to provide white pages and similar services.
Campus directory structure
In the complex world of higher education, campus-wide directory services will likely have several components . The enterprise directory, usually covering a single campus, is typically published from a relational directory database. The directory database represents a join of core administrative information from student information systems, human-resources systems, campus-wide IT services (email, Web, etc.), and feeds from related departmental systems such as Alumni and Facilities. The enterprise directory is the center of things. It is the major institutional operational directory, likely used to support white pages, email addresses, account management, access controls, etc.
The enterprise directory can provide information to, and receives information from, a metadirectory for the larger organization (a state university system, for example). Registries store and reconcile identifiers; directories hold additional information about items stored in registries. Most metadirectory products include a person registry service, as well as serving to coordinate directories. Roughly, registries deal with nouns, directories add adjectives, and metadirectories add verbs. We anticipate implementations starting with person registries, with other registries being added later. There is value in aggregating and identifying IDs across a wide range of services.
The enterprise directory also provides information to a border directory. The purpose of a border directory is to publish campus personal information for the external world in a secure manner. The border directory need not be a separate directory; it could be implemented by adding appropriate access controls to the enterprise directory. Border directories may become more prevalent over the next year or two. There may also be department-specific, operating-system-specific, and application-specific directories, often operated within a LAN.
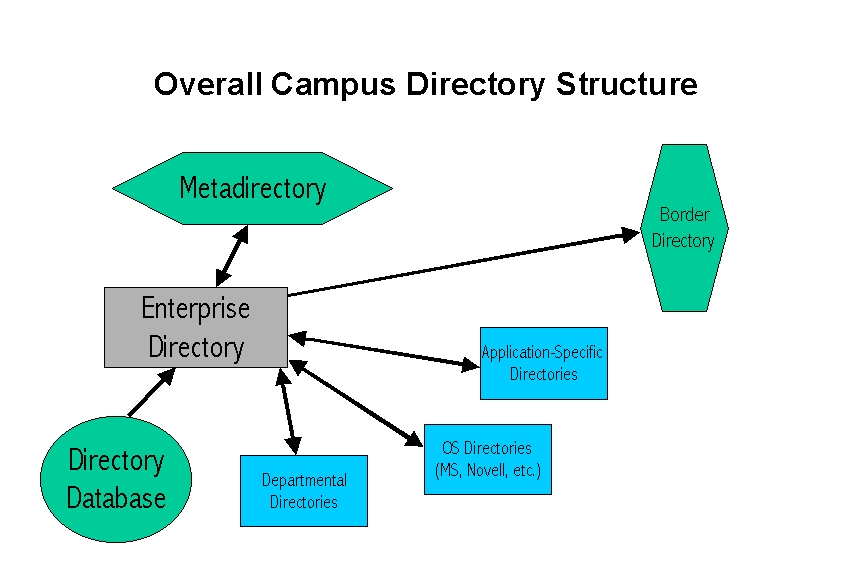
Application-specific directories can help limit the proliferation of schemas and the growth of the directory information tree in the enterprise directory. On the other hand, this minimalist approach to the enterprise directory creates more need for synchronization, and can end up creating more work than it saves. Factors to consider are how many applications need the attributes to be added, how often new attributes are expected to be added, and how long updates will be delayed by the existence of multiple directories. A single "catch-app" directory for all custom attributes is also a possibility.
Universities vary in the degree to which they centralize information in the enterprise directory. While some campuses are putting everything possible in LDAP directories and doing updates there, others do updates exclusively in the RDBMS, and mostly use the enterprise directory to hold "snapshots" taken periodically from the database. The latter approach allows the directory service managers to use standard database tools to deal with administrative issues, but makes it harder to use COTS clients for updates, as these often speak only LDAP. The "snapshot" approach also makes it necessary to write more scripts and SQL code.
Other key big-picture directory issues include dealing with legacy systems (DCE, NDS, NT), integrating current commercial applications (Peoplesoft, SAP), and ensuring that directories will work well with future applications-development platforms. Data ownership, and the more general issue of who has authority to make what changes, are also important.
Enterprise directory design and implementation
The following best practices for enterprise directories are grouped into five categories: schema, referrals and redundancy; naming; attributes; replication and synchronization; and groups.
Schema: Overall logical design, inheritance of policy and attributes, referrals to other parts of the directory tree, and delegation and synchronization are all schema issues that are centrally important to making directories work. Neither replication nor group policies have usually been primary concerns in designing directory schemas.
Make the people database space as flat as possible. The price of changing a person's location in the database is in updating references to the individuals in other areas of the directory, such as groups, and this price must be paid more often the more vertical the database is. Many universities are finding it helpful to store people, machines, and services in separate directory subtrees, and to have more depth and structure in the machines and services spaces than in the people space. The difference in the appropriate depth is due to the fact that people move around a lot more. In particular, it is not a good idea to separate faculty, staff, and students — universities are finding that there is more overlap and movement among these groups than is usually thought at the beginning of a directory project. If complete flatness is not possible, the UID should still be unique across the entire tree, so that things can be moved around with no worries. While flat schemas help with some aspects of directory management, they limit the use of inheritance and group policy objects.
Create a "campus person." Higher education is now developing an auxiliary object class called "eduperson", and the campus person should be created under that object class. The schema for records that describe people on campus should include a standard set of campus-specific attributes. Attributes in this subschema could include, for example, parking permits, library IDs, and recreation center information. It is important to create attributes in the campus person that will not collide with the flat namespace of attributes in the LDAP world. A common practice is to prefix the attribute name with "xu" for X university (underscores are not allowed in attribute names). Most vendors create their schema in a similar fashion; for example, Netscape uses "ns", and Corporate Time uses "ct".
Keep accounts as attributes, not as ou's. There should be no separate "accounts" branch of the directory. Rather, account information should be associated with people entries in the directory. Also, don't make the account information part of a person's dn.
Consider using the following DNS extension to serve directory locations. It is often valuable to be able to find another campus's directory. While there is no standard directory naming scheme, DNS SRV records, a DNS extension described in RFC 2052, makes it possible for DNS to provide directory server addresses.
Use standard dc naming for the root of the directory. For example, dc=Yourschool, dc=edu.
Do not permit directory trolling. Directories are designed to be searched more than read, and trolling can have a severe effect on directory performance. Trolling also allows miscreants to construct mass mailing lists, create shadow directory information, and engage in other ill-advised activities. Limits for responses to an LDAP query for higher education range from 3 to 50.
In estimating the "carrying capacity" of a directory server, consider the different uses to which the directory will be put, as well as traditional load factors such as number of queries. Different uses of directories put different demands on the directory server. An application may want to search a directory to find an entry which matches a given value. Alternatively, given an indexed entry in the directory, one may want to look up attributes of that entry. A third mode of access is to browse a directory looking for all entries with a particular attribute matching a particular value. Each of these uses will affect performance differently.
Make use of LDAP chaining. LDAP chaining — the ability of a central directory to pass client requests to distributed directories — is important. Chaining can help LDAPv2 clients find distributed information. It also permits safe and effective access through firewalls, and it is helpful when the syntax of a foreign namespace is different than local syntax. Chaining can also use new features such as directory location lookup via DNS, and can link via gateways to X.500 or other directories. Metadirectories are another way to perform some of these functions.
Naming
The identifier used as the relative distinguished name should be carefully chosen. The intuitive approach of using common names or account names as the primary key can lead to odd mechanisms to preserve uniqueness, and to rebuilding the tree when names change. It may be better to use a true permanent identifier, such as the UID, for this purpose.
The distinguished name should contain domain component information, in addition to any X.500 syntax. X.500 naming by itself does not offer any capability for finding an associated directory from the name. By including domain information in the fully formed distinguished name, applications that rely on the name can better navigate to find additional information if needed. On the other hand, this may lead to some operational drawbacks with certain vendor products, such as Funk's LDAP-enabled RADIUS product, that have their own way of specifying dn's — thus creating a tradeoff between best practice (dc= naming as advocated above) and practicalities.
Attributes: Most LDAP clients do not treat multivalued attributes well (for example, taking the first value and ignoring the rest), but doing multiple fields with separate attribute names is no better. Most workarounds for this problem are kludgey. The best alternative is to build Web clients; they can display multiple values in a scroll window.
Treat setting default access controls for entries and attributes as an art. Access controls manage both who can read and who can update entries. With large numbers of attributes, the load of setting access controls on each attribute can be overwhelming. Defaults can help reduce this load, but may impede delegation capabilities. In general, access management is easier if updates are done in the underlying database. Moreover, access controls differ, in design and implementation, among various directory products, and they make migration of services difficult.
Index on commonly accessed attributes if the costs in time and disk space are not too great. As the number of applications that use the directory increases, it may be beneficial to build indexes for commonly searched attributes. While this improves search times considerably, it takes time to build and maintain the indexes and a significant amount of disk space to hold them. In general, it is a good idea to index cn, sn, o, os, mail, and phone and fax numbers for presence, equality and substring.
Never repurpose an RFC-defined field. In the decentralized data environments of higher education, maintaining consistency of meaning is difficult. To redefine an existing attribute is to invite misuse. Add new attributes instead — unless the new attributes need to be indexed, adding them is less problematic than is commonly thought.
Keep schema checking on, unless the underlying database does it. As hard as semantic consistency is to maintain, syntactic validity is just as hard. If updates are to be done directly to the directory, then schema checking can have real value. Watch performance; schema checking can slow things down considerably.
Observe appropriate objectclass hierarchies. In particular, objectclasses inherited by the campus person should be defined with the objectclass attribute; otherwise applications that expect to see those objectclasses will not be able to display anything from the directory. This is especially important for intercampus interoperability. Only data that needs to be private should be made private; objectclass attributes should be publicly visible. Applications expect to see them to make appropriate decisions.
Replication and synchronization: For the most part, faster hardware has been an adequate solution for replication problems.
The primary server should be fully redundant and 24x7. A successful directory deployment will become an extremely heavily used resource, with multi-millions of hits per day. The hardware deployment of directory services should reflect this mission-critical role.
Tree-based replication is a bad idea, and replication based on filtering by rules and attributes is a good idea. Other directories on campus will want subsets of information. For many reasons, from privacy to ensuring that applications use appropriate data, it is best to be careful in replication of directory data. For white pages applications, rather than passing data in simple bulk, it is better to replicate specific entries and attributes, using scripting or metadata tools. On the other hand, until multi-mastering is prevalent, for applications that require directories to be kept synchronized in real time, the delay in getting changes to the replicas that this strategy entails could create serious problems.
The preferred procedure for making directory backups depends on the directory implementation. In some cases, directory products use vendor databases as data repositories, and these products provide for hot backups (no service takedown). If your directory product cannot handle hot backups, make sure you replicate to another machine and perform hot LDIF dumps on both machines. LDIF backups should be preserved on a reasonable schedule similar to that used for normal backups.
Get ready for XML. Currently, LDIF is used as the standard exchange format; in the near future, XML will be used for this and many other purposes.
Groups: A very common need is to create groups, particularly of people. Examples include different types of people associated with a university (faculty, students, staff, alumni), faculty by discipline or tenure status, students by class year or dormitory, and staff by benefit plan. Creating groups is sometimes known as "people picking". There are two sets of issues, one relating to user tools and one relating to storage of information.
Allow users to create groups, but put restrictions on group size and use. For example, one university restricts user-created groups to thirty members, and does not allow them to be used as email lists. On the Web, these groups show up as affiliated attributes, so they can be used for Web access control.
The best way to store group information depends on how the groups will be used. One option, called "dynamic groups", is to include groups as a (commonly multivalue) schema attribute for individuals. Any dynamic group can be created using an LDAP search URL. The other option, called "static groups", is to create a separate entry for groups within the overall directory hierarchy, and store group memberships as attributes. The different approaches provide benefits to different activities, such as determining membership or group creation. Pay close attention to effects that groups may have on performance.
Groups should be in the same namespace as user accounts or email names. There is benefit to being able to use group names in mailing, calendaring and other common activities. The drawback is in depletion of names within the namespace. Another possibility is to form group names by augmenting an owner's user name with a group-specific tag. One school put group names in the same namespace as user names, but distinguished them by a longer name length.
Web access to group lists avoids multivalue problems. To edit group membership, it is best to use a Web-based tool to deal with the multivalued nature of most group issues.
Supply key institutional groups centrally. More commonly-used groups (e.g., class rosters) should be more centrally managed. This avoids wheel-reinventing on the part of group members, and is conducive to proper data administration of the groups.
|
