|
2부 데이터웨어하우징 솔루션
■ 데이터웨어 하우징의 정의
"데이타 웨어하우징의 궁극적인 목적은 물리적으로 여러 곳에 분산되어 있는 데이타베이스내에 존재하는 데이타들에 대하여 하나의 논리적인 뷰(view)를 창출하는 것이다."
- 버틀러 그룹(Butler Group)
위의 문장은 데이타 웨어하우스의 목적을 표현한 것이지 데이타 웨어하우스가 무엇인가를 설명한 것은 아니다. 데이타 웨어하 우스는 사실 여러가지 의미로 받아들여지고 있으며, 따라서 한마디로 정의하기는 결코 쉬운 일이 아니다.
가장 일반적으로 받아들여지고 있는 데이타 웨어하우스의 정의는 "데이타 웨어하우스의 아버지" 라고 불리우는 Bill Inmon이 그의 저서에서 기술한 것으로서 다음의 성격을 지닌 데이타의 집합체를 의미한다:
▶ 주제지향성 (Subject Oriented)
데이타 웨어하우스내의 데이타는 일상적인 트랜잭션을 처리하는 프로세스 중심 시스템의 데이타와 달리 일정한 주제별 구성을 필요로 한다. 예를들어 보험회사의 경우 프로세스 중심의 시스템으로는 '자동차 보험', '생명보험', '개인연금보험' 등이 해당 되지만, 이들의 주제영역을 보면 '고객', '약관', '청구' 등이 될 수 있다.
▶ 통합성 (Integrated)
데이타 웨어하우스내의 데이타는 고도로 통합되어야만 한다. 예를들어, 기존의 애플리케이션 중심의 환경에서는 남자와 여자 를 남/여, Male/Female, 1/0 등으로 다양하게 적용할 수 있으나 데이타 웨어하우스에서는 이들을 통합할 필요가 있다 (예, 남자 와 여자는 '남'과 '여'로 통합).
▶ 비휘발성 (Non-volatile)
데이타 웨어하우스는 오직 두가지 오퍼레이션(operation)을 갖게 되는데, 하나는 데이타를 로딩(loading)하는 것이고, 다른 하나는 데이타를 읽는 것, 즉 액세스 하는 것이다. 이를 달리 표현하면 데이타 웨어하우스에 일단 데이타가 로딩되면 읽기전용으 로 존재한다는 것이다. 따라서, 데이타 웨어하우스의 데이타는 오퍼레이셔널 시스템(Operational System)에서 수시 발생되는 갱 신이나 삭제 등이 적용되지 않으므로 수시로 변한다는 의미의 "휘발성"을 갖지 않게 된다.
▶ 시계열성 (Time Variant)
오퍼레이셔널 시스템의 데이타는 액세스(access)하는 순간에 정확해야만 의미가 있게 된다. 그러나, 데이타 웨어하우스의 데 이타는 일정한 시간 동안의 데이타를 대변하는 것으로 "스냅 샷 (Snap Shot)"과 같다고 할 수 있다. 따라서 데이타 구 조상에 '시간'이 아주 중요한 요소로서 작용한다. 이와 같은 이유에서라도 데이타 웨어하우스의 데이타에는 수시적인 갱신이나 변경이 발생할 수 없다.
■ 데이터웨어 하우징(Housing)의 구조
데이터웨어하우징 환경에서 정보는 제조 업자에서와 같은 상품으로 생각할수 있으며, 정보의 흐름은 상품이 제조되어 고객에 게 이용되기 까지 과정과 유사한 일련의 흐름을 거치게된다.
생산(OLTP시스템)->저장및분배(데이터웨어하우스)->소매(어플리케이션)
정보시스템에서 정보라는 상품이 그 고객(사용자)에게 이용 가능하기 위해 다양한 요소기술과 툴이 공급되어 각 사의 데이터웨 어하우스 구축을 지원하고 있는데, 기술적인 부분을 배제시키고 사용자 관점에서 정리하면 4개의 층, 즉 소스테이터, 데이터웨어 하우스, 데이터마트, 클라이언트 시스템으로 나눌수 있다.
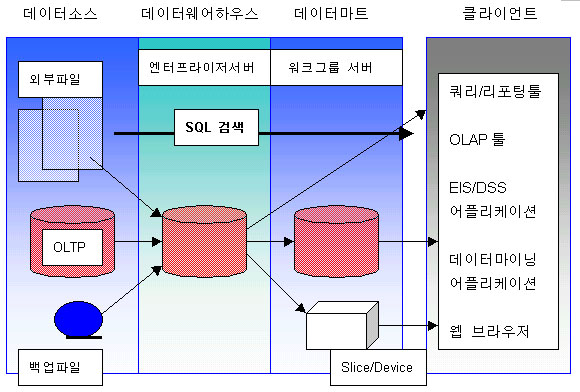 2
2
소스테이터층은 운영데이터와 백업용 파일등으로 구성되는 4개층중에서 가장 원시적인 정보의 집합장소를 말한다.
데이터웨어하우스는 사용자에 의해 직접 사용되기도하고 데이터마트를 구성하는 데이터를 제공하는 역할도 한다.
데이터마트층은 작업그룹(Workgroup)서버로 설명될수 있는데, 관계형 데이터베이스나 다차원데이터베이스를 이용하여 구축된다. 다차원데이터베이스로 구축된 데이터 마트는 마우스로 시스템을 조작하는 방식이어서 사용자 인터패이스가 우수하고, 사용자의 업무 구조를 유사하게 반영하고 있어서 개념적으로 이해하기 쉽고, 시스템의 반응속도가 빠른 장점이 있다.
클라이언트 시스템층에서 사용자는 퀴리 및 리포팅툴, OLAP툴, EIS/DSS어플리케이션, 데이터 마이닝 어플리케이션, 그리고 웹브 라우저를 이용하여 데이터 웨어하우스나 데이터 마트를 이용하게된다. 특히 웹브라우저는 인터넷의 저렴하고 광범위한 테이터 통 신이 가능하기 때문에 관심의 대상이 되고 있는데 데이터 웨어하우스에 저장되어 있는 전사 혹은 부문 데이터를 전세계 지사에서 공유할수 있다는 장점 때문에 잠재시장이 커가고 있다.
여기에서 데이터웨어 하우징에서의 중요성을 크게 차지하는 데이터웨어하우스의 구조와 마트에대해 다음절에서 자세히 살펴보도 록한다.
■ 데이터웨어 하우스(House)의 구조
일반적으로 데이타 웨어하우스는 5가지의 데이타 형태로 이루어진다. (그림 참조)
[img3]
▶ 메타 데이타 (Meta Data)
-데이타를 데이타 웨어하우스에 어떤 데이타를 어떻게 저장할 것인지를
세부적으로 기술하는 '설명자'의 역할
-오퍼레이셔널 시스템의 데이타 구조를 데이타 웨어하우스로 매핑(mapping)하는데 필요한 즉, 데이타를 요약주)하는데 사용되는 알고리즘을 포함
▶ 현재의 상세 데이타 (Current Detail Data)
-대개 디스크에 저장
-가장 최근의 변경사항을 반영
-가장 하위 레벨에 위치하므로 대부분 양이 많음
▶ 과거의 상세 데이터(Older Detail Data)
-가끔씩 필요에 의해 액세스되는 데이타로서 테이프와 같은 저장장치에 수록
-현재의 상세 데이타도 정의되는 시간 개념에 따라 과거의 상세 데이타로 바뀌게 됨
▶ 약간 요약된 데이터(Lightly Summarized Data)
-주로 디스크에 저장
-현재의 상세 데이타를 약간 요약한 것
▶ 고도로 요약된 데이터(Hightlt Summarized Data)
-주로 디스크에 저장
-간결하게 요약되어 쉽게 액세스가 가능함
-4로 부터 재차 요약된 데이타
주) 데이타 웨어하우스란 비지니스 트랜잭션을 처리하기 위한 오퍼레이셔널 시스템으로 부터 선별되어 가공된 데이타들로 이루어진 데이타베이스이다. 데이타 웨어하우스는 읽기전용의 데이타들로 이루어져 의사결정에 도움 을 주기 위한 조회만이 가능하고 갱신이나 삭제가 일어나지 않는다는 것을 기본 전제로 한다.
■ 요 약(Aggregation)
요약(aggregation)은 하위 레벨 데이터를 미리 요약(summarize)하고, 요약(summarize)되거나 "수집(aggregated)"된 정보를 저장할 중간 테이블에 넣는 과정이다. 이 요약 테이블들에서 애플리케이션이 사용자 query를 수행하고, 요약 정보가 필요 할 때마다 다른 방법으로 수행되는 자원 집약적 계산을 반복할 필요가 없다.
다차원 데이터 웨어하우스 요약(Aggregation)
전형적 데이터 웨어하우스 구조는 가장 하위의 또는 "원자(atomic)" 레벨에서의 거대한 트랜잭션 저장소로 시작한다. 측정(measure)은 후에 데이터 분석과 리포트의 단계에 사용될 수 있도록 가장 자세한 형태로 주요한 실제(fact) 테이블에 저장 된다.
그러나 원자 레벨에서 데이터를 뽑아내는 것은 아무리 선도적 소프트웨어와 하드웨어라 할지라도 최적의 성능을 갖지는 못한다. 실제(fact) 테이블은 심각한 성능 문제를 야기하는, 매우 큰 경향이 있다. 열(rows)의 무수한 합계는 어떤 소프트웨어 또는 하 드웨어가 사용되고, 데이터 웨어하우스가 잘 조정되어 있다 하더라도 오랜 시간이 걸릴 것이다.
데이터 요소의 summarization 또는 aggregation이 데이터 웨어하우스에 대한 주요 query 백분율을 차지한다. 보통 사용자는 "이 달의 총 세일즈를 보여주십시오."라고 요청할지도 모른다. 이것은 "이 달에 포함된 각 날들의 모든 세일즈를 더하십시오."로 데이터베이스가 해석할 것이다. 만일 1,000개의 상점에서 하루에 평균 1,000건의 세일즈가 이루어지고, 데 이터가 트랜잭션 레벨에 저장된다면, 이 query는 답을 주기 위해서 30,000,000 열(rows)을 처리해야 한다. 이 같은 Summary-Inte nsive Query는 중요한 자원을 소비할 수 있다.
일반적으로 액세스된 데이터 경우, 사전 요약이 종종 유용하다. 이것은 최종 query 결과를 보여주는 데 필요한 자원을 감소시키 면서, 중간 결과나 "요약 table"이 사용된다는 것이다. 요약 table의 값을 구하기 위해서, 8월 세일즈의 요청을 고려 하시오. 만일 상점별 월 세일즈를 조사하기 위해서 이미 만들어진 요약 table이 있다면, query는 오직 1,000열(각 상점당 8월 총 계)을 처리해야 합니다. 30,000,000열과 비교할 때, 같은 query는 트랜잭션 레벨에 저장된 데이터를 처리해야만 할 것입니다. 몇 몇 순서에서 자원 절약이 이루어진다. 사실, 잘 조정된 데이터 웨어하우스에서 query response time은 query가 처리해야 하는 많 은 열에 대해 대략 균형이 잡혀 있기 때문에, 위의 요약과 관련된 성능 향상은 약 30,000개의 요인(factor)이 될 수 있다.
얼마나 요약(Aggregation)할 수 있는가?
대부분의 현재 기술들은 데이터베이스 사용자들에게 철저한 선택을 제공합니다(사용자가 원하는 가능한 query 조합을 위해 어떠 한 요약도 없는 또는 완전한 요약을 제공).
아무 요약도 수행하지 않는 것은 실재 데이터 웨어하우스를 위한 질문을 벗어난 것이다. 모든 가능한 조합의 요약은 엄청나게 큰 저장소, 관리, 그리고 소요되는 시간 비용으로 가장 좋은 query 성능을 수행한다. 첫번째로, 모든 가능한 레벨에서 요약 정보 를 저장한다는 것은 5개 이상의 요인에 의해 저장소 요구를 증가시키면서, 엄청난 디스크를 소모할 것이다.
두 번째로, 전형적인 데이터 웨어하우스는 차원 요소의 무수한 조합을 가진다. 마지막으로, 새로운 정보가 실제 테이블에 추가 될 때마다 요약 table이 만들어지는 것은 많은 시간이 소요되고 자원 집약적이기 때문에, 웨어하우스를 조정하기 위해서 필요한 로드 윈도우(load window)는 용납하지 못할 정도로 오래 걸릴 것이다.
필요한 것은 지능적으로 요약 table을 사용하는 query 엔진이다. 예를 들면, 년별로 요약된 세일즈를 요청하는 query를 고려해 보리. 또한, 세일즈가 실제 테이블에서 트랜잭션에 의해 그리고 요약 table에서 월별에 의해 저장되는 것도 고려하라. query는 월별 요약에 대해 수행되어야 하고, 실제(fact) 테이블로부터 많은 레코드를 추가하는 대신에 요약 table 속에 저장된 12달을 위 한 12개의 레코드가 추가되어야 한다. 다음그림에서 만약 엔진이 그와 같은 결정을 할 수 있다면, 12개의 열을 요약하는 것이 간 단하기 때문에 "년별 세일즈" 요약 table을 만드는 것은 불필요한 것이다. 이 같은 지능적 query 최적화는 Stanford T echnology Group, Inc.의 의사결정 지원 소프트웨어의 제품군으로부터 나온 MetaCube 엔진에 의해 수행된다.
데이터 웨어하우스 설계자는 MetaCube의 Query optimizer로 어떤 요약 table을 만들 것인지를 선택한다. 왜냐하면, optimizer가 가장 가능성 있는 루트를 통해서 자동적으로 정보를 가지고 올 것이기 때문이다. 더욱이, 웨어하우스 설계자는 새로운 애플리케 이션의 추가, 사용 패턴 혹은 정보 요구의 변경에 따라, 데이터가 요약되는 방법을 변경할 수 있다. 그런데, 설계자는 MetaCube 엔진을 사용하는 front-ends에서 코드의 한 줄을 변경해야 할 필요 없이 요약 table을 추가하거나 삭제할 수 있다
그림:월별 제품 요약
(월별 제품요약 table을 작성함으로써, 지능적 데이터 웨어하우스 엔진은 고도로 요약된 모든 query의 성 능을 극적으로 향상시킨다.)
[img4]
■ 정확한 요약 Table의 선택
어떤 요약 table을 만들려고 결정할 때 고려해야 할 다음과 같은 중요한 두 가지가 있다.
데이터 밀도: 데이터가 어디에 집중되어 있고, 많은 열들이 어떤 차원 요소에서 증가하는가?
사용 방식: 현업 사용자에 의해서 가장 자주 수행되는 특정 query의 경우, 어떤 요약 table이 가장 좋은 성능 향상을 가져올까?
만일 주어진 차원 요소(dimension element)가 계층 내에 있는 다른 요소와 비교해서 많은 열들로 나타난다면, 그 차원 요소에 의한 요약 table의 생성이 상당한 성능 향상을 가져온다. 반대로, 차원 요소가 열을 거의 포함하지 않거나, 차원 요소를 대신하 는 것보다 많은 열을 어렵게 포함한다면, 그 차원 요소에 의해 요약 table을 만드는 것은 비효율적이 된다.
이 분석은 차원이 서로 결합하는 것처럼 좀더 의미 있고 복잡하게 된다. 다차원에 의해 데이터 요청을 정의하는 것은 검색되는 데이터의 범위(range)뿐 아니라 밀도(density)도 감소시킨다. 예를 들면, 모든 제품이 매일 모든 상점에서 팔리는 것은 매우 드 물다. 대부분의 제품의 경우, 주어진 날 동안 세일즈 레코드가 거의 없고, 일일 제품 세일즈 데이터는 이와 같이 드물다. 그러나 , 만약 모든 제품이 매일 모든 상점에서 팔린다면, 데이터가 상대적으로 밀도 있게 분류되는 것이다. 데이터 밀도는 query 엔진 이 얼마나 많은 레코드를 처리해야 하는가 하는 계산을 복잡하게 한다. 모든 가능한 레코드가 있고, 즉 데이터가 밀도 있다는 가 정에 근거한 사이징 시뮬레이션은 각 결합의 성능 분석을 빗나가게 한다.
예를 들면, 지역별 제품 라인 세일즈를 요약하는 요약 table을 집계할 것인지를 결정할 때, 실제로 그 지역 내의 각 상점에서 팔린 많은 다른 제품들이 중요하게 된다. 두 제품 라인(총 8개 제품)을 판매하면서, 두 지역(총 8개의 상점)에서 4개의 상점을 포함하는 단순한 데이터를 고려해 보라.
만일 하나의 제품 라인에 있는 하나의 제품만이 일일 기준(드문 데이터)으로 각 지역에서 판매된다면, 그 날을 위한 제품 라인 의 많은 제품들이 효율적으로 한 개로 줄어듭니다. query의 경우, "지역별 일일 제품 라인 세일즈"인 하나의 제품 열 은 총 4개의 열, 각 지역(2) 내의 각 제품 라인(2)을 위해서 검색될 것이다. 마찬가지로, 제품들이 제품 라인별 세일즈 요약 tab le에 요약되었고, 같은 query가 행해졌다면, 같은 열들(4 rows)이 처리되었을 것입니다. 이 경우, 요약 table은 어떠한 성능의 장점도 제공하지 않는다.
만약 모든 제품 라인에 있는 모든 제품이 매일 모든 상점에서 판매된다면, 이 query는 두 product line의 각각에 대한 4개의 상 품과 두 지역에 있는 4개의 상점 각각에 대한 총 64 레코드에 대해 처리해야 한다. 그러나, 지역별 제품 라인 세일즈를 요약하는 요약 table이 16배로 처리되어야 많은 레코드를 감소시키면서, 오직 4개의 레코드를 사용하여 query를 처리할 수 있을 것입니다 . 많은 상점들과 제품들을 나타내는 전형적인 데이터베이스에서 성능의 장점은 상당한 것입니다. 최적의 요약 table을 감지하는 분석은 이 경우에 제품 라인 요약 table에 유리하다.
STG는 이 분석을 수행하기 위한 소프트웨어를 개발했다. 분석적 과정이 복잡한 반면, 문제에 접근하기 위한 방법론 STG 사용은 정확하다. 각 단계에서의 질문은 "어떤 요약 table이 데이터 웨어하우스에 있는 query가 처리해야 하는 평균 열들을 감소시 킬 것인가?"이다. 알고리즘이 증거를 지원하면서 이 답을 산정하고, 데이터베이스에 저장한다.
두 번째 답은 사용자 모임으로부터 나오는 피드백에 달려 있다는 것이다. STG 툴은 어떤 데이터가 얼마나 자주 요청되고, 누가 요청하며, query가 처리되는 데 얼마나 많은 시간이 걸리는지, 얼마나 많은 열들이 검색되는지, 그리고 다른 기준들로 정보를 수 집하는 사용자 query를 감시한다. 이 정보는 데이터 웨어하우스를 조정하는 데 사용될 수 있다.
▶ 샘플 요약 사이징
주어진 데이터 웨어하우스에서 만들어진 최적의 요약 table의 수를 결정하기 위해서, 우리는 "사이징 시뮬레이션"을 수행할 수 있다. 고려해야 할 주 요인은 요약 table(디스크 비용)이 차지하는 총 공간과 요약 table(로드 윈도우와 관리 비용)의 총 수이다. 이 단락은 STG가 샘플 데이터 웨어하우스를 위해서 처리하는 실제 시뮬레이션을 나타낸다.
▶ 시뮬레이션 절차
사이징 시뮬레이션하는 동안 다음 단계를 수행한다.
데이터베이스가 대표적 샘플 데이터로 로드된다. 이 샘플 실제(fact) 테이블은 통계적으로 중요한 결과를 만들기에 충분한 하위 레벨 데이터를 포함한다.
차원 요소의 모든 가능한 조합을 query하는 일련의 SQL문이 만들어지고, 백그라운드 프로세스에 의한 수행을 위해 서버에 보관 된다.
SQL문이 수행되고, 수행하는 데 걸리는 시간뿐 아니라 전송되는 열들에 대한 정보가 데이터베이스에 기록된다.
"요약 비용 매트릭스" 결과는 데이터베이스로부터 나와서 STG 소프트웨어에 제공되고, STG 소프트웨어는 최적의 알고 리즘을 수행한다. 소프트웨어는 선두 100개의 요약 table을 리스트하고, 사이징과 성능 분석을 위해서 그것들을 사용한다.
그림:(요약 table 사이즈대 Query 성능)
[img5]
▶ 점증적 요약 대 전체 요약(Incremental & Full aggregation)
[img6]
이미 언급한 것처럼, 요약 프로세스의 약점은 요약 table을 만들기 위해서 필요 한 시간 윈도우이다. 거대한 데이터베이스와 중요한 요약 요구를 가진 현업 사용자는 필요한 모든 요약 table을 만들기 위해서, 컴퓨터 자원과 엄청난 시간이 요구된다. 매주마다 더 많은 정보가 데이터 웨어하우스에서 나오기 때문에, 요약 table은 뒤진 데 이터가 되기 때문에 다시 계산되어야 한다.
한 가지 선택은 기본 실제(fact) 테이블에서 요약 오퍼레이션을 수행함으로써 처음부터 다시 계산하는 것이다. 그러나, 요약 시 간이 심각한 문제인 상황에서는, 이것은 실행 가능한 솔루션이 되지 않는다.
이 문제를 설명하기 위해서, STG는 불필요한 자원 사용을 피하면서 들어온 원자 데이터에 근거해서 이미 존재하는 요약 table 을 갱신하는 프로그램인 MetaCube Aggregator를 개발했다. MetaCube Aggregator는 이미 존재하는 요약 table에 새로운 데이타를 추가할 수 있다. 데이타의 적은 수를처리함으로써, 점증적 요약은 재요약보다 몇 십배 빠르게 동작한다.
|
