|
이번 글에서는 RDB 최적화 활용을 위한 주요 핵심 중 두번째인 "RDBMS의 구조 이해와 비절차형 언어인 SQL 활용/응용력 향상"에 대하여 살펴보기로 한다.
지난 번 글에서 언급하였듯이 RDBMS와 File System 환경의 차이를 정확히 익식하여야 만이 RDB최적활용 기준을 터득할 수 있다. File System 환경에서는 I/O의 단위는 Record 이지만 DBMS환경에서는 Record가 아닌 DB Block 이라는 점을 명심하여야 한다. 그리고 RDBMS 환경에서 유일한 DBMS와 개발(사용)자와의 의사소통 도구는 SQL이다. 이 SQL은 기존의 File System환경의 절차형 프로그램 방식과는 다르게 비절차형 집합적 사고로 접근하여야 하는 특성을 가지고 있다.
프로그램 작성시 처리방식이나 로직위주의 프로그램 구사가 필요한 3-GL 언어는 개발자의 프로그램 구사능력이 고성능 프로그램을 탄생시키는 핵심이었으나 SQL은 처리절차나 처리방식을 기술하는 것이 아니며 단순 명확한 정의역과 치역을 정의하면 DBMS Optimizer가 나름대로의 최적 처리방식과 절차를 생성하는데 우리는 이를 일컬어 Optimizing Plan (최적실행계획)이라고 한다. 이렇게 수립된 실행계획들에 따라 수행속도의 차이가 나게 때문에 우리를 공혹스럽게 한다. 즉, 동일한 결과를 나타내는 SQL들은 여러가지 일 수 있으나 수립된 실행계획에 따라 1초의 응답속도를 나타낼 수도 있으며 1,000초가 되어도 결과를 보여주지 못하는 경우도 있을 수 있다는 예기이다.
즉, RDBMS환경에서는 대부분의 골치아프고 어려운 부분의 역할을 DBMS가 대신하여 고민하고 처리하여 주므로 DBMS의 Optimizer의 특성과 활용 기준을 정확히 알고 있으면 동일한 DBMS 환경이라 할지라도 가장 효율적이고 효과적인 소득을 얻을 수 있다는 사실이다. 그리고 이 귀중한 역할을 맡고있는 DBMS Optimizer는 하루가 다르게 발전을 거듭하여 거의 인공지능에 가까운 능력으로 발전을 하고 있으며 이러한 Optimizer 기능 발전 추세를 잘 이해하고 따라가야만이 고비용을 지불하고 도입한 DBMS를 효율적으로 활용할 수 있으며 우리(개발자/사용자)가 편해지게 된다는 것이다.
DBMS환경에서의 고성능 시스템 구축을 위해서는 DBMS Call을 줄여야 하며 I/O 효율을 위해서는 Random Block I/O를 줄여야 한다. DBMS Call 한번 발생은 인간이 느낄 수 없는 정도의 미미한 시간(0.001)이며 시스템 부하도 극히 미미할 것이다. 권투경기에서 별 충격이 없는 잽이라 하더라도 이러한 잽을 수만번 맞게 되면 아무리 맺집이 있는 선수라 하더라도 무기력해지게 마련이다. 이렇듯이 미미한 타격(DBMS Call)도 수 십만번 반복된다면 눈덩어리 처럼 불어나 엄청난 타격을 입힐 수 있다는 사실을 상기하여야 한다.
어느 시스템에서 2가지의 다음과 같은 응용프로그램이 존재한다고 가정하자. 하나는 하루에도 수만번 수행되는 영업 판매 시스템의 Mission Critical Application인 "Prog1"이며 다른 하나는 하루에 한두번 사용되는 판매일보와 같은 Application인 "Prog2"이다. "prog1"의 SQL은 현재 0.01초 정도의 응답속도를 보장하고 있으며 "Prog2"는 30초 정도의 응답속도를 나타내고 있는 상황이다. 그렇다면 여러분은 어떠한 프로그램에 대한 튜닝을 실시해야 된다고 판단하는가 ? 당연히 "Prog1"이다. 절대적인 판단기준으로는 30초나 걸리는 "Prog2"에 대한 튜닝이 시급하다고 생각할 지 모르나 0.01초의 양호한 성능을 보이는 "Prog1"을 좀 더 적극적인 튜닝을 실시하여 0.001초로 튜닝한다면 업무적으로 매우 많이 수행되는 Mission Critical Program인 "Prog1"의 튜닝 효과로 인하여 시스템 전체에 미치는 성능 개선도와 시스템 효율 향상도는 엄청날 것이다. 수치적인 성능개선도에 대한 판단을 하더라도 0.009초가 개선되며 이러한 개선도가 매일 100만번 반복 수행된다면 0.009*1,000,000 이라는 속도 개선 효과가 발생되어 결국은 해당 프로그램의 응답속도는 9,000초의 속도 개선 효과를 얻게 되며 시스템 전반적으로 그만한 성능개선 효과가 창출되다는 것이다.
그럼, DBMS Call을 최소화 하며 원하는 결과를 얻을 수 있는 기법은 무었인가 ? 바로 집합적 개념의 한방의 고급 SQL을 구사하는 것이다.
대부분의 개발자들이 작성한 프로그램의 내부를 확인하여 보면 DBMS를 마치 Data의 저장소 역할로만 생각하고 기존에 사용하여 왔던 File System 환경과 같이 SQL은 Read & Write하는 Statement 정도로 사용하고 있다. 그러다 보니 10만건의 데이터를 엑세스(추출)하여 20여건의 최종 결과를 얻고자하는 정보 조회화면을 위한 프로그램에서 10만번 Select Fetch를 반복하여 수행하고 로직에서 If … Then … Else … 형태의 제어와 연산등을 통하여 원하는 결과를 완성하게 된다.
DBMS는 File System과 같이 데이터를 저장하는 역할만 하는 단순한 제품이 아니고 우리가 생각하는 이상의 고급 지능을 가지고 주인님(?)이 원하는 결과를 위하여 나름대로의 최적화 방안을 적용하고 정확한 결과를 최단시간에 수행하려고 노력하는 역할까지 해내는 인공지능과 같은 옵티마이져를 가진 생명체와 같다. 때문에 SQL은 단순한 명령문(Statement) 수준이 아닌 수백 줄의 응용프로그램을 대신할 수 있는 하나의 응용프로그램(Application) 이라고 이해하고 활용하여야 한다. 즉, 수백줄의 절차형 프로그램을 단 10여 줄의 SQL로 대신할 수 있으며 10만번의 DBMS Call (SQL Execution)을 단 한번의 DBMS Call이 가능한 한방의 SQL로 100배 이상의 속도를 보장할 수도 있다.
불필요한 반복적인 DBMS Call은 수행속도면에서도 많은 불리함이 있지만 시스템의 전반적인 성능을 저하시키는데도 한몫을 담당한다. 위에서 언급한 대로 20여 줄의 결과를 얻기 위하여 Client Server 환경에서 Client Program이 10만번 Select Fetch를 반복하여 DBMS Call을 한다고 생각해 보자, 10만번 Fetch라는 DBMS Call이 Client에서 Server측에 N/W을 통하여 전달되었을 것이며 다시 Server측에서는 Client에서 요청한대로 1건씩 10만번 N/W을 통하여 Client에게 전달했을 것이다. 그야말로 엄청난 N/W Traffic이 발생하였으며 결국 Client에서는 N/W통하여 전달받은 10만번의 Fetch된 데이터를 가지고 프로그램 로직을 타면서 Filtering과 연산작업을 Client PC에서 열심히 수행한 다음 결과를 20여 줄 요약하여 보여 줄 것이다. 즉, 이러한 프로그램 형태는 전체일량의 처리의 주체가 DB Server가 아닌 PC급의 Client가 되어 버렸다. 아무리 PC 성능이 좋다고 DB Server의 처리 성능보다는 부족할 것이며 너무도 많은 N/W 부하를 유발시키는 끔찍한 범죄가 발생한다는 사실을 명심하여야 된다.
아무리 좋은 비밀병기를 도입하였다고 하더라도 사용방법과 활용기준을 모르고서는 한낱 고철덩어리에 불과하다. 우리는 이미 IT분야의 핵심 부문에 있어서 최첨단 무기인 RDBMS를 고비용을 지불하고 도입하였다. 그러나 이러한 최첨단 비밀병기를 제대로 알지 못하고 자유당 때 시절의 단순한 K1 소총 정도로만 사용하고 있다는 사실이 도처에 널려있으며 이러한 현실은 필자를 참으로 슬프게 한다.
또한 고급의 한방 SQL로 된 응용프로그램은 업무의 변화나 DB설계의 변화에 유연하게 대처할 수 있으며 성능개선(튜닝) 작업에서도 매우 간단한 개선(옵티마이져 힌트, 인덱스 전략 조정, 등)만으로도 수백배 성능개선을 할 수 있기 때문에 유지보수 관리측면에서도 매우 유리하다는 사실이다. 대부분의 독자는 이 부분에 대하여 의문을 다는 경우가 많다. 이유는 기존의 3GL 절차형 프로그램 방식에서 대부분이 절차형 로직구사 환경에서 단순 Select into 형태는 그동안 적응이되어 있고 지금까지의 학습된 전산 학문의 프로그래밍 언어가 절차형 프로그램 방식이었기에 오히려 이해하기가 편하다고 주장하는 경우가 많다. 집합적인 사고에 익숙하지 않은 전산인력은 오히려 고급기능의 한방의 Super SQL을 접하는 경우 마치 딴나라 세상의 언어를 대하는 것 처럼 어렵다고 생각하기 쉽다는 예기이다. 그러나, 필자가 접해온 수많은 고객사에서 같이 일해온 많은 개발자와 업무담당자들의 예를 보면 그렇지 않다는 사실을 입증해 준다. 모든 일이 그렇듯이 모르는 세상에서 처음 접하는 어려움은 누구나 마찬가지 이지만 어느정도 몸에 익히기 손에 익고 자신도 모르게 RDBMS에 가까운 집합적 개념의 한방의 SQL에 친숙해지다 보면 이제는 정 반대의 현상이 벌어진다. "왜 이리 복잡하게 소설 같은 3-GL 언어로 프로그램을 하느냐 ? 이 편한 SQL이 있는데 … " 라고 자연스러운 반응이 나타나게 된다. 즉, "어느 환경에 먼저 친해져 있는냐 ?" 라는 극히 자연적인 현상이라는 사실이다.
실례로 다음 [그림1]과 같은 결과를 얻고자 하는 프로그램에 대한 논해보자.
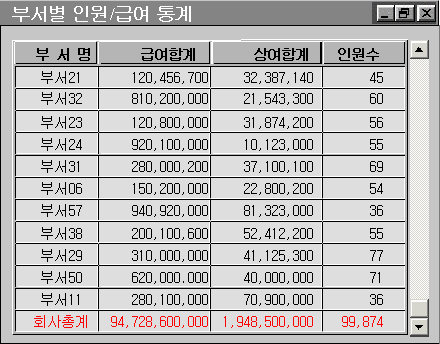
[그림1]
상기 [그림1]의 결과를 얻기 위해 단순한 Read 명령과 같은 수준의 3GL Style의 프로그램 형태는 다음 [그림2]와 같다.
[그림2]
본 논고의 목적상 극한 경우의 예를 들었지만 상기 [그림2]에서 제시된 프로그램에서는 사원테이블(10만건)과 부서테이블(100건)을 단순 EQUI-JOIN을 통하여(부서명칭은 부서테이블에 있으므로) 10만건의 데이터를 부서별로 Grouping하기 위하여 결과를 부서별로 정렬을 시킨 Select SQL을 수행하고 (Declare Cursor 후 Open Cursor) Loop Fetch를 이용하여 10만번 Fetch 하면서 부서별 인원 및 급여의 합계를 위하여 부서별 누계를 위한 변수에 연산을 하고 전체 회사계를 위한 누계변수에도 역시 같이 연산을 해 가다가 이전에 읽힌 부서하고 비교한 후 부서가 바뀌면 그동안 연산되었던 부서별 누계 계산값을 화면의 출력 변수에 옮겨주고 또다시 부서별 누계 연산을 위한 변수를 초기화 시키고 앞에서 수행한 일들을 반복해 나간다. 이러한 부서별 누적 계산이 끝나는 시점(Fetch할 데이터가 없을 경우)에는 그동안 계속 누적해왔던 전체 회사계를 위한 누적 변수값의 정보들을 맨 마지막 총계 줄에 출력하게 한다.
이상과 같은 프로그램에서 두가지 측면의 문제점을 지적해 보자. 첫째 비효율은 앞에서 언급한 DBMS Call의 부하로 10만번의 DBMS Call(Fetch)을 발생시켰다는 문제점이다. 이러한 문제점은 Client Server 환경이라면 앞에서 언급한 대로 N/W 부하측면에서도 10만번의 불필요한 N/W 부하를 발생시켰을 것이다. 두번째 비효율은 사용된 JOIN SQL의 비효율이다. 사원과 부서는 M:1 관계에 있으며 이를 그대로 JOIN을 수행할 경우 결과가 10만건에 해당하는 결과가 나오며 이러한 조인에서 조인에 참여하는 대상집합은 10만건이 된다. 조인을 하는 목적은 부서의 명칭 때문인데 부서명칭을 가지고 있는 집합은 100건 밖에 되지 않으며 원하는 결과 정보 역시 최대 부서건수 만큼의 Row밖에 나올 수 없다. 그렇다면 10만건 집합의 조인이 불필요하다는 예기이다. 즉, 최대 100건의 집합으로 조인을 하면 된다는 예기이다.
다음 [그림3]은 이상의 목적을 위한 SQL위주로 작성된 간단한 한방의 SQL이다. 본 SQL문장 하나로 우리가 얻고자하는 최종 목적 집합을 모두다 얻어서 그대로 출력할 수 있다. 즉, DBMS Call 한번과 Array Fetch 한번으로 부서별 통계와 마지막 회사전체 총계까지 단 하나의 SQL 수행으로 원하는 결과를 얻을 수 있다. 이러한 내용의 SQL 확장 기능을 설명하다보면 흔히 독자들이 이러한 SQL 테크닉은 오라클에서만 가능한 방법이라고 착각하는 경향이 있어 한방의 SQL 예제를 MS-SQL 환경에서도 구사할 수 있다는 실례를 들기 위하여 오른쪽의 예제는 MS-SQL에서 사용하는 SQL로 표현하여 보았다. 이러한 SQL 테크닉은 집합의 복제기법을 이용하여 활용하는 방법이므로 DBMS 제품과는 상관없이 활용할 수 있는 매우 유용한 기법으로 대용량데이터베이스솔루션 2권의 2장의 "다양한 데이터 연결방법"에 상세히 언급하여 두었으니 참고하도록 하자.
[그림3]
상기 [그림3]의 SQL은 단 한번의 SQL 수행(DBMS Call)으로 원하는 결과를 그대로 추출할 수 있도록 하며 Client에서 해당 SQL 한번 수행 요청만 하면 DB Server에서 모든 처리를 하여 최종 목적 집합인 부서별 통계정보와 맨 마지막 줄에 회사전체총계 까지 구하여 Client에는 몇십 줄(90종류의 부서건이라면 91줄)의 최종 결과만 Client로 전달되게 될 것이며 Client에서는 별다른 로직이 있을 필요가 없게 된다. 물론 이로 인하여 N/W 부하 역시 획기적으로 줄어들게 될 것이다.
또한 DB Server에서 처리하는 방식에 있어서도 불필요한 조인을 최소화 시키기 위하여 먼저 다량의 사원 테이블을 목적집합 레벨인 부서번호 레벨로 Group By시켜 X 집합으로 치환시킨 다음 부서레벨로 Grouping되어 줄어든 X집합과 부서테이블을 1:1 조인으로 조인하였다. 즉, 10만건 사원집합의 조인 일량이 발생한 것이 아니라 부서레벨의 조인만 발생하여 조인의 일량이 대폭 절감되었다. 조인의 일량이 대폭 줄어들었지만 우리가 원하는 결과 집합은 동일하게 된다.
그리고 회사총계를 구하는기 위하여 프로그램에서 누적 연산을 시키는 방식이 아니라 집합의 곱(Cartesian Product) 원리를 응용하여 원래 집합을 단 두건의 Row를 갖는 임의의 집합과 조인 조건이 없는 "묻지마라 조인"을 시켜서 하나는 자기자신을 지키는데 사용하고 다른 하나는 총계를 구하는데 사용하도록 통분하여 Group by sum을 구하면 우리가 원하는 목적 결과를 단 하나의 SQL로 구현하면서 가장 최적의 속도를 얻을 수 있다.
지금까지 언급한 것은 극히 빙산의 일부이다. 그야말로 RDBMS 능력을 최대로 활용하는 고급 SQL테크닉은 무수히 많고 한계도 없다. 우리들은 이미 초음속으로 날아다니는 항공 우주 시대를 살고 있으며 비싼 비용을 들여 고성능 초음속 비행기를 구입하여 놓은 상황이다. 그러나 서울에서 러시아 모스코바를 가기 위하여 자전거를 타고 간다는 것이 말이 되는가 ?
더 이상의 언급을 하기에는 논고의 한계가 있어 줄이기로 한다. 다시 한번 강조하지만 고성능 DBMS 환경의 핵심의 중요한 한축은 바로 RDBMS를 최대로 활용할 수 있는 RDBMS에 대한 정확한 이해와 RDBMS에 적합한 최적의 집합적 사고의 고성능 SQL 구사능력이라 점을 명심하도록 하자.
다음 주에는 고성능 시스템을 위한 3요소 중 마지막 편으로 시스템 성능의 최대 영향요소의 핵심인 I/O 성능 보장을 위한 엑세스 효율이라는 주제를 가지고 만나기로 하자.
|
