|
Data Warehouse 환경에서의 Star Transformation 기술 활용 - An Application to Bitmap Indexing
본 글에서는 Star Transformation 기술의 수행 환경인 Data Warehouse(DW), Data Marts, Star Schema 개념을 먼저 살펴 보고, 다음으로 Bitmap Index가 기반 기술인 Star Transformation을 설명한다. 그리고, 마지막으로 Star Transformation의 성능을 다른 조인 방식과 비교하는 테스트를 수행하고 그 결과 자료를 공개하였다.
Episode I : DW, EDW and Data Marts
Data Warehouse(이하 DW)는 일종의 정보시스템으로서 각종 소프트웨어 및 하드웨어, 운영자, 운영 프로세스, 구현된 비즈니스 프로세스, 네트웍, 데이터베이스 등 유무형의 구성요소를 포함한다. 하지만, 실무에서는 특정의 데이터 저장소 혹은 그런 저장소들의 집합이 'DW'로 지칭되는 경우가 보다 일반적이다. "XX 정보는 운영계 시스템 보다는 'DW'에서 가져 오는 것이 좋습니다", "YY 레포트는 'DW'에서 뽑아야 합니다. 그렇지 않으면 통계 간 불일치가 발생할 수 있지요!", "분석 CRM의 데이터 Source는 대부분 'DW'에서 획득가능한데, 일부 데이타는 운영계 시스템에서 매일 직접 가져와야 합니다." 등과 같은 이야기를 주고 받을 수 있는데, 이때의 'DW'는 구체적인 데이터 저장소를 지칭하는 것이다.
DW의 구성 요소 혹은 또 다른 명칭으로서 흔히 사용되는 것으로 1) ODS, 2) Enterprise DW(EDW), 3) Data Marts(Dependent Data Marts) 등이 있는데, 데이터 모델 관점에서 비교하면, 첫번째, 1)은 정규화 된 여러 운영계 시스템의 통합되고 current한 데이터 모델을 가지며, 두번째, 2)의 경우 1)과 마찬가지로 정규화 되었고 데이터의 중복을 쉽게 허용하지 않는 반면 운영계 시스템(혹은 ODS) 데이터를 포함해 수집/분석 가능한 데이터를 주제 중심적으로 재배열 한 것이며, 마지막 3)의 경우 보다 뚜렷한 데이터 사용 목적과 분석의 용이성을 위해, 데이터 모델은 비정규화 되고 여러 Data Mart간 데이터 반복이 쉽게 허용된다. 실제 상당수의 DW 구축 사례는 EDW 구축의 고위험을 회피하기 위해 주제 영역별로 독자적인 Data Marts(Independent Data Marts)를 구축한 후, Data Marts를 통합함으로써 DW를 완성해 가는 것이다. 그런데, 그러한 구축 방법론은 통합 데이터의 필요성 및 통합 노력을 과소평가하였다고 볼 수 있는데, 한 연구 분석에 따르면 EDW를 데이터 Source로 하지 않는 Independent Data Marts는 EDW를 데이터 Source로 하는 Dependent Data Marts에 비해, 구축 과정에서는 약 3배, 유지보수 및 사용 과정에서는 약 2배의 비용이 소요됨을 주지시킨다(W.H. Inmon, Independent Data Marts Vs. Dependent Data Marts: The Issues, The Economics, 1999).
보다 최근의 DW 구축 방법론으로는 EDW 구축의 고위험을 회피하면서도 통합 비용을 낮추도록 하는 것인데, 이는 ODS를 각 주제 중심적인 Dependent Data Marts의 데이터 Source, 즉, EDW의 초기 데이터 모델로서 그 기능을 확대 수행하도록 하는 것이다. 이때 ODS는 이력관리 등을 통해 비휘발성(non-volatile)을 유지하여야 한다.
Episode II: Star Schema(Star Joins), Star Query and Star Transformation
DW의 가장 큰 특징 중 하나는 '주제 중심적(Subject-oriented)'이란 것이다. 예를 들어, DW에서는 '자동차보험', '생명보험', '건강보험', '화재보험' 등 횡적인 업무로 구분되어 구축 및 유지보수 되고 있는 운영계 시스템을 '고객', '보험증권', '보험료', '보험금청구' 등과 같은 종적인 주제 별로 엔터티를 통합 및 재 배열함으로써 분석 목적을 충족 시키고, 이에 더하여 Data Marts(Detail Data Marts and Summary Data Marts)는 분석가 혹은 사용자 입장에서 보다 더 구체적이고 사용이 용이한 주제 영역을 제시한다.
Star Schema(혹은 Star Joins)는 정규화된 여러 엔터티에 흩어져 존재하는 분석 대상과 그 대상의 속성을 비정규화된 Fact 테이블과 Dimension 테이블로 명확히 분리한 물리 데이터 모델이다[그림 1].
[그림 1 : Star Schema]
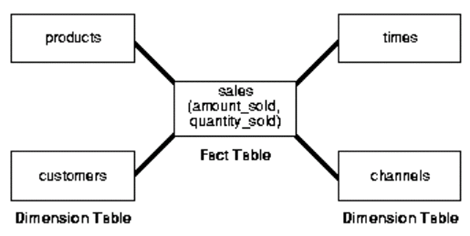
* 참조(Oracle 9i 매뉴얼)
Star Schema 데이터 모델은 항상 [그림 1]과 같이 중앙에 '분석 대상'인 매출액, 매출수량 등의 정량적인 Measure 혹은 Fact를 담고 있는 Fact 테이블을 놓고, 그 주변으로 매출 상품 구분, 매출 고객 구분, 매출 일자, 매출 귀속 영업부서 등 분석 대상의 '속성'에 해당하는 Dimension 테이블을 배치 시킨다.
Star Schema의 단점은 매우 비정규화되어 데이터 중복성을 가지고 이로 인해 쿼리 성능이 좋지 못하다는 점이다. 한편, Star Schema는 Data Marts와 거의 동일시될 만큼 Data Marts의 보편적 데이터 모델인데, 상세 데이터를 담고 있는 Detail Data Marts와 다양한 수준으로 요약된 형태인 Summary Data Marts 모두에서 사용될 수 있으며, Fact 테이블 혹은 Dimension 테이블의 비정규화 정도에 따라 Snowflake Schema와 같은 '변형된' Star Schema도 자주 사용된다.
Star Query는 Star Schema의 구성요소인 Fact 테이블과 Dimension 테이블을 조인하여 액세스 하는 것을 의미한다. Star Query의 장점은 쿼리 대상이 정규화 된 테이블이었다면 매우 복잡했을 쿼리문을, 상대적으로 단순하고 정형화된 쿼리문으로 대신할 수 있다는 점인데, 실제 구축상의 큰 단점은 앞서 언급한 쿼리 수행력의 저하이다. 아무리 Star Schema가 분석에 용이한 데이터 모델링을 가지고 있더라도 분석가 및 사용자가 수용하기 힘들 정도로 많은 시스템 자원이 소모되고 긴 쿼리 수행 시간이 소요된다면, 필연적으로 Star Schema 사용을 주저할 수 밖에 없을 것이다.
초기 오라클 DBMS의 경우 Rule-based Optimizer로 수행되는 Star Query는 크기가 큰 Fact 테이블을 먼저 읽고, 크기가 작은 Dimension 테이블들을 Nested Loop Join 방식으로 하나 씩 읽어 최종 결과 로우를 추출함으로써 매우 불리한 실행계획으로 수행 될 수밖에 없었다. 후에 이를 보완하고자 Star Join(버전 7 부터)과 Star Transformation(버전 8.0 부터)이라는 옵티마이징 기술을 차례대로 선 보였다. 그런데, Star Join 기술은 여러 작은 Dimension 테이블들을 카테시안 곱을 통해 중간 집합을 만든 후 Fact 테이블을 엑세스 하는 방식으로서, 이것이 수행 가능하기 위해서는 많은 제약 조건이 있고, 조인되는 Dimension 테이블 개수에 비례해 중간 집합의 크기가 기하급수로 증가하여 매우 불리한 수행이 이루어질 가능성이 많아 실무에서는 특히 유의해 사용해야 한다. Star Join에 대해서는 더 이상 언급하지 않겠다.
오라클 서버 8.0에서 소개된 Star Transformation은 Bitmap Indexing 기술과 Query Rewriting 혹은 Query Transformation 기술 등을 응용한 보다 향상된 Star Query 옵티마이징 방법인데, 아직 널리 사용되고 있진 않지만, 향후 이 기술의 진가를 맛볼 수 있으리라 기대한다.
Episode III: Execution Plans for Star Transformation
오라클 Star Transformation이 내부적으로 어떻게 옵티마이징을 수행하는지는 실행계획을 통해 해석 가능하다. 그러한 실행 계획을 살펴 보기 전에 우선 오라클 Star Transformation이 수행되기 위한 주된 기본 요구 조건을 열거하면 다음과 같다.
a) Cost-based Optimizer 모드
b) Initial Parameter인 STAR_TRANSFORMATION_ENABLED가 'TRUE'로 설정되어야 함.
c) Fact 테이블에 최소 2개의 단일 컬럼 Bitmap Index가 생성되어 있어야 함.
d) Bitmap Index 사용을 막는 hint(예를 들어 FULL hint)가 사용되지 않아야 함.
e) 조건절에 Bind variables가 사용되지 않아야 함.
실행계획이 어떻게 나타나는 지를 확인 하기 위한 과정은 다음과 같다.
우선, 오라클 DBMS에서 Sample 목적으로 제공하는 SALES 테이블을 SALES_T2란 이름으로 복사해 두었다. 다음으로, [그림 2]와 같이 Initial Parameter 설정, Bitmap Index 생성, 통계정보 생성 작업을 수행하고, 마지막으로 [그림 3]과 같은 SQL문을 수행하면, [그림 4]와 같은 실행 계획이 나타난다.
[그림 2]
[그림 3]
[그림 4]
Star Transformation 기술은 몇 가지 독특한 특징을 가지고 있는데, 사용자로부터 넘겨 받은 원래의 SQL문은 Cost-based Optimizer에 의해 아래의 [그림 5]와 같은 형태로 재작성(Query Rewriting or Transformation)된다. [그림 4]에서 1)~11)은 전체 실행 계획의 순서를 표시한 것이며, 2-1)~2-14)는 [그림 5]의 추가된 조건문에 의한 추가된 실행 계획을 보여 준다. 후자의 역할은 Dimension 및 Fact 테이블의 컬럼 조건을 이용해 Fact 테이블의 결과 집합을 결정하는 것이고(단, 조건문에 의해 Fact 테이블의 일부 만이 추출될 것으로 CBO가 예측한 경우에 Star Transformation 수행), 전자의 경우는 앞 단계의 결과 집합으로 select-list(예에서는 조인된 테이블 모두의 컬럼) 추출을 위해 또 다시 Dimension 테이블을 조인하는 것이다. 본 실행 계획에서는 후자의 실행 계획이 Hash Join으로 나타났지만, Cost-based Optimizer의 판단에 따라 다른 조인 방법 및 조인 순서도 가능하다.
[그림 5]
여기서 좀 더 살펴 볼 것은 전체 조인 순서가 Dimension->Fact->Dimension 이고, 첫번째 조인에서 Star Transformation만의 독특한 조인 방식을 볼 수 있다는 점인데, 그러한 조인은 반드시 Bitmap Index를 통해 이루어 진다. 참고로, 단일 컬럼의 B-tree Index도 Star Transformation에 참여할 수 있다는 점인데, 예를 들어, SALES_T2_CUST_BIX 대신 SALES_T2_CUST_IX라는 B-tree가 있었다면, 실행 계획상에 BITMAP CONVERSION(from ROWID)이라는 오퍼레이션이 추가됨으로써 해당 인덱스가 BITMAP AND 조인에 참여하고, Star Transformation도 가능해 진다.
사실, Fact 테이블에 대한 Bitmap Indexing 전략은 Star Transformation을 가능하게 할 뿐만 아니라, 상대적으로 작은 크기의 Bitmap Index들로써 보다 유연한 쿼리가 가능하다는 점에서도 충분히 가치가 있다. 컬럼의 순서까지도 결정해야 하는 B-tree 복합키 인덱스 생성 전략과 비교해 보면 그 가치를 보다 잘 이해할 수 있을 것이다.
Episode IV: Tests for Star Transformation
본 테스트의 주된 목적은 오라클 Star Transformation이 실제로 오라클 RDBMS 환경에서 실무적으로 유용한 기술인지를 확인하는 것이다. 본 테스트는 실제 운용 중인 시스템에서 적용해 본 '현장' 테스트가 아닌, PC 서버 상에서 이루어진 '실험실' 테스트이며, 여러 번의 실행 결과 분석으로써 일관성을 확인 한 내용을 공개하였다. 오라클 서버는 Enterprise Edition 8.1.6을 사용하였다.
Star Transformation의 비교 대상은 Nested Loop Join을 통한 단계적인 조인 방식인데, 예를 들어, Fact테이블로는 F, Dimension 테이블로 D1, D2, D3, D4가 있다고 할 때, F->D1->D2->D3->D4 순으로 조인이 이루어 진 경우이다. 단, 여기서 전제로 할 것은 추출 대상이 크지 않아 적어도 Merge Join 혹은 Hash Join 보다는 Star Transformation이나 Nest Loop Join이 더 유리하다는 점이다.
[그림 6]
[그림 7]
[그림 6]과 [그림 7]은 Dimension 수가 각각 5개, 10개, 15개, 20개, 24개 인 5종의 SQL문을 3번 씩 수행하고, 이를 오라클 SQL Trace 기능을 이용해 실행 소요 시간 및 읽은 메모리 블록 수를 추출하고 그 값을 평균한 후 도식화 한 것이다.
[그림 6]을 보면, 조인하는 Dimension의 수가 증가하더라도 일관되게 Star Transformation이 Nested Loop Join 방식 보다 소요 시간 측면에서는 2배 이상 유리함을 확인 할 수 있다.
맺는말
기업의 정보 인프라로서의 Data Warehouse(DW)는 CRM, Data Mining, 레포팅 시스템 등 여타 정보계 시스템의 통합된 데이터 Source 역할이 주된 목적이었다. 비록 OLAP 툴을 통해 Data Warehouse에 사용자가 직접 접근 할 수는 있겠지만, 대개 그 접근 영역은 특정 사용자를 위해 마련된 요약된 데이터로 제한 되어 있다. 하지만, '정보 제공'이라는 DW 본연의 임무를 충실히 이행하기 위해서는 몇몇 Dimension으로 요약된 데이터는 충분치 못하고, 가능한 많은 사람에게 가장 낮은 수준의 데이터까지도 SQL 혹은 ROLAP 툴을 통해 온라인으로 엑세스 할 수 있도록 해야 할 것이다. 그런데, 시스템 자원 한계를 이유로 일부 담당자 만이 DW 전체에 접근할 수 있는 것이 엄연한 현실이다.
Star Transformation은 지금까지 DW에서 가장 흔한 사용 행태인, 전체 Fact 테이블을 읽는 배치 작업인 경우 전혀 필요치 않는 기술이다. 하지만, 쿼리문이 다양한 Dimension 테이블을 참조해 소량의 Fact 테이블 로우를 추출하는 - 매우 자유스럽고 ad-hoc한 - 경우라면 성능면에서 매우 우수한 기술이라 할 수 있다. 좀 비약이긴 하지만, 영화 'Star Wars'를 통해 미래 생활상을 상상할 수 있듯이, Star Transformation 기술을 통해 미래에 보다 보편화될 DW 환경도 예견할 수도 있지 않을까?
|
