|
Hierarchies
Generalization Hierarchies
Up to this point, we have discussed describing an object, the entity, by its shared characteristics, the attributes. For example, we can characterize an employee by their employee id, name, job title, and skill set.
Another method of characterizing entities is by both similarities and differences. For example, suppose an organization categorizes the work it does into internal and external projects. Internal projects are done on behalf of some unit within the organization. External projects are done for entities outside of the organization. We can recognize that both types of projects are similar in that each involves work done by employees of the organization within a given schedule. Yet we also recognize that there are differences between them. External projects have unique attributes, such as a customer identifier and the fee charged to the customer. This process of categorizing entities by their similarities and differences is known as generalization.
Description
A generalization hierarchy is a structured grouping of entities that share common attributes. It is a powerful and widely used method for representing common characteristics among entities while preserving their differences. It is the relationship between an entity and one or more refined versions. The entity being refined is called the supertype and each refined version is called the subtype. The general form for a generalization hierarchy is shown in Figure 8.1.
Generalization hierarchies should be used when (1) a large number of entities appear to be of the same type, (2) attributes are repeated for multiple entities, or (3) the model is continually evolving. Generalization hierarchies improve the stability of the model by allowing changes to be made only to those entities germane to the change and simplify the model by reducing the number of entities in the model.
Creating a Generalization Hierarchy
To construct a generalization hierarchy, all common attributes are assigned to the supertype. The supertype is also assigned an attribute, called a discriminator, whose values identify the categories of the subtypes. Attributes unique to a category, are assigned to the appropriate subtype. Each subtype also inherits the primary key of the supertype. Subtypes that have only a primary key should be eliminated. Subtypes are related to the supertypes through a one-to-one relationship.
Types of Hierarchies
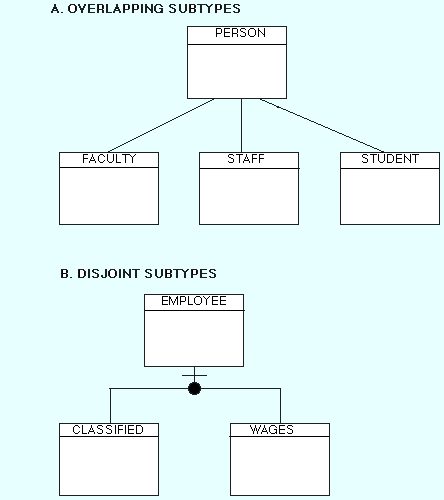
A generalization hierarchy can either be overlapping or disjoint. In an overlapping hierarchy an entity instance can be part of multiple subtypes. For example, to represent people at a university you have identified the supertype entity PERSON which has three subtypes, FACULTY, STAFF, and STUDENT. It is quite possible for an individual to be in more than one subtype, a staff member who is also registered as a student, for example.
In a disjoint hierarchy, an entity instance can be in only one subtype. For example, the entity EMPLOYEE, may have two subtypes, CLASSIFIED and WAGES. An employee may be one type or the other but not both. Figure 1 shows A) overlapping and B) disjoint generalization hierarchy.
Figure 1: Examples of Generalization Hierarchies
Rules
The primary rule of generalization hierarchies is that each instance of the supertype entity must appear in at least one subtype; likewise, an instance of the subtype must appear in the supertype.
Subtypes can be a part of only one generalization hierarchy. That is, a subtype can not be related to more than one supertype. However, generalization hierarchies may be nested by having the subtype of one hierarchy be the supertype for another.
Subtypes may be the parent entity in a relationship but not the child. If this were allowed, the subtype would inherit two primary keys.
Summary
Generalization hierarchies are a structure that enables the modeler to represent entities that share common characteristics but also have differences.
Integrity Rules
Add Data Integrity Rules
Data integrity is one of the cornerstones of the relational model. Simply stated data integrity means that the data values in the database are correct and consistent.
Data integrity is enforced in the relational model by entity and referential integrity rules. Although not part of the relational model, most database software enforce attribute integrity through the use of domain information.
Entity Integrity
The entity integrity rule states that for every instance of an entity, the value of the primary key must exist, be unique, and cannot be null. Without entity integrity, the primary key could not fulfill its role of uniquely identifying each instance of an entity.
Referential Integrity
The referential integrity rule states that every foreign key value must match a primary key value in an associated table. Referential integrity ensures that we can correctly navigate between related entities.
Insert and Delete Rules
A foreign key creates a hierarchical relationship between two associated entities. The entity containing the foreign key is the child, or dependent, and the table containing the primary key from which the foreign key values are obtained is the parent.
In order to maintain referential integrity between the parent and child as data is inserted or deleted from the database certain insert and delete rules must be considered.
Insert Rules
Insert rules commonly implemented are:
Dependent. The dependent insert rule permits insertion of child entity instance only if matching parent entity already exists.
Automatic. The automatic insert rule always permits insertion of child entity instance. If matching parent entity instance does not exist, it is created.
Nullify. The nullify insert rule always permits the insertion of child entity instance. If a matching parent entity instance does not exist, the foreign key in child is set to null.
Default. The default insert rule always permits insertion of child entity instance. If a matching parent entity instance does not exist, the foreign key in the child is set to previously defined value.
Customized. The customized insert rule permits the insertion of child entity instance only if certain customized validity constraints are met.
No Effect. This rule states that the insertion of child entity instance is always permitted. No matching parent entity instance need exist, and thus no validity checking is done.
Delete Rules
Restrict. The restrict delete rule permits deletion of parent entity instance only if there are no matching child entity instances.
Cascade. The cascade delete rule always permits deletion of a parent entity instance and deletes all matching instances in the child entity.
Nullify. The nullify delete rules always permits deletion of a parent entity instance. If any matching child entity instances exist, the values of the foreign keys in those instances are set to null.
Default. The default rule always permits deletion of a parent entity instance. If any matching child entity instances exist, the value of the foreign keys are set to a predefined default value.
Customized. The customized delete rule permits deletion of a parent entity instance only if certain validity constraints are met.
No Effect. The no effect delete rule always permits deletion of a parent entity instance. No validity checking is done.
Delete and Instert Guidelines
The choice of which rule to use is determined by Some basic guidelines for insert and delete rules are given below.
Avoid use of nullify insert or delete rules. Generally, the parent entity in a parent-child relationship has mandatory existence. Use of the null insert or delete rule would violate this rule.
Use either automatic or dependent insert rule for generalization hierarchies. Only these rules will keep the rule that all instances in the subtypes must also be in the supertype.
Use the cascade delete rule for generalization hierarchies. This rule will enforce the rule that only instances in the supertype can appear in the subtypes.
Domains
A domain is a valid set of values for an attribute which enforce that values from an insert or update make sense. Each attribute in the model should be assigned domain information which includes:
Data Type—Basic data types are integer, decimal, or character. Most data bases support variants of these plus special data types for date and time.
Length—This is the number of digits or characters in the value. For example, a value of 5 digits or 40 characters.
Date Format—The format for date values such as dd/mm/yy or yy/mm/dd
Range—The range specifies the lower and upper boundaries of the values the attribute may legally have
Constraints—Are special restrictions on allowable values. For example, the Beginning_Pay_Date for a new employee must always be the first work day of the month of hire.
Null support—Indicates whether the attribute can have null values
Default value (if any)—The value an attribute instance will have if a value is not entered.
Primary Key Domains
The values of primary keys must be unique and nulls are not allowed.
Foreign Key Domains
The data type, length, and format of primary keys must be the same as the corresponding primary key. The uniqueness property must be consistent with relationship type. A one-to-one relationship implies a unique foreign key; a one-to-many relationship implies a non-unique foreign key.
Bibliography
Works Cited
Batini, C., S. Ceri, S. Kant, and B. Navathe. Conceptual Database Design: An Entity Relational Approach. The Benjamin/Cummings Publishing Company, 1991.
Date, C. J. An Introduction to Database Systems, 5th ed. Addison-Wesley, 1990.
Fleming, Candace C. and Barbara von Halle. Handbook of Relational Database Design. Addison-Wesley, 1989.
Kroenke, David. Database Processing, 2nd ed. Science Research Associates, 1983.
Martin, James. Information Engineering. Prentice-Hall, 1989.
Reingruber, Michael C. and William W. Gregory. The Data Modeling Handbook: A Best-Practice Approach to Building Quality Data Models. John Wiley & Sons, Inc., 1994.
Simsion, Graeme. Data Modeling Essentials: Analysis, Design, and Innovation. International Thompson Computer Press, 1994.
Teory, Toby J. Database Modeling & Design: The Basic Principles, 2nd ed.. Morgan Kaufmann Publishers, Inc., 1994.
|
