|
관계형 데이터베이스에서 효율적인 데이터 연결 - 조인편
원본출처 : http://korea.internet.com/channel/content.asp?cid=436&nid=21952
아래에 빠져 있는 image 는 첨부파일에 4개의 파일이 압축되어 있습니다. 참조 바랍니다.
이번 연재에는 관계형 데이터 베이스에서 데이터 연결 방법 중 Join의 종류, 조인의 수행원리, 각 조인의 특징, 그리고 조인별 선택기준에 대해서 소개하고자 한다.
조인은 두 집합간의 곱으로 데이터를 연결하는 가장 대표적인 데이터 연결 방법이다. 종류에는 Nested Loop Join, Sort Merge Join 그리고 Hash Join이 있다.
1 * M = M 과 M * 1 = M 의 결과집합이 동일한 것처럼 Optimizer가 3가지의 조인 중 어떤 것을 선택할지라도 결과집합은 동일하다. 하지만 수행속도 측면에서 본다면 조인하고자 하는 두 집합의 데이터 상황에 따라 어떤 조인을 선택하느냐, 어떤 집합을 먼저 선행하느냐 에 따라 수행속도에 미치는 영향은 크다.
100쌍의 남녀가 사랑의 짝짓기 하는 것에 비추어 3가지 조인방식이 수행되는 원리를 설명해 보자. 남녀 모두는 자기 원하는 상대방의 번호표 하나씩 가지고 있고, 한 사람은 여러 사람으로부터 선택 받을 수 있다.
첫번째 방식, 첫번째 여자는 자기가 선택한 번호표를 가지고 처음부터 차례로 남자의 번호를 확인하고, 해당 번호의 남자가 자기를 선택했는지 확인한다. 그리고 두 번째, 세 번째,..,백 번째 여자까지 같은 작업을 반복 수행하게 된다. 이처럼 선행 집합의 선두부터 차례로 후행집합과 조건을 비교 하면서 선행집합의 처리범위가 끝날 때 까지 같은 작업을 반복하는 것이 Nested Loop Join이다. 선행집합의 처리 범위가 결정지면 후행집합의 일량이 정해지는 종속적 방식이다.
두번째 방식, 남녀는 각각 자기가 선택한 상대방의 번호표(Join Key) 순으로 각각 줄(Sort)을 선다. 그러면 중간의 아나운서가 차례로 양쪽의 번호표가 일치하는지를 확인하면서 번호표가 맞다면 짝을 지어줄 것이다. 이처럼 각각의 집합은 자기에게 주어진 조건으로 처리범위를 결정하고, 조인 컬럼으로 각각 Sort 한 후 조인하는 방식이 Sort Merge Join이다. 처리범위를 결정하는데 독립적이다.
세번째 방식, 1번부터 100번(Hash Table)의 푯말이 있다. 여자측은 자기가 가지고 있는 상대방의 번호표 숫자푯말 앞에 서는 것이다(Hash Function). 물론 각 푯말에는 여러 명의 여자가 서 있을 수도, 한명도 없을 수도 있다. 다음으로 남자는 자기 번호푯말 앞으로 가서 남자가 가지고 있는 번호와 상대 여성의 번호와 맞는지를 비교하면 된다. 이처럼 선행 집합은 Hash Function을 이용하여 Hash Table을 구성하고, 후행집합은 차례로 Hash Function을 이용하여 Hash Table을 탐침하는게 Hash Join 수행 원리이다. Hash Join역시 처리범위를 결정하는데 독립적이다.
Nest Loop Join의 특징 및 사용기준
온라인 어플리케이션에서 주를 이루는 Nested Loop Join은 부분범위 처리나 사용자가 데이터를 요구 했을 때 짧은 시간에 결과를 볼 수 있는 적은 데이터를 액세스 할 때 쓰인다. 다음과 같은 SQL을 예로 들어 보자.
SQL >SELECT a.FLD1, ..., b.FLD1,...
FROM TAB2 b, TAB1 a
WHERE a.KEY1 = b.KEY2
AND b.FLD2 like \'A%\'
AND a.FLD1 = \'10\'
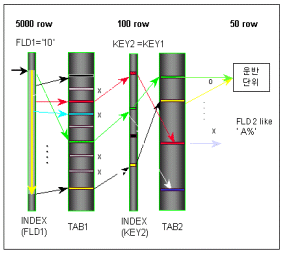
조인 컬럼인 a.KEY1 = b.KEY2에 양쪽 테이블 모두 인덱스가 존재하고, 선행 테이블을 TAB1으로 했을 때와 TAB2로 했을 때의 수행횟수를 비교하여 보자.
 1
1
[img2]
TAB1이 선행테이블 일때
1. a.FLD1 인덱스 5000건 Range Scan.
2. Rowid로 TAB1에 5000회 랜덤액세스
3. 성공/실패에 상관없이 b.KEY2 인덱스에 5000회 랜덤액세스 및 조인시도
4. 조인에 성공한 Rowid로 TAB2에 100회 랜덤액세스
5. b.FLD2 like \'A%\' 체크 후 성공한 50건 운반단위 이동
TAB2가 선행테이블 일때
1. b.FLD2 인덱스 100건 Range Scan.
2. TAB2의 100회 랜덤액세스
3. 성공/실패에 상관없이 a.KEY1 인덱스에 100회 랜덤액세스 및 조인시도
4. 조인에 성공한 Rowid로 TAB1에 70회 랜덤액세스
5. a.FLD1 = \'10\' 체크 후 성공한 50건 운반단위 이동
결과건수는 두 가지 수행방식 동일하게 50건이지만, 수행횟수 측면에서 본다면 TAB1을 선행테이블 했을 때는 5000회의 조인시도가 발생하였고, TAB2를 선행테이블로 했을 때는 100회의 조인시도가 발생하였다. 이처럼 조인 순서 및 선행 테이블의 처리범위에 따라서 수행횟수는 크게 달라질 수 있다. Nested Loop Join의 특징 및 사용기준은 다음과 같다.
특징
1. 선행 테이블의 처리범위가 일량을 결정한다.(방향성)
2. 선행 테이블의 값을 받아서 후행 테이블의 처리범위가 결정된다.(종속적)
3. 주로 랜덤 액세스 방식으로 처리된다.(랜덤액세스)
4. 후행 테이블의 조인컬럼의 인덱스의 유무 및 조건의 인덱스 참여의 정도에 따라 수행속도가 많이 차이 난다.(연결고리 상태)
사용기준
1. 부분범위처리를 하는 경우에 유리하다.
2. 처리량이 적은 경우에 유리하다.- 랜덤액세스가 많을 경우 수행속도를 보장할 수 없으므로 Sort Merge Join이나 Hash Join으로 유도
3. 선행 테이블의 결과를 받아야만 후행 테이블의 처리범위를 줄일 수 있는 경우에 유리하다. - 연결고리에 Index가 반드시 존재하여야 함
4. 선행 테이블의 처리범위가 수행속도에 절대적 영향을 미치므로 최적의 조인 순서가 될 수 있도록 유도해야 한다.
Sort Merge Join의 특징 및 사용기준
다량의 데이터를 스캔방식으로 처리하는 Sort Merge Join은 양쪽테이블을 각자 액세스하여 처리 범위를 줄이고, 조인컬럼 순으로 데이터를 Sort 후에 조인하는 방식이다.
[img3]
수행 과정을 살펴보자
1. a.FLD1 인덱스 Range Scan.
2. Rowid로 TAB1에 랜덤액세스
3. 조인컬럼인 a.KEY1로 SORT
4. b.FLD2 인덱스 Range Scan.
5. Rowid로 TAB2에 랜덤액세스
6. 조인컬럼인 b.KEY2로 SORT 한다.
7. 양쪽 집합을 Scan하면서 a.KEY1 = b.KEY2 조인 시도
8. 성공한 Row 운반단위 이동
수행과정에서 나타나듯이 Nested Loop Join과 달리 상대 테이블의 결과에 의해 처리범위가 결정되는게 아니라 스스로에게 주어진 조건 만으로 처리범위를 줄인 후 Sort하게 되므로, 조인 컬럼으로 이루어진 인데스는 사용하지 않게 된다. Sort Merge Join의 특징 및 사용기준은 다음과 같다.
특징
1. 상대 테이블로부터 결과 값을 제공받지 않고, 자신에게 주어진 조건으로만 처리범위를 결정한다.(독립적).
2. 각자 SORT후에 조인을 하게 되므로 부분범위 처리가 아닌 전체범위 처리를 하게 된다.(전체범위 처리)
3. 조인의 순서에는 상관없다.(무방향성)
4. 인덱스가 아닌 컬럼도 Merge할 작업 대상을 줄이므로 중요한 의미를 가진다.
사용기준
1. 처리량이 많거나 전체범위 처리 시에 유리하다. 랜덤액세스가 많은 Nested Loop Join은 불리
2. 스스로 자신의 처리범위를 많이 줄일 수 있을 때 유리하다.
3. 연결고리 이상 상태에 영향을 받지 않으므로 연결고리 컬럼을 위한 인덱스를 생성하지 않고도 유용하게 사용할 수 있다.
4. 처리할 데이터량이 적은 온라인 어플리케이션에서는 Nested Loop Join이 유리한 경우가 많으므로 Sort Merge Join은 주의하여 사용한다.
Hash Join의 특징 및 사용기준
대량의 데이터를 액세스하는 작업에서는 시스템 리소스를 많이 사용하는 대신 짧은 시간에 보장할 수 있어야 한다. 다음은 수행방법을 살펴보자
[img4]
1. 두 테이블 중 적은 테이블을 선행 테이블로 결정한다.
2. 선행 테이블을 Hash Function을 이용하여 Hash Area에 Hash Table을 구성한다.(Build Input)
3. 만약 Hash Area만으로 생성 가능하다면 후행테이블은 크기에 상관없이 차례로 Hash Function을 이용하여 Hash Table과 조인(Probe Input)하면서 성공한 결과값을 운반단위로 이동한다.
4. 만약 Hash Area만으로 Hash Table 생성이 불충분 하다면 Hash Table Overflow가 발생하여 데이터를 나눠서 저장 할 Partition 수를 결정한다.(Fan -out)
5. 선행 테이블의 조인 컬럼과 Select List 컬럼을 메모리로 읽어 들여 첫번째 해쉬 함수를 이용하여 Partition을 Mapping하고, 두번째 해쉬 함수를 이용하여 해쉬 테이블 생성시 사용 할 해쉬 값을 생성한다.
6. 선행 테이블의 조인 컬럼의 유일 값만으로 Bit-Vector을 생성한다. -추후 Bit-Vector filtering에 사용하기 위함.
7. Partition에 데이터를 MOVE하고 채워진 Partition은 디스크로 내려간다.
8. 선행 테이블이 모두 읽혀지면 Partition 테이블을 완성하고, Partition 크기순으로 정렬한 후 작은 Partition N개를 메모리에 로드한다.
9. 후행 테이블을 읽으면서 조인컬럼으로 Bit-Vector와 Filtering에 성공하였다면, 첫번째 해쉬함수로 Partition을 결정하고, 두번째 해쉬 함수를 이용하여 메모리 상에 있는 선행테이블과 조인하고 성공하면 운반단위로 이동하고, 해당 Partition이 메모리에 존재하지 않는다면 해쉬 키값,조인컬럼, Select List를 디스크에 쓴다.
10. 후행 테이블이 모두 읽혀지면, Bit-Vector Filtering에 성공했지만, 조인에 성공하지 못해 미 처리된 선행 파티션과 후행 파티션을 메모리에 올려 차례로 반복수행 한다.
액세스해야 할 데이터가 많을 경우 Sort Merge Join은 Merge 단계에 들어 가기 위해 양쪽 테이블의 처리 범위가 SORT 되어야 하므로 SORT에 대한 부담이 크고, Nested Loop Join은 선행 테이블의 처리 범위가 넓을 경우 그 만큼 랜덤 액세스의 발생으로 수행속도를 보장할 수 없다.이해 반해 Hash Join은 다른 조인에 시스템 리소스를 가장 많이 사용하지만 Hash Function을 이용함으로써 Sort를 하지 않고, 각 테이블에 한번만 액세스하여 조인이 이루어 지므로 큰 테이블간이나, 큰 테이블과 적은 테이블의 조인에 효율적인 조인 방법이다. Hash Join의 특징 및 사용기준은 다음과 같다.
특징
1. 다른 테이블의 결과 값을 제공받지 않고, 자신에게 주어진 조건으로만 처리범위를 결정한다.(독립적).
2. 해쉬 함수를 이용 하게 되므로 부분범위 처리를 할 수 없으며 전체범위 처리를 하게 된다.(전체범위 처리)
3. 메모리 영역만으로 해쉬 테이블을 생성시 최적의 효과를 낼 수 있으므로 적은 테이블이 선행으로 온다.
4. 해쉬 함수를 이용하므로 결과값의 정렬을 보장 받을 수 없다.
사용기준
1. 대량의 데이터 액세스 시, 배치 처리, Full Table Scan 하면서 조인 해야 할 때 유리하다.
2. 비용은 많이 들지만 수행속도를 보장해야 하는 작업에 유용하다.(Parallel Query 사용)
3. 가능한 메모리 내에서 작업 가능하도록 init Parameter나 Session 정보를 변경하여 사용한다. (Hash_area_size, Hash_multiblock_io_count 등..)
수행속도는 시스템 리소스와 즉결된다. 사용자는 작업의 성격을 분명히 하고, 작업에 적합한 조인을 선택해야만 수행 속도를 보장할 수 있다. SQL작성 후 반드시 실행계획를 확인 하여 사용자가 원하는 액세스로 수행되는지를 확인하는 습관을 들어야 한다.
|
