|
이번 글에서는 RDB 최적화 활용을 위한 주요 핵심 중 마지막으로 "I/O (엑세스)와 실행계획의 비효율 개선을 통한 최적화"에 대하여 살펴보기로 한다.
시스템의 성능의 가장 치명적인 부분은 바로 I/O 부분이다. 우리가 흔히 알고 있듯이 CPU나 Memory에서 소요하는 시간보다 네트웍 I/O나 디스크 I/O에서 소요하는 시간이 대부분을 차지하므로 시스템 성능을 저하시키는 주범은 바로 I/O이며 고성능 시스템을 위해서는 이 I/O 효율을 개선해야 된다.
이러한 I/O 효율 중 네트웍에 관한 영역은 생략하기로 하고 본 글에서는 데이터 서비스를 위한 디스크 I/O에 대한 효율 영역으로 국한하여 설명하기로 한다.
대부분의 시스템에서 I/O 성능개선을 위하여 물리적인 디스크 엑세스를 줄이고자 메모리 역역에 자주 엑세스되는 데이터 영역(Block)을 잠시 보관하여 동일한 Block을 요구할 경우 물리적인 디스크 엑세스하지 않고 메모리(Cache)에 존재하는 Block을 서비스하고 있다. DBMS 역시 마찬가지로 이러한 공간을 확보하여 서비스하고 있으며 이러한 영역을 DB Block Buffer 또는 DB Cache 등 이라고 불리어지고 있다.
Query의 수행속도는 원하는 정보 서비스를 위하여 얼마나 불필요한 DB Block 엑세스를 하지 않고 정확히 필요한 최소의 DB Block만을 엑세스할 수 있느냐가 관건이다.
만일 200만건의 고객테이블에서 미성년자(19세 미만)만을 추출하고자 하는 업무 요건이 있다고 가정하자 우리가 관리하고 있는 고객의 대부분(99%)는 성인인데 극히 일부가 미성년자이기 때문에 이러한 미성년자는 200만 회원 중에 100명 정도이며 이러한 100명을 추출하기 위해 전체 테이블을 읽으면서 생년을 일일이 비교하며 찾는다면 결국은 100명을 찾기 위해 200만건을 모두 엑세스하여야 될것이다. 즉 만건을 읽었을 때 한명 정도의 미성년자가 골라진다는 예기이다. 이렇게 원하는 정보에 비하여 불필요한 Block을 많이 엑세스할 경우 바로 I/O비효율이 많이 발생한다는 예기이다. 이럴 경우 우리는 인덱스라는 무기를 사용하여 I/O 효율을 높이고자 한다. 즉, 생년이라는 컬럼에 인덱스를 생성하고서 동일한 Query를 수행할 경우 이제 옵티마이져는 조건 비교 컬럼(birth_year < 1983)에 인덱스가 있으므로 인덱스 스캔을 통하여 19세 미만인 건들만을 엑세스하므로 원하는 DB Block들만을 최소화하여 I/O 효율을 높이게 되는 것이다.
SQL이란 처리절차를 기술한 것이 아니라 정의역과 치역만을 선언되고 관계만이 표현되는 비절차형 언어이며 옵티마이저의 판단에 의하여 엑세스방식과 처리방식이 결정되므로 인덱스가 있다고 하여 무조건 인덱스를 사용하는 것도 아니며 사용된 인덱스의 효율과 사용된 조건의 형태에 따라 인덱스를 사용하여서 더욱 I/O 효율이 저하되는 경우도 있다는 사실을 명심하여야 한다. 즉, 인덱스 스캔만 하면 빠르다고 착각하고 있는 사람들도 적지않다.
엑세스 효율화에 대한 설명을 위하여 다음 [그림1]의 사례를 가지고 설명한다.
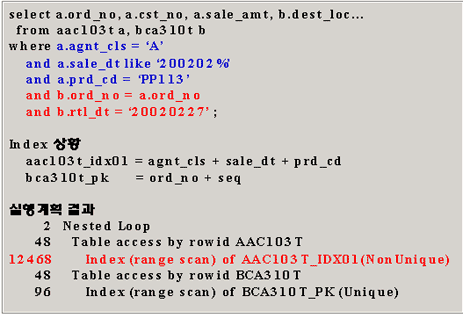
[그림1]
위 [그림1]에서 사용된 SQL문에는 여러가지 조건이 있으며 2개의 테이블에 대한 조인문장이면서 각각 테이블에 조건이 존재하고 있다. 그리고 현재 본 SQL에 대한 실행계획이 그림의 아래 부분에 나타나 있으며 현재 사용되어진 인덱스 상황이 그림 중간에 표현되어 있다.
본 조인 SQL에서 드라이빙(선처리) 테이블은 aa103t가 되었으며 그 이유는 조건에 나타난 agnt_cls = 과 sale_dt like 그리고 prd_cd = 3개의 조건 컬럼이 바로 결합인덱스 aa103t_idx01 의 컬럼 3개로 구성되어 있으며 첫번째 인덱스 컬럼인 agnt_cls가 = 조건으로 사용되어 있어 처리주관 인덱스로 결정되었다. 그러나 아래 실행계획의 access rows 결과를 보면 인덱스 엑세스의 비효율이 많이 발생되었다. 최종적으로 얻게되는 결과는 조인된 최종 결과(모든 조건을 만족한 치역) 2건 밖에 되지 않는다는 사실이다. 즉 2건의 결과를 얻기 위하여 처음 일량이 aac103t_idx01에서 12468 row를 엑세스하였으며 인덱스 컬럼들의 조건(3가지 조건)에 만족하는 결과가 48건이 되어 48번 bca310t 테이블의 PK로 조인을 하였으며 bca310t_pk 인덱스 컬럼(ord_no + seq) 중 ord_no만 aac103t가 먼저 읽혀 상수화된 ord_no로 찾아갔으니(seq 조건은 없음) bca310t_pk가 Unique Index일지라도 range scan하므로 +1 scan을 하여 96 rows를 bca130t_pk에서 엑세스 되었으며 rowid로 48건을 bca130t 테이블로 엑세스하여 테이블에서 체크할 수 있는 조건(rtl_dt = '20020227')을 비교하고 만족하는 결과가 2건이 나오게 된 것이다.
그렇다면 위 [그림1]의 예제에서 가장 똑똑한 조건은 무었이었을까 ? 현재로서는 드라이빙 테이블이 aac103t가 되었지만 오히려 bca310t의 rtl_dt = '20020227' 조건이 선처리 조건으로 드라이빙 되었더라면 하는 생각이 들지 않은가 ? rtl_dt = '20020227' 조건으로 걸리는 데이터가 20건 정도로 결정적으로 데이터량을 줄여준다면 bca310t가 당연히 선처리(드라이빙) 테이블이 되어야 될것이다. 그럼, 그렇게 하기 위해서는 어떻게 하여야 하나 ? 옵티마이져가 그렇게 판단할 수 있도록 aac103t_idx01 인덱스만 있는게 아니고 bca310t에 rtl_dt가 인덱스 선행 컬럼으로 되어있는 인덱스 전략을 수립하여 옵티마이져가 rtl_dt 조건이 선행처리 인덱스로 사용할 수 있도록 해주어야 한다. 즉, 지금까지는 긴칼 하나를 무기로 사용하고 있었지만 또다른 총 같은 무기가 있다고 옵티마이져에게 알려주어야 될 것이다. 이러한 사실은, 엑세스 효율화를 위한 중요한 원리인 똑똑하고 힘있는 능력있는 여당이 힘을 발휘할 수 있다는 대용량데이터베이스솔루션2권 4장 내용에 해당되는 예기이다. 본 JOIN SQL문장에는 aac103t가 일의 출발일량을 결정하는 여당에 해당되며 bca310t는 나머지 체크조건이 들어있는 야당이라고 할 수 있다. 이렇게 똑똑한 힘을 가지고 있는 야당을 여당으로 바꾸려면 인덱스의 전략 조정으로 옵티마이져의 길을 바르게 유도하여야 한다.
[그림1]의 선처리주관인덱스 aac103t_idx01를 엑세스한 rows는 12,468건이라는 적지않은 rows를 엑세스하였으나 인덱스를 엑세스한 후 실제 aac103t 테이블에 엑세스한 rows는 불과 48건 밖에 안된다. 여기서 우리는 중요한 사실을 알 수 있다. 얼핏보면 3개의 컬럼 조건이 모두 조건에 있으니 완벽한 인덱스 전략이라고 생각하기 쉽지만 이렇게 인덱스 스캔의 비효율이 발생하여 결정적인 실수를 범한 SQL이다.
이유는 간단하다. B*Tree Index 구조상 aac103t_idx01 인덱스는 agnt_cls별로 정렬되어지고 agnt_cls가 같다면 다음으로 sale_dt별로 정렬되어 있으며 sale_dt도 동일하다면 다음으로 prd_cd별로 정렬되어 있으니 위에서 주어진 조건 상황에서 인덱스를 스캔할 수 있는 범위는 agnt_cls='A' and sale_dt like '200202%'가 된다. 즉, 결정적으로 48건으로 줄여주는 똑똑한 능력있는 조건인 prd_cd = 'PP113' 조건은 인덱스 스캔의 범위를 줄여주는 역할을 하지 못하고 인덱스 스캔 과정에서 단지 체크조건 역할만을 하였다. 이로 인하여 인덱스에서 읽을 필요가 없는 prd_cd 가 'PP113'이 아닌 인덱스 row들도 모두 엑세스하여 인덱스 엑세스 효율이 최악이 되었다. 이러한 상황을 두고 우리는 대용량데이터베이스솔루션 2권 4장에서 언급한 주류와 비주류 개념을 이해할 수 있다. 여당(aac103t_idx01 의 3개 컬럼 조건)내에서도 agnt_cls조건과 sale_dt 조건은 여당내에 주류에 해당되며 prd_cd 조건은 여당내의 비주류에 해당된다. 이렇게 인덱스 스캔의 범위를 줄여주는 역할을 못하는 당내 비주류를 주류로 끌어들이는 기법을 바로 "다리는 놓아주는 기법"이라고 한다.
위에 기술된 SQL을 아래와 같이 바꾸어 사용하게 되면 비주류 조건이었던 똑똑한 prd_cd = 조건까지도 주류로 끌여들여서 인덱스 스캔의 범위를 대폭 줄여줄 수 있다.
select a.ord_no, a.cst_no, a.sale_amt, b.dest_loc…
from aac103t a, bca310t b
where a.agnt_cls = 'A'
and a.sale_dt in ( '20020201','20020202','20020203',…'20020228'
and a.prd_cd = 'PP113'
and b.ord_no = a.ord_no
and b.rtl_dt = '20020227'
우리가 학창시절에 배운 집합연산에서 드모르강법칙을 상기해보자. A ∩ (B ∪ C ∪ D) 는 다시 풀어서 (A ∩ B) ∪ (A ∩ C) ∪ (A ∩ D) 로 적용할 수 있다. 이러한 드모르강법칙을 이용하여 위의 연산자 조건을 풀어보면 in list 조건은 여러 개의 OR 조건이므로 28개의 일자의 OR 조건을 다시 변환 적용하면 3개 컬럼의 AND 조건의 28개의 단위들이 OR 조건으로 바뀌어질 수 있다. 이러한 기법의 실행계획을 Concatenation 또는 InList Iterator 실행계획이라고 한다.
위 SQL에서는 "sale_dt in (상수들) " 으로 사용되었으니 sale_dt조건이 Like 선분 조건이 아닌 28개의 = 조건으로 바뀌었으며 이로 인하여 3개의 컬럼 조건이 모두 =비교 조건으로 하여 28개의 OR(Concatenation Plan) 실행계획이 수립되게 되어 결국 prd_cd = 'PP113' 인 인덱스 Row만을 aac103t_idx01 인덱스에서 엑세스하게 되며 결정적인 엑세스 비효율 부분이 손쉽게 해결된다. 물론 일자를 위와 같이 in 조건으로 일일이 다 나열하는 방법은 사용하기 어렵기에 창출한 임의의 집합으로 공급하는 방법을 사용하여야 한다. 이러한 구체적인 응용방법은 대용량데이터베이스솔루션 2권 4장을 참고하기 바란다.
그럼, 실행계획의 비효율과 I/O 효율 개선을 위한 좋은 실례를 살펴보도록 하자.
다음 [그림2]는 어느 고객사의 SQL과 인덱스 상황과 실행계획 그리고 실행계획 단계별 처리 rows를 표현한 실례이다.
[그림2]
매우 평범한 JOIN SQL문장이다. 결국은 18건의 결과를 추출하기 위한 SQL문인데 실제적으로 일량의 출발이 TAB950 테이블의 전체건수인 187,718 rows를 Full scan하여 출발되었으며 해당 테이블의 조건 (D_DAY = , PART_CODE between)에 의하여 골라진 결과가 18건이 되었으며 먼저 읽힌TAB950테이블의 정보가 상수화 되어 공급되는 PART_CODE와 TEAM_CODE를 받아서 TAB130의 PK로 Unique Key 엑세스가 18번 시도되었으며 18건 모두 TAB130 연결에 성공하여 18건의 결과가 나타났다는 상황이다.
여기서도 바로 여당측(드라이빙) 엑세스 비효율이 발생하였다. 이유는 조인의 연결고리인 PART_CODE와 TEAM_CODE 컬럼에서 TAB130측에서는 두개의 연결고리 컬럼에 Unique Index가 존재하였으나 TAB950테이블에는 해당 두개의 컬럼이 인덱스의 선두컬럼으로 나타나지 않아 연결고리 이상(조인의 연결 컬럼에 사용할 수 있는 인덱스가 존재하지 않는 경우)상황이 발생하여 옵티마이져는 선처리(드라이빙) 테이블을 TAB950으로 결정하였다. 이런 상황에서 TAB950측의 두가지 상수 부여조건 컬럼인 D_DAY = 조건과 PART_CODE between 조건으로 사용할 수 있는 인덱스가 없으니 어쩔 수 없이 TAB950을 Full Scan할 수 밖에 없었던 것이다.
그렇다면 단 이 하나의 SQL만을 위한 최적의 인덱스 전략과 최적의 실행계획을 여러분 스스로 한번 고민하여 보라. 물론 인덱스 전략은 단 하나의 문제 SQL만을 고려하여 인덱스 전략을 수립해서는 절대 안된다. 해당 테이블을 사용하는 모든 SQL문을 추출하여 모든 SQL문의 엑세스 경로를 상세하게 분석하고 모든 SQL을 골고루 만족시키는 최소의 최적 인덱스 전략을 수립해야 하기 때문이다. 하지만 본 논고의 성격상 본 SQL 하나만을 위한 최적의 인덱스 전략과 실행계획을 고려해 보면 다음 [그림3]과 같은 결론을 만들어 낼 수 있다.
[그림3]
두개 테이블의 PK 인덱스 컬럼 순서를 위의 [그림3]과 같이 변경하면서 SQL 조건에 부여된 A.PART_CODE between 조건을 B.PART_CODE 조건으로 바꾸면(조인의 연결고리 컬럼이면서 Equal 조건이므로 PART_CODE는 어느쪽 테이블 컬럼 조건으로 주어도 결과는 동일하기 때문) 자연스럽게 1:M관계 테이블 중 1측의 TAB130을 꼭 필요한 Rows만을 최적으로 인덱스 스캔하여 선처리하고 M측의 TAB950은 TAB130에서 상수로 공급되는 TEAM_CODE와 PART_CODE 그리고 D_DAY까지 = 조건으로 결합인덱스 앞 3개 컬럼을 최적으로 엔세스하여 조인되므로 가장 최적의 인덱스 전략이며 최적의 SQL과 실행계획이라고 할 수 있다.
이처럼 인덱스의 전략 조정과 SQL의 단하나 문자만을 바꾸더라도 실행계획이 바뀌게 되며 처리속도는 100배에 가까운 속도개선이 가능하다.
지금까지 4차례의 논고를 통하여 고성능 시스템 구축의 핵심인 데이터베이스 성능 보장을 위한 핵심 3요소에 대하여 개략적인 서론을 다루어 왔다.
이제 다음 논고부터는 DB튜닝을 위한 실전 테크닉을 위한 각 요소별 구체적인 사례와 함께 실전지침을 당사 전문 컨설턴트에 의해 지속적으로 논고를 게재할 예정이니 많은 관심과 함께 여러분의 IT원천 기술력 함양에 도움이 되기를 바랍니다.
|
