|
■ Oracle Data Mart Suit
▶ 개 요
데이타 웨어하우징은 정보 기술의 발달과 함께 1990년대에 들어 그 개념이 새로이 발전 되면서 기업이나 조직의 더 나은 의사결 정을 위한 하나의 툴로서의 기대효과를 충족시키기 위한 수단이 되어가고 있다.
1996년 메타 그룹의 연구보고서에 의하면 기업의 전사적인 데이타 웨어하우스의 경우 평균 약 3백만달러 정도의 비용으로 몇 년 동안 계속되는 프로젝트의 경향을 보인다고 한다. 한편, 데이타 마트의 경우 데이타 웨어하우스의 축소판으로 평균 30만 달러 정도의 비용으로 3~6개월 정도의 구현 싸이클을 보인다고 한다. 이처럼 상대적으로 저렴한 비용과 투자분에 대한 조기 회수의 기 대감은 데이타 마트에의 관심을 한층 증대시키고 있다. 데이타 마트는 결국 급변하는 비즈니스 환경에 시기적절하게 대응하기 위 한 수단으로서 뿐만 아니라 기회의 예측과 이를 기반으로 현재의 투자분을 충분히 살릴 수 있을 것이라는 긍정적인 시각을 받고 있는 것이다.
이 글에서는 데이타 마트 솔루션인 Oracle Data Mart Suite가 이같은 데이타 마트의 요구 조건 (즉, 저렴한 비용, 신속한 구현, 강력한 기능 등) 을 얼마나 만족시킬 수 있는가에 관해 설명하고자 한다.
웨어하우스 프레임 웍의 핵심은 정형화된 관계형 데이타 뿐 아니라 텍스트, 공간, 멀티미디어 및 다차원 데이타 등 다양한 비정 형 데이타에 대한 처리까지도 지원하는 오락클 유니버설 서버이다. 또한 오라클은 간단한 질의 및 보고서 작성용 툴에서 부터 데 이타 웨어하우스에 필수적인 정교한 데이타 분석용 툴까지 공급하고 있다. 뿐만 아니라 오라클은 업계에서 가장 광범위한 파트너 쉽을 통해 데이타 웨어하우스의 디자인에서 부터 개발, 구현 및 관리에 이르는 전 과정을 자사 및 협력업체의 제품 라인업을 이 용하여 지원하고 있다. 오라클이 데이타 웨어하우징 분야에서 또 하나의 강점으로 내세우는 것은 다름아닌 자사의 컨설팅 서비스 기술과 컨설팅 협력업체와의 파트너 쉽이다.이같은 컨설팅은 데이타 웨어하우스를 구현하는데 아주 중요한 요소로 작용하고 있 다.
그렇지만 오라클이 경쟁 업체들과 차별화되는 가장 큰 특징은 뭐니 뭐니해도 80여개 이상의 운영체제와 SMP, 클러스터, MPP등 모든 형태의 하드웨어를 지원하는 유일한 업체라는 점이다. 고객들은 오라클 데이타베이스의 동일한 버젼을 데스크 탑이나 랩 탑 에서 부터 웍그룹용 혹은 부서용 서버에는 물론 더 나아가 전사를 지원하는 데이타 센터용 대용량 환경 등에서 원하는 대로 사용 할 수 있다. 이와 같은 이기종간의 데이타 호환성 보장은 장차 기업이나 조직내에서 새로이 도입하게 될 하드웨어나 운영체계의 기종이 바뀌더라도 기존의 투자가치를 최대로 보호할 수 있다는 장점을 제공한다.
▶ 데이타 웨어하우스와 데이타 마트
데이타 웨어하우스가 각광을 받는 이면에는 기존의 시스템들이 급변하는 비즈니스 환경을 적절하게 지원하지 못한다는 전제가 도사리고 있다. 전산 도입 초창기의 데이타 처리 시스템은 일련의 비즈니스 행위 루틴들을 자동화하여 경쟁력을 제고할 수 있도 록 도왔으며, 비즈니스 운영 프로세스들을 개선시키는 역할을 하였다. 그러나 이같은 장점에도 불구하고 경쟁업체의 소위 따라잡 기식 전산 솔루션 구현으로 인해 일반업체의 데이타 처리 애플리케이션 자체의 수명은 상당히 단축되고 있다.
데이타 웨어하우징 시스템의 목적은 데이타 웨어하우스내에 저장된 정보를 정확하고도 시기적절하게 손쉽게 액세스할 수 있도록 함으로써 보다 정확한 비즈니스 의사 결정 수립을 가능하게 하는 것이라고 할 수 있다. 비즈니스와 관련한 의사결정이 뛰어날 경우 기존의 데이타 처리 위주의 애플리케이션에서 기대하기
힘든 영향력이 발휘될 가능성이 짙다. 데이타 웨어하우징은 의사 결정권자들이 기존의 시스템은 물론, 클라이언트/서버, 병렬처 리 아키텍쳐 및 인터넷 기술 등 동원가능한 모든 테크닉을 활용할 수 있도록 해야 진정한 의미를 지닌다고도 할 수 있다.
데이타 웨어하우스는 데이타 저장 범위에 따라 크게 다음과 같이 2가지로 구분된다.
1. 전사적인 데이타 웨어하우스:
이는 기업 전체에 걸친 데이타와 외부 소스에서 입수되는 정보를 하나로 통합한 것을 의미한다. 전사적인 데이타 웨어하우스는 그 범위가 업무구분과 관계없이 넓고, 대개 요약 데이타와 상세 데이타 모두를 포함하므로 수백기가 바이트에서 부터 테라바이트 그 이상까지도 확대된다. 이같은 전사적인 데이타 웨어하우스는 전통적인 메인프레임상에서 구현되기도 하며, UNIX 슈퍼 서버나 병렬 플랫폼을 주로 이용한다.
2. 데이타 마트:
데이타 마트는 전사적인 데이타의 부분 집합격으로 특정 사용자나 대상 (종종 LOB, 즉 Line of Business라고 함)에게 가치가 있 는 데이타들을 포함하는 작은 웨어하우스이다. 이들 데이타는 주로 사용자들 그룹내의 데이타를 중심으로 필요시 다른 부서나 그 룹의 데이타를 가져오고 외부의 정보를 포함하기도 한다.
전국적인 규모의 유통업체의 경우 서울지역에서 판매된 제품에 대한 요약 데이타의 경우 데이타 마트로 간주될 수 있다. 데이타 마트는 대개 UNIX나 NT 또는 OS/2와 같은 운영체계를 사용하는 저가의 부서급 서버상에서 구현된다.
데이타 마트는 그것이 사용하는 데이타 소스에 따라 두 가지로 분류된다.
· 독립적 데이타 마트(independent data mart)는 기존의 운영계 시스템과 외부 데이타를 소스로 한다. 어떠 한 경우는 데이타 마트에 들어갈 데이타가 특정 부서나 작업현장에서 새로이 생성된 것일 수도 있다.
· 종속적 데이타 마트(dependent data mart)는 전사적 데이타 웨어하우스에서 직접 소스 데이타를 추출한다 .
전사적인 데이타 웨어하우스와 데이타 마트의 주요 차이를 다시 한 번 정리해보면, 데이타 웨어하우스는 기업 혹은 조직 전체의 상세 데이타를 포함하며, 규모면에서 "Cross Functional"하다고 할 수 있는 반면, 데이타 마트는 전사적인 데이타 중의 일부를 갖고 Line-of-business를 지원하게 된다. 여기서 주지할 사실은 데이타 베이스 자체의 사이즈가 둘 사이를 구분하는 지표가 되는 것이 아니며, 사용자의 "function"이 구분의 기준이 된다는 것이다. 오늘날 운영되고 있는 데이타 마트의 대부분은 50GB 미만이지만, 사용자들은 이들의 크기가 수년내에 두 배이상 성장할 것으로 예측하고 있다. 데이타 마트에 접속하는 사용자의 수 역시 전형적으로는 50명 미만 이 대부분이지만 역시 이 숫자도 쉽게 증가할 것으로 예측되고 있다.
데이타 웨어하우스의 구축, 관리, 액세스를 담당하는 인원이 대부분 기업의 엄선된 고급인력인 것에 비하여, 상대적으로 데이타 마트의 담당인원은 데이타 웨어하우스의 경우만큼 고급인력이 아닌 경우가 많다. 따라서 데이타 마트의 경우에는, 즉시 사용가 능하고 사용이 편리한 툴과 그것을 위한 지원이 필수적이다.
데이타 마트의 구현 싸이클은 몇 개월 혹은 몇 년 이라기 보다는 몇 주로 자주 거론된다. 비용 역시 데이타 웨어하우스에 비해 상대적으로 매우 저렴하다. 전형적인 데이타 마트의 경우 구현 싸이클이 대개 3개월에서 6개월 사이이며, 비용은 10만 달러에서 30만 달러 사이이다. 하지만 이는 물론 환경에 따라 달라질 수 있다.
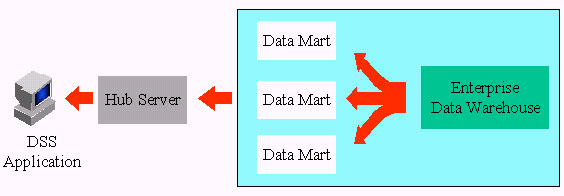
대부분의 조직들은 결국에는 전사급의 데이타 웨어하우스와 데이타 마트들을 통합 구조로 가져가는 Multi-Tier방식의 웨어하우 스를 구현할 것으로 보인다. 이같은 경우를 표현한 것이 다음 그림이다.
그림 : Multi-tier 방식의 데이타 웨어하우스
 11
11
이같은 다중 티어 방식의 아키텍쳐에서 데이타의 위치는 그 데이타에 대한 무결성(그 값이 정확하여 결함없이 완벽한 가치를 지 녀야 한다는 데이타의 속성)을 최대한 보장하는 범위 내에서 최고의 가용성과 시스템 성능을 확보할 수 있도록 존재해야 한다.
데이타 마트의 이론적 해석
초기의 데이타 웨어하우스 지지자들은 전통적인 Top-down 접근방식로 전사급의 데이타 웨어하우스를 먼저 구축하고 난 후, 이 전사적 웨어하우스의 데이타를 이용하는 데이타 마트들을 구축할 것을 강력하게 권유하였다.
이같은 top-down 방식은 다음과 같은 장단점을 지닌다:
장점은 전사적인 문제 해결에 대한 기회를 부여하는 것으로 시작된다. 또한 큰 그림을 갖고 접근함으로써 로드 맵(roadmap)제시가 분명하다는 것이다. 또한 데이타 웨어하우스를 구현하면서 연관되는 여러개의 서브 프로젝트들을 통합하면서 발생할 수 있는 문제들을 최소화할 수 있다 는 장점이 있다.
단점은 우선 프로젝트 기간이 오래 - 대개 1년 이상 - 걸린다는 것과 비용이 많이 소요된다는 점을 들 수 있으며, 이로 인한 기대 이하의 투자회수율 및 기능에 대한 가능성도 문제시 될 수 있다. 그 이유로는 다양한 단위 조직(Line of Business)의 요구 에 공통으로 부응하도록 하는 공통의 메타 데이타(Meta Data) 모델에 대한 일관성이라든지 교감(consensus)의 부족 등이 될 수 있다.
요즘의 경제 상황과 지구촌을 하나로 묶는 시장에서의 경쟁을 생각해보면 조직이 필요한 것은 단지 신속하게 급변하는 비즈니스 의 조건에 맞는 대응책만이 아닌, 앞으로 새로이 다가올 비즈니스 기회를 예측하여 투자를 최소화하면서도 이 기회를 놓지지 않 도록 해주는 능력인지도 모른다. 이러한 측면에서 기간이 긴 프로젝트는 적절치 못할 수도 있다.
이와 같은 추이는 기업이나 조직들로 하여금 미래에 나타날 문제는 최소화 하면서도 가능한한 적은 투자로 최대의 효과를 볼 수 있는 유연한 솔루션을 찾도록 유도하고 있다. 그 중 하나의 움직임이 바로 비교적 저렴한 서버 플랫폼상에 독립적 데이타 마트 를 구축하는 것으로서, 이 방법은 전사적 데이타 웨어하우스를 top-down 방식으로 구축하는데서 기인하는 결점들을 보완할 수 있 다고 평가된다.
그러나 이러한 bottom-up 방식의 독립적 데이타 마트 역시 그것이 가지고 있는 많은 장점에도 불구하고 다음과 같은 단점을 내 재하고 있다.
워크그룹이나 부서단위의 독립적 데이타 마트의 숫자가 IS실에서 통제하기 어려울 정도까지 확산 될 수 있고, 이 경우 추후 엔 터프라이즈 데이타 웨어하우스로의 방향을 어렵게 만들수 있다. 아마도 가장 심각한 문제는 각각의 데이타 마트에서 사용하는 비 즈니스 용어(terminology) 와 시맨틱(sematic) 및 데이타 포맷, 또는 표시방식 등의 차이라고 할 수 있겠다.
한 곳의 독립적 데이타 마트 사용자가 다른 독립적 데이타 마트에도 액세스를 하려면 그림에서와 같이 "허브 서버(hub s erver)"를 가지는 구성도를 가져야만 할 것이다. 허브 서버는 여러 개의 데이타 마트들이 분산되어 있는 환경에서 사용자들 이 자유롭게 각각의 데이타 마트에 들어있는 정보들을 액세스 할 수 있도록 도와주는 일종의 게이트웨이라고 할 수 있다. 허브 서버는 단순히 액세스를 제공하는 이외에 보안, 비즈니스 뷰와 같은 서비스를 제공함으로써 튜닝에도 기여할 수 있어야 한다. 그 림 2에서와 같이 여러 개의 허브 서버가 사용될 수도 있겠으나 이같은 방식은 사실 썩 권장할 만한 것이 아니다. 왜냐하면 그림 과 같은 경우는 일단 설치 및 관리가 용이하지 않으며, 또 주어진 질의가 여러 개의 데이타 마트로부터 데이타를 필요로 하는 경 우에 성능이 크게 저하될 가능성이 높기 때문이다. 따라서 허브 서버의 존재 가치는 다분히 데이타 마트의 통합을 위한, 혹은 더 나아가 multi-tier 방식의 데이타 웨어하우스 구현을 위한 임시방편으로서 인식되고 있다.
하지만 한 가지 언급하여 둘 것은 이러한 별개의 독립적 데이타 마트 간 액세스는 그리 흔한 경우가 아니라는 것이다. 독립적 데이타 마트는 서로 상이한 데이타 모델, 포맷, 표시방식, 비즈니스 용어 및 시맨틱을 및 데이타 포맷, 또는 표시방식 등을 가질 가능성이 많기 때문이다.
그림 :분산 데이타 마트 환경
[img12]
이로서 top-down 및 bottom-up 방식 모두 나름대로의 장점 및 단점이 있다는 것을 알게 되었을 것이다. 이러한 점들을 고려할 때, 워크그룹이나 부서단위의 독립적 데이타 마트로 시작하여 전사적인 데이타 웨어하우스로 접근하는 소위 bottom-up 방식을 택 하고자 하는 조직들은 저렴하면서도 포괄적인, 그리고 사용하기 쉬우면서도 잘 통합된 제품 및 기술지원을 필요로 한다. 여기 에 추가되어야 할 조건으로는 데이타의 양이나 사용자의 수가 증가했을 때 이를 해결할 수 있는 가, 기존의 혹은 향후의 multi-t ier 웨어하우스와 통합될 수 있는 가 등을 들 수 있겠다. 가장 이상적인 경우는 내가 원하는 조건을 갖춘 데이타 마트에 꼭 맞도 록 만들어진 패키지를 구매하여 사용하는 것이지만, 이는 어려운 일이다.
데이타 웨어하우스의 경우와 마찬가지로 데이타 마트에 있어서도 어느 특정 업체가 모든 솔루션을 제공하기를 기대하기란 쉬 운 일이 아니다. 따라서, 데이터 마트를 구현하고자 하는 조직에서는 여러 업체들의 소위 "최고(Best-of-Breed)" 제 품들을 잘 살펴보아야만 한다.
데이타베이스 소프트웨어 업체인 오라클은 데이타 마트 솔루션으로서 Oracle Data Mart Suite를 제공한다. 이 솔루션은 데이타 마트 구축의 전과정을 지원하는 통합된 제품군, 즉시 사용가능한 응용 프로그램 및 지원을 포함한다. 이 솔루션은 Oracle Wareho use 프레임웍과 함께 토탈 솔루션을 제공, 전사적 데이타 웨어하우스, 데이타 마트, multi-tier 데이타 웨어하우스 등 모든 종류 의 데이타 웨어하우스 솔루션을 포괄한다.
여기서 Oracle Data Mart Suite가 제공하는 강점과 함께, 이 제품의 확장성, 전사적 데이터 웨어하우스로의 전개 및 통합 능력 에 초점을 맞추었다.
그림 : Oracle Warehouse
[img13]
Oracle Data Mart Suite의 구성요소는 다음과 같다.
1. Data Mart Designer
2. Data Mart Builder
3. Oracle Enterprise Server
4. Web Application Server
5. Oracle Discoverer
다음은 Oracle Data Mart Suite의 각 구성요소에 간단한 설명 및 주요기능이다.
Data Mart Designer는 데이타 마트 구축 과정에 있어 디자인 부분을 지원한다. 기존 운영계 시스템의 모델로부터 데이타 마트를 디자인하고, 그 디자인된 모델을 repository에 저장한다. 그리고 데이타 마트용 Oracle7 DBMS 생성을 위한 SQL DDL을 생 성한다.
Data Mart Designer 주요기능:
1. 데이타 마트의 소스가 되는 기존의 운영시스템 데이타에 대한 reverse engineering. 이렇게 생성된 모델은 ROLAP을 위한 스 타 스키마 디자인을 위한 모델로 변경도 가능하다.
2. 기존의 운영계 시스템 모델로부터 데이타 마트 모델을 만들어 낼 수 있는 Data Schema diagrammer를 제공한다.
3. 이렇게 생생된 데이타 마트 디자인을 저장하는 repository를 제공하며, 이 repository는 Data Mart Builder에 의해 액세스 된다.
4. Oracle Enterprise Server 상에 데이타 마트 테이블을 만드는 SQL DDL을 생성한다.
또한 Data Mart Designer는 Web Application Server용 응용프로그램을 디자인하고 생성할 수 있다. Web Application Server 응 용프로그램이란 정적인 HTML 페이지가 아닌 동적인 데이타를 가지는 응용프로그램을 말한다. 즉, 최종 사용자는 웹브라우저를 통 해 데이타 마트의 정보에 액세스할 수 있게 되는 것이다. 예를 들자면, Data Mart Designer를 이용해 메뉴 스타일의 홈페이지를 만들거나, 마스터-디테일-디테일의 계층을 갖는 웹사이트의 제작을 할 수 있다. 대부분의 웹 애플리케이션이 하이퍼링크를 통해 사용자가 관심있는 정보들을 오가는 것에 제한된 것에 반해, Data Mart Designer로 만들어진 PL/SQL 기반의 이러한 웹 애플리케 이션은 새로운 데이타의 삽입, 갱신, 삭제 등을 가능케 한다.
Data Mart Designer는 Oracle Designer에서 OLTP 시스템에서만 필요한 기능부분을 빼고, 데이타 마트의 설계와 구축에 필요한 부분만을 모아 만들어진 제품이다.
Data Mart Builder는 데이타 마트를 위한 데이타 추출 및 그 데이타를 실제 데이타 마트에 로딩하는 부분을 지원한다. 이 기술은 오라클이 Sagent로부터 라이센스한 추출 및 변환(ETT) 제품이다. 이 제품은 데이타 소스로부터 타겟 데이타베이스로의 정보의 흐름을 관리하는 일련의 툴의 모음이다. 운영계 시스템 또는 전사적 데이타 웨어하우스로부터 데이타를 추출하여, 그 정 보의 변환 및 데이타 마트로의 로딩을 담당한다. 이러한 추출 및 변환과정은 data flow를 통해 정의된다
다음그림은 데이타가 source와 sink 사이를 흐르며 정의되는 data flow를 보여준다. 그림에서 source는 운영계 데이타베이스이며, sink는 데이타 마트의 테이블이다. Data flow 상의 각각의 아이콘은 이러한 프로세스의 각 부분의 과정을 의 미한다. 각 과정의 결과물은 result set이라 불리며, 이것은 다음 과정의 입력정보가 된다. 이러한 각각의 과정들은 서로 연결되어 하나의 Plan을 구성하며, 이것은 추후의 사용을 위해 repository에 저장할 수 있다. 이러한 Plan은 필요시 구 동하거나 스케줄 기능을 이용하여 특정한 시간 또는 일정한 간격으로 구동시킬 수 있다. 스케줄된 Plan이 구동될 때 사용자에게 이것을 e-mail로 알릴 수 있는 기능도 있다.
[img14]
위 그림에서의 data flow의 첫번째 과정은 운영계 데이타베이스로부터 데이타를 획득하는 것이며, 마지막 과정은 이 획득한 데 이타를 스타 스키마로 설계된 데이타 마트의 사실 테이블( fact table)에 로딩하는 것이다. 중간의 과정들은 스타 스키마의 차원 테이블(dimension table)로부터 사실 테이블의 primary key를 생성하기 위한 key들을 추출하는 과 정이다. 사실 테이블로 로딩된 데이타는 그림 6 상의 Grid라 표시된 부분에서 사용자의 화면에 표시된다.
Data flow는 드랙 앤 드롭 인터페이스를 사용, Data Flow Editor 상에서 생성되고 관리된다. Data Flow Editor는 Plan의 각 과 정에서 수행될 transform (변환)을 지정하는 데 사용된다.
· SQL Query transform은 소스로부터 로딩할 데이타를 선택하는 변환이다. 소스 데이타베이스가 지원하는 어떠한 S QL SELECT문도 가능하다.
· CSV Source transform은 CSV (comma-separated values) 포맷의 레코드를 포함하고 있는 파일을 변환하는 과정이 다. 이 변환은 데이타베이스의 import 유틸리티나 외부 툴을 사용할 경우 매우 유용하다. CSV Sink transform은 CSV 포맷 의 파일을 생성할 수 있는 변환이다.
· Save to Table transform은 Plan의 결과를 관계형 테이블에 저장하는 변환이다.
· Batch Loader transform은 Plan의 결과를 오라클 관계형 테이블에 로딩하는 변환이다.
· Grid transform은 Plan의 결과를 사용자 화면 상에 표시하는 변환이다.
· Time Generation, Time Lookup, Key Generation, Key Lookup transform은 스타 스키마 구 조의 데이타 마트를 구성하는 데이타를 생성하는 변환이다.
. Join 및 Union transform은 두 개의 data flow에서 하나의 결과물을 생성하는 변환이다.
. Splitter transform은 하나의 결과물을 두 개의 복사본으로 변환시킨다.
· Column Select, Add Column, Substring, Search & Replace, Filter transform 은 data flow 상의 데이타를 원하는 내용으로 변경시키는 변환이다.
· Rank, Running Average, Running Total, Moving Total, Percentage of Total, Moving A verage, Memory Sort transform은 data flow의 결과에 대하여 통계적 분석을 가하는 변환이다.
· Broadcast Grid, Broadcast Receiver transform은 Plan의 결과를 다른 사용자들 간에 전송시키는 변환이 다.
위의 소개된 내용은 Data Mart Builder가 제공하는 주요 변환작업들이다. 이 제품의 중요한 이점 중 하나는 이 transform들이 M icrosoft COM 객체로서 코딩되었다는 것이다. 이것은 새로운 방식의 변환을 추가하는 것이 용이하고, 사용자들이 COM 객체를 지 원하는 타 제품과 연계할 수 있다는 것을 의미한다. 새로운 transform은 Microsoft COM을 지원하는 어떠한 언어로도 개발이 가 능하다. Data Mart Builder는 사용자 정의 transform의 생성과 컴파일을 위해 VBScript (Microsoft Visual Basic Scripting Edit ion) 에디터를 제공한다.
Oracle Enterprise Server는 오라클 데이타 마트 솔루션의 핵심이 되는 부분으로, 데이타 마트의 데이타를 관리하는 부 분이다.
Oracle Enterprise Server는 데이타 웨어하우스 환경의 핵심이다. 보편적으로 데이타 웨어하우스는 매우 많은 양의 데이타를 가 지게 되며, 사용자들이 효과적으로 액세스할 수 있고 사용자의 질의에 대해 적절한 속도로 응답해야 한다. 조사에 따르면 보통 데이타 마트는 50GB 이하의 용량을 가진다고 하지만, 이것은 비교적 짧은 기간에 급속도로 증가할 가능성이 많다. Oracle Enterp rise Server는 테라바이트급의 데이타 웨어하우스를 지원하며, 복잡한 질의 프로세싱 및 신속한 응답시간의 지원을 위한 각종 병 렬처리 기능을 가지고 있다. 이중 중요한 기능으로는 내부병렬질의, 병렬 인덱스, 병렬 데이타 로드, 병렬 백업/복원, 병렬 복구 등이 있다. 특히 Oracle 7.3부터는 데이타 웨어하우스를 위한 많은 기능향상이 있었다. 해쉬 조인, 비트맵 인덱스, 스타 쿼리 옵티마이저, 비용기바 병렬 옵티마이저 등은 질의 수행시간을 크게 단축시켰다. Oracle Parallel Server는 MPP (massively paral lel processing)를 효과적으로 지원함으로써 확장성과 수행속도에 있어 새로운 수준의 향상을 가져왔다. 관계형 데이타 지원 이 외에, Oracle Enterprise Server는 ConText Cartridge를 이용한 텍스트 데이타에 대한 액세스, Spatial Cartridge를 이용한 지형 및 공간 데이타 액세스, Oracle Video Server를 통한 멀티미디어 데이타 액세스를 지원한다.
Web Application Server는 오라클의 웹 응용프로그램 개발을 위한 플랫폼이다. Oracle Web Application Server는 응용프 로그램을 웹서버 상에 플러그 인하는 카트리지를 지원하는 Web Request Broker (WRB)를 포함한다. WRB는 멀티-쓰레드, 멀티-프로 세스 아키텍처의 고성능 다수사용자 관리, 로드 밸런싱을 지원하며, 써드 파티 웹서버와 함께 사용, 기존의 웹 애플리케이션 환 경을 확장시킬 수도 있다. WRB API는 개발자가 Java, PL/SQL, LiveHTML, C, C++ 등의 서버 카트리지를 개발할 수 있는 환경을 제 공한다. PL/SQL Agent는 개발자가 PL/SQL로 쓰여진 저장 프로시저(stored procedure)를 웹 응용프로그램에 사용할 수 있도록 1한 다. 즉, 사용자는 웹 페이지 상의 링크를 클릭함으로써 오라클 저장 프로시저를 사용, 사용자의 요구에 의해 즉시 동적인 HTML 생성이 가능하다.
Oracle Discoverer는 데이타 마트에서 질의 및 분석 부문을 지원한다. Oracle Discoverer는 최종사용자를 위한 질의, 보 고서작성, 드릴링, 피벗, 웹 출력 툴로, 데이타 웨어하우스에의 신속한 액세스를 제공한다.
· 철저한 테스트를 거친 사용자 인터페이스는 복잡한 구조의 데이타베이스를 최종 사용자가 간편히 사용할 수 있도록 생성 된 end user layer에 기반하고 있다. Discoverer를 사용함에 있어 사용자는 기술적인 용어를 접하는 것이 아니라 일반 업무용어 로 바뀌어진 정보를 조작하게 된다. 관리자는 서버 상의 여러 작업 및 요약 데이타 작업이 다른 제품보다 훨씬 사용하게 쉽다는 것을 발견하게 될 것이다.
· 또한 end user layer는 요약 테이블의 자동 생성 및 관리를 가능케 하며, 실행된 질의에 대한 통계를 수집, 효과적인 요 약 테이블의 관리를 가능하게 한다.
· 이미 실행된 질의 뿐만 아니라 실행될 질의에 대한 예측 기능도 제공하여, 지나치게 오래 걸리는 질의를 방지할 수 있다 .
· 데이타 마트 상의 데이타에 대한 drill down, drill across, drill to detail는 물론, Excel 스프레드쉬트, 웹 브라우저 , Word 문로의 drill out 하는 등의 정보 탐색작업을 매우 간편하게 할 수 있다. Oracle Discoverer로 작성된 보고서는 웹 브라 우저를 통한 액세스를 위해 HTML로 변환할 수 있다.
요약
Oracle Data Mart Suite는 데이타 마트 구축 전과정을 제공하는 포괄적인 솔루션이다. 또한 데이타 마트 구축을 위한 통합된 제품구성, one-stop shopping, 기술지원을 제공한다.
Oracle Enterprise Server는 Oracle Data Mart Suite에 있어 핵심이 되는 부분이며, 이는 또한 Oracle Warehouse 프레임웍의 핵 심이기도 하다. Oracle Data Mart Suite과 Oracle Warehouse 프레임웍으로 구성된 오라클의 데이타 웨어하우스 솔루션은, 주제단 위 데이타 마트에서 전사적 데이타 웨어하우스에 이르기까지, 어떠한 방식의 데이타 웨어하우스도 효과적으로 구축할 수 있다.
결론
전사적인 규모의 데이타 웨어하우스 프로젝트의 기간과 비용 등의 제반 문제로 인해 기업이나 조직 내에서는 점차 부서단위나 업무별의 데이타 마트 구축에 대한 관심이 커지고 있다. 이같은 독립적 데이타 마트(independent data mart) 접근방식 (또는 bot tom-up 접근방식)은 여러 업체들로 하여금 각자 이에 적합한 솔루션을 제시하도록 유도하고 있으나, 다른 경우와 마찬가지로 한 벤더가 모든 조건을 만족시키기에는 어려움이 있을것이다.
Appendix: Oracle Warehouse
오라클은 어떠한 소스(source)라도, 어떠한 형태의 데이타라도, 어떠한 형태의 액세스라도 지원하겠다는 대전제를 두고 포괄적 인 제품 세트와 컨설팅 서비스를 제공함은 물론 업계의 주요 ISV들과의 긴밀한 파트너쉽을 통해 신속하고도 성공적인 데이타 웨 어하우스 구현 방향을 제시하고 있다.
이같은 오라클의 전략을 가능하게 하는 중심은 바로 Oracle Universal Data Server이다. 이 오라클 데이타베이스는 다양한 형태 의 비정형 데이타 (예: 비디오, 텍스트, 이미지, 다차원 데이타 등)를 의사결정지원용 애플리케이션에서 실제 활용할 수 있도록 해 주는 새로운 영역을 제시하고 있다.
데이타 웨어하우스를 구현하는 데 필요한 과정에는 웨어하우스를 디자인하는 과정, 데이타를 소스로부터 웨어하우스로 옮기는 과정, 웨어하우스 내의 데이타를 관리하는 과정, 그리고 웨어하우스 데이타를 액세스하는 과정 등 크게 3~4가지의 과정이 포함된 다. Oracle Warehouse 프레임웍은 이들 각각의 과정을 자사 및 써드 파티 제품을 이용하여 지원하고 있으며 여기서는 오라클 제 품 중심의 간단한 설명만을 싣기로 한다.
· Designing: 디자인 과정을 지원하는 오라클 제품에는 Oracle Designer가 있다. Oracle Designer는 단순히 디자인만을 지원하는 것이 아니고, 메타 데이타를 관리하는 데도 이용된다. Oracle Designer는 BPR을 위한 복잡한 시스템 모델 링, 분석, 다이어그램 설계 지원용 툴로써 데이타 웨어하우스를 BPR과 연계된 프로젝트로 고려하고 있는 경우 아주 효과적으로 이용할수 있다.
· Building or Loading: 데이타를 소스로부터 데이타 마트나 데이타 웨어하우스로 옮기는 과정을 지원하는 대표적인 오라클 제품에는 Oracle Open Gateway, Oracle Parallel Loader, Oracle Symmetric Replication 등이 있다. Oracle Op en Gateway는 무려 35종 이상의 비오라클 데이타 소스를 오라클 데이타 웨어하우스로 추출하게 해준다. Oracle Parallel Loader 는 대용량의 데이타 웨어하우스에 특히 효과적으로 사용될 수 있도록 고속의 직접 경로를 통하여 로딩작업을 하도록 해주는 유틸 리티이다. Oracle Symmetric Replication은 운영계 시스템에서의 데이타 변동사항을 사용자가 원하는 데로 데이타 마트나 웨어하 우스에 반영되도록 해주는 아주 중요한 기술이다. 또한 오라클은 다양한 ERP 패키지 -- Oracle Applications, PeopleSoft, SAP 등 -- 를 위한 추출 솔루션을 가지고 있으며, 한국오라클에서 자체개발한 K*Loader는 업계 최고의 속도를 자랑한다.
· Managing: 데이타 마트나 웨어하우스 내에 저장 관리되는 다양한 종류의 데이타에 대한 책임은 Oracle Un iversal Data Server (Oracle7 또는 Oracle8)가 맡는다. 이밖에도 데이타 웨어하우스 시스템를 구성하는 데이타베이스와 네트워 크 및 애플리케이션 전반에 걸친 관리를 위한 Oracle Enterprise Manager가 있다.
· Reporting and Analyzing: 데이타 마트나 데이타 웨어하우스 내의 데이타를 분석하는 것은 더 나은 비즈 니스 결정을 위해 필수적인 과정이다. 분석을 위해서는 다양한 기술이 동원되는데, 단순 질의 및 리포팅에서부터 드릴다운(drill down) 등을 이용한 복잡한 분석 등이 여기에 포함된다. 오라클은 이러한 리포팅 및 분석을 위해 Oracle Reports, Oracle Discov erer, Oracle Express 제품군을 공급하고 있다.
Oracle Reports는 오라클의 분석툴(Discoverer 및 Express)과 밀접하게 통합되어 있어, 분석의 결과물을 사용자가 원하는 어떠 한 포맷으로도 출력이 가능하게 하여 주는 제품이다.
Oracle Discoverer는 관계형 데이타 웨어하우스를 기반으로 하는 환경에서 드릴다운, 피벗과 같은 기능을 이용하여 분석을 하 고 질의 및 리포팅을 할 수 있는 제품이다.
Oracle Express는 객체지향의 다차원 분석 제품군이다. Oracle Express Analyzer는 각종 비정형 질의를 데스크탑 및 이동 환경 에서 가능토록 하는 제품이다. Oracle Express Objects는 객체지향의 OLAP 애플리케이션 개발 툴로서, 커스텀 질의/리포팅 애플 리케이션 개발 환경을 제공한다. Oracle Express Web Agent는 최종 사용자의 다차원 분석을 인트라넷이나 월드 와이드 웹을 통해 실행할 수 있도록 하여 준다.
Oracle Express와 Oracle Discoverer 역시 통합된 기능성을 제공한다. Discoverer의 질의 결과를 Express로 보내어 다차원 분 석을 할 수 있으며, Express 상에서 버튼 하나로 Discoverer의 데이타로 드릴이 가능하다.
|
