|
지난 번 글에 이어 RDB 최적화 활용을 위한 주요 핵심 중 첫번째인 “관계형 데이터베이스에 적합하지 못한 DB 설계의 문제” 내용 중에서 필자가 다 피력하지 못한 몇 가지 실례에 대하여 살펴보기로 한다.
DB 설계 시에 적지 않은 고민을 만드는 부분이 바로 컬럼(속성)의 정의라고 할 수 있다. 예를 들어, “고객”이라는 테이블에서 생년월일이라는 속성이 필요하다고 할 때를 가정해보자. 과연 하나의 컬럼으로 생년월일을 관리해야 할지 아니면 생년,생월,생일 3개의 별도의 원자단위 컬럼으로 나누어 정의해야 할지… 등 이와 같은 고민이 대두되는 경우는 실제 상당히 많이 존재한다.
만약 독자가 이러한 상황에서 테이블 설계의 낙점을 찍는 책임자라면 어떻게 결정하여야 하는가 ? 단순한 컬럼 하나의 판단이 뭐가 그리 대단하냐고 할 수 있지만 이러한 컬럼 정의 결정이 향 후 개발되는 시스템에 미치는 영향은 치명적이 될 수도 있음을 상기 사례를 가지고 설명하기로 한다.
먼저 위에서 예로 들은 고객 테이블의 생년월일 이라는 컬럼 정의에 대한 경우를 살펴보자.
데이터모델링 이론상 속성이란 “독립적인 의미를 갖는 원자단위의 정보”라는 것에 대하여는 대부분의 설계자가 주지하고 있는 사안이다. 그러나, 미래를 바라보는 진정한 설계자에게 가장 중요한 핵심 키 포인트는 바로 관리의 목적과 활용의 방향이라는 것이다. 다년간의 DB설계 경험을 갖고 있는 설계자를 대상으로 강의시에 간단한 사례(성명:성+명, 생년월일:생년+생월+생일, 매출일자:매출년도+매출월도+매출일 등)를 통한 속성 정의 기준에 대한 질문을 제시하였을 때, 이에 대하여 정확한 기준을 가지고 답하는 수강자가 많지 않은 것이 현실이다.
여기서도 주문일자, 계약일자 등과 같이 아마 대부분의 독자는 일반적으로 그래왔듯이 하나의 컬럼(속성)인 “생년월일”로 결정하겠다고 할 것이다. 만일 이러한 결정으로 고객의 생년월일을 하나의 컬럼으로 결정하였을 경우를 가정하고 내일(2월20일),모레(2월 21일)에 생일자인 고객을 추출하는 업무 요건을 위해 생년과는 상관없이 생월일 만을 기준으로 조건 사용이 필요할 것이며 다음과 같은 조건 사용이 필요하게 될 것이다.
WHERE substr(생년월일,5,4) between '0220' and '0221'
이러한 SQL 문장으로 인하여 DBMS가 수행하는 일을 추측하여 보자. 500만 대량 고객 테이블에 생년월일 컬럼에 인덱스가 있다고 할지라도 생년월일 컬럼에 함수 가공이 되어 있으니 인덱스를 사용할 수 없으며 어쩔 수 없이 500만 건의 Full Table Scan이 발생할 것이다. 불필요하게 엄청난 DB Block I/O가 발생하면서 결국 100명도 안되는 고객만을 추출하게 될 것이다. 500만건 Full Table Scan 도 억울하지만 더더욱 억울한 것은 500만번 불필요한 SUBSTR(생년월일,5,4) 함수가 수행된다는 사실이다. 정말 생각만 해도 끔찍한 일이 아닌가 ?
고객 테이블에서 생년월일 정보를 관리하고자 하는 목적은 고객의 통용되는 연령정보와 고객 가족의 생일자 하루 이틀 이전에 사전 알림과 축하 메세지를 통하여 고객의 감동과 이어지는 고객의 구매욕구를 자연스럽게 이끌기 위한 목적이었을 것이다. 그렇다면, 답은 명쾌하여 진다.
이러한 상황에서의 정확한 속성 정의 해법은 “생년”과 “생월일” 독립적인 2개의 컬럼(속성)으로 설계하는 방안이다. 그리하여, 보통 통용되는 연령대 판단 기준은 생일자와 상관없이 “생년”만 으로 판단하여 활용하고 또한 업무적으로 자주 활용되는 생일자 판단의 기준은 바로 “생월일” 과 “양/음력”이 되는 것이다.
이러한 상황이라면 위와 같은 목적을 위한 SQL 조건은 아래와 같이 명쾌해지며 인덱스를 활용한 효율적인 엑세스로 인하여 필요한 몇 개의 DB Block 만을 I/O하여 원하는 100여명의 고객을 추출할 수 있을 것이다. 물론 불필요한 SUBSTR 함수 수행도 필요가 없어지게 될 것이다. 이야 말로 一打三皮가 아닌가 ?
WHERE 생월일 between '0720' and '0721'
또 다른 예로 공정관리 시스템에서 사용되는 어느 생산품 테이블에 해당 생산품이 여러 제조 공정을 흘러가게 되며 각각의 공정에 통과한 시점일시를 관리하고자 한다면 투입일시, 성형일시, 도장일시, 검사일시, 등 약 20개에 달하는 공정 시점일시를 각각의 20개의 컬럼으로 설계하는 경우가 있을 수 있으며 다른 한편으로는 이 모든 각 시점일시들을 “발생일시”라는 통합속성 컬럼으로 통분할 수도 있다. “발생일시”라는 통합속성으로 표현할 경우에는 “발생일시(1)”, “발생일시(2)”, … 등 과 같이 제1정규형에 걸려드는 반복속성으로 귀결되어 1:M 관계의 자식(Child) 엔터티인 “발생시점이력” 이라는 추가적인 테이블이 필요로 하게 될 것이다.
그런데 이러한 상황에서 대부분의 설계자들의 일반적인 선입관은 데이터의 건수가 20배 이상으로 늘어나는 것에 대하여는 매우 두려워하는 반면, 하나의 Row(Record)의 가로의 길이가 늘어나는 것(즉, 컬럼의 증가)에 대하여는 별로 두려워하지 않는다는 사실이다. 실제 20개의 컬럼으로 표현할 경우에는 1,000만 건의 데이터이지만 통합속성으로 판단하여 1:M 테이블로 설계할 경우는 M측의 발생시점이력에는 2억 건에 이르는 대량의 데이터가 필요하다는 것은 당연한 사실이다.
하지만, 필자가 이전 논고에서 역설하였듯이 DBMS의 I/O 단위는 File system과 같이 Record가 아닌 DB Block이며 DB Block의 크기는 바로 면적(가로*세로)이라는 사실을 잊어서는 안된다. 각각의 20개의 컬럼으로 설계하였을 경우는 세로의 길이(건수)가 줄을 수 있지만 가로의 길이가 늘어난 것이며, 발생시점이력인 1:M 관계의 M측테이블에서는 세로크기(Rows:데이터건수)는 20배 가량 늘어났으나 가로 길이가 작으므로 전체적인 면적에서는 대동소이하다. 다만 M측 발생시점이력에서 부모의 식별자를 상속받은 PK컬럼의 크기가 건수만큼 중복되어 가로의 크기를 증가시키는 문제는 있지만 이 역시 멀티테이블 클러스터 기법을 이용한 물리적 DB 설계를 한다면 해결할 수 있을 것이다. [그림1]은 설계의 2가지 방안에 대한 표현으로 좌측은 하나의 테이블에 각각의 필요한 시점일시들을 독립적인 컬럼(속성)으로 관리하는 형태이고 우측은 통합속성인 발생일시로 승격시켜 1:M 관계의 발생이력 테이블로 관리하는 형태이다. 관리되는 전체 데이터(차대번호)가 1,000만 건이라면 우측과 같은 상황에서 1측 (차대마스터) 테이블은 동일하게 1,000만 건이며 가로의 길이가 대폭 축소되었지만 M측(발생이력) 테이블(가로의 길이는 작지만 20배에 달하는 세로길이가 늘어난 테이블)이 추가로 탄생하게 된 상황이다.
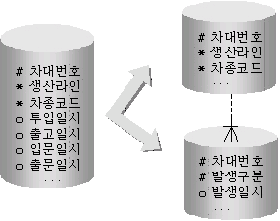
[그림1]
이러한 상황에서 아래 [그림2]와 같이 특정일자에 발생되는 모든 대상 건을 추출하고자 하는 경우를 살펴보자. 즉, 무슨 발생일시이든지 간에 특정일자에 발생된 모든 데이터를 추출하고자 하는 경우이다.
[그림2]
[그림1]의 2가지 테이블 설계 결과에 대하여 [그림2]와 같은 결과를 위한 SQL은 다음 [그림3]과 같이 사용될 것이다.
[그림3]
[그림3]의 좌측 SQL의 경우라면 만족할만한 속도를 위해서는 모든 일시컬럼 20개 컬럼에 각각 인덱스가 있어야(20개의 인덱스) 만이 인덱스 스캔방식의 실행계획이 가능할 것이다. 또한 업무적으로 추가적인 관리시점일시가 필요하게 되거나 공정이 통합되어 관리시점일시가 폐지될 경우에는 컬럼이 추가되거나 삭제되는 설계의 변경이 발생하게 되며 개발된 SQL 역시 수정이 따르게 되는 여러 가지 문제점에 봉착하게 된다. 좌측 SQL의 경우 만일 20개의 일시 인덱스 중에 단하나의 일시컬럼이라도 인덱스가 없다면 “Index-scan OR Index-scan OR… OR Index-scan OR Full-scan = Full-scan” 원리[대용량데이터베이스솔루션2권 4장 참고]에 의하여 1,000만 건의 대량의 테이블을 Full Scan하는 엄청난 일이 발생하게 된다는 사실이다. 하지만 우측 SQL의 경우는 발생이력 테이블에 단 하나의 인덱스(발생일시)만 으로도 원하는 속도를 충분히 보장할 수 있다는 것과 업무적인 변화(관리시점일시의 추가 삭제)가 있다고 하더라도 DB 설계 구조가 바뀌는 것이 아니고 Row(Tuple)의 증감만이 있으므로 업무요구 변화에도 매우 유연하게 대처할 수 있으며 발생일시 시점에 추가적인 부가 속성 정보도 관리할 수 있는 정보의 확장에 매우 유리하다는 것을 이해할 수 있다.
옵티마이징 팩터를 고려한 DB설계라면 또한 컬럼의 값 정의에도 신중을 기하여야 한다는 사실을 마지막 실례로 살펴보자.
판매시스템의 판매전표 테이블에 주문일자, 취소일자, 실판매일자가 있다고 가정하자. 여기서 취소일자와 실판매일자의 Data Value 정의를 어떻게 하여야 되는가 ? 취소일자는 취소된 건만 Setting되고 실판매일자는 판매된 건만 Setting되게 할 경우 업무적으로 특정일자 범위에 취소된 건과 판매된 건의 실적이나 현황을 보고자 할 경우를 살펴보자.
Select sum(decode(sale_dt,null,null,qty)) sale_qty, count(sale_dt) sale_count
Sum(decode(cancel_dt,null,null,qty)) cancel_qty, count(cancel_dt) cancel_dt
From sale_t -- 2,000만건 (5년간 데이터)
Where sale_dt like ‘200202%’
Or cancel_dt like ‘200202%’
해당 SQL의 인덱스 스캔을 위해서는 sale_dt 인덱스도 있어야 하며 cancel_dt 인덱스 역시 각각 별도로 2개의 인덱스가 존재하여야만 한다.
또한 당월 주문건 중 아직 실판매가 되지 않은 건을 위해서는 다음과 같은 조건이 사용되어야 할 것이다. Is null로 비교하기 때문에 MS-SQL이 아닌 경우에는 인덱스 스캔으로는 Null 데이터를 찾을 수 없게 된다. 즉, 당월 주문건이 10만건이라면 10만건의 주문일자 인덱스 스캔을 통하여 테이블 엑세스 한 후 실판매일자가 Null 인 데이터를 추출하므로 결국 10만번 Index Segment와 Table Segment를 Random Access한 후 100건도 안되는 결과를 추출할 것이다. 너무도 억울하지 않은가 ?
Where sale_dt is null and order_dt like ‘200202%’
그러나, 만일 판매일자(sale_dt)의 data value 정의를 Not null로 지정하고 판매되지 않은 건일 경우 ‘99991231’로 Setting하였다면 아래와 같은 SQL로 사용할 수 있으며 인덱스를 하나로 단순화 시키면서도 원하는 동일한 속도를 보장 받을 수 있다. 또한 실판매가 이루어지지 않은 데이터 추출시는 sale_dt = ‘99991231’ 조건을 사용하므로 극소의 데이터를 인덱스에서 빠른 속도로 추출해 낼 수 있을 것이다.
Select sum(decode(sale_dt,null,null,qty)) sale_qty, count(sale_dt) sale_count
Sum(decode(cancel_dt,null,null,qty)) cancel_qty, count(cancel_dt) cancel_dt
From sale_t -- 2,000만건 (5년간 데이터)
Where sale_dt like ‘200202%’
Or (cancel_dt like ‘200202%’and sale_dt = ‘99991231’)
이상의 몇 가지 사례에서 데이터모델링과 DB Design시에 고려해야 될 여러 가지 많은 요소 중에 극히 일부인 컬럼(속성) 설계 기준으로 여러 가지 실례를 들어 설명하였다. 컬럼(속성) 정의의 가장 중요한 기준은 바로 관리의 목적과 활용측면을 고려한 설계가 근간이 되어야 하며 SQL 활용시 적용되는 Optimizing 원리까지 감안한 혜안이 필요하다는 점에 유념하여야 한다.
|
