|
Caché Technology Guide
SOURCE : http://www.e-dbms.com/cache/techguide/index.html
Introduction
The computing world has entered the “post-relational” era. Today’s transaction processing applications have requirements that overreach the capabilities of relational technology – they must span large networks, service thousands of clients, but still provide superb performance, Web compatibility, and simple operations at low cost. Increasingly, companies are running into the performance limits imposed by their relational databases. As they try to scale up transaction processing applications, complexity multiplies, performance degrades, and costs skyrocket. Additionally, even the newest “object-relational” databases, which impose an object veneer on top of a relational data engine, can’t efficiently use the rich and complex data structures required by state-of-the-art applications.
Furthermore, applications are getting more complex, as are the technologies they use – slowing down the development process and reducing reliability. More than ever before, there’s a need for rapid application development.
Caché, the high-performance database for the post-relational era, is a new generation of database technology that addresses these needs by combining a multidimensional data server with a versatile application server. Featuring advanced object technology, rapid Web development, enhanced SQL, and unique data caching technology, Caché provides levels of performance and scalability unattainable by relational technology.
In addition, the Caché Application Server’s ability to easily integrate access to a variety of technologies, its multidimensional data model for storing rich data, and its advanced object programming capabilities make it possible to develop sophisticated database applications rapidly, boosting programmer productivity and reducing time-to-market.
Caché supports all of the traditional ways of building Web applications plus a unique technology – Caché Server Pages, or CSP – that is optimized for rapid development of sophisticated, database-oriented systems. CSP features an advanced object architecture, dynamic server pages technology, and connectivity with leading Web development tools.
This Technology Guide provides an overview of Caché’s Multidimensional Data Server and Application Server. It explains how Caché fits into the basic application development process, enabling professional developers to move beyond the limitations of legacy relational technology to produce sophisticated, high-performance transaction processing applications for the Web and other network-centric environments.
The Caché Technology Guide has been divided into four main sections:
Chapter 1: Data Modeling: Relational or Object Access
This section discusses the pros and cons of relational technology and the value of object access to the database.
Chapter 2: The Caché Multidimensional Data Server
This section describes the Caché database, and the major features associated with database operations.
Chapter 3: The Caché Application Server
This section describes the language support and connectivity features of Caché.
Chapter 4: Caché Server Pages
This section describes the Web development and execution features of Caché.
Chapter 1: Data Modeling: Relational or Object Access
Early in the process of designing a new application, developers must decide upon their approach towards data modeling. For most, this comes down to a choice between the traditional modeling of data as relational tables and the newer approach of modeling as objects. Faced with the need to handle complex data, many developers believe that modeling with objects is a more effective approach.
Caché supports both SQL and object data access, and at times each is appropriate. To understand the uses of each and why data modeling with objects is generally preferred by modern-day developers, it is useful to understand how and why each has developed.
Relational Technology
In the early days of computing, information processing was done on huge mainframe systems and data access was, for the most part, limited to IT professionals. Databases tended to be home-grown, and retrieving or updating data effectively required a thorough knowledge of the database and how it was organized. If a user wanted a special report, he or she usually had to ask an overworked central staff to write it, and it usually wasn’t available in time to influence decisions.
With the coming of PCs, the world entered a “user-centric” era of computing. Relational database technology grew to serve the needs of people who wanted retrieval access to centralized corporate data from their desktops – they wanted to produce their own reports and ad-hoc queries of the database.
Relational technology introduced the query language SQL, which allows a consistent language to be used to ask questions of a wide variety of data. SQL works by viewing all data in a very simple and standardized format – a two-dimensional table with rows and columns. SQL became the underlying basis for a whole generation of tools that allow users to ask questions and get reports.
While this simple data model allowed the construction of an elegant query language with which to ask questions, it came with a severe price. The inherent complexity of data relationships doesn’t fit naturally into simple rows and columns, so data is often fragmented into multiple tables that must be “joined” in order to complete even simple tasks. This results in two problems: a) queries can become very difficult to write due to the need to “join” many tables, and b) the processing overhead required when relational databases have to deal with complex data can be enormous.
SQL has become a standard for database interoperability and reporting tools. However, it is important to understand that while SQL grew out of relational databases, it need not be constrained by them. Caché supports SQL as a query language using a much stronger multidimensional database technology.
Object Technology and Object Databases
Object programming and object databases are a practical result of work involving a need to model complex activities of the brain. It was observed that the brain is able to store very complex and different types of data and yet still manipulate such seemingly different information in common ways. Also, very complex behavior needed to be implemented in programs while hiding that complexity. Clearly both of these characteristics are increasingly true of today’s newer applications.
Object versus Relational Access
In object technology, the complexity of the data is contained within the object, and the data is accessed by a simple consistent interface. In contrast, relational technology also provides a simple consistent interface, but it stores the data as simply as possible and the user or programmer is then responsible for constantly dealing with the complexity of the data.
Because objects can model complex data simply, object programming works best for programming complex applications. Similarly, object access of the database works best for inserting and updating the database (i.e., for transaction processing).
Caché complements object access with an object-extended SQL query language. SQL is a powerful language for searching a database and is widely used by reporting tools. However, we believe SQL is best suited for that purpose – queries and reports – rather than for transaction processing (for which it is cumbersome and often inefficient).
Overview of the Object Data Model and Object Programming
The Caché object model is based upon the ODMG (Object Database Management Group) Standard and supports many advanced features, including multiple inheritance.
Object technology attempts to mirror the way that humans actually think about and use information. Theoretically, entities are viewed as objects that have state (as represented by its current data values) and behavior (as can be observed and influenced through its code). An example would be an Invoice object that has data such as an invoice number and a total amount and code such as Print().
Unlike relational tables, objects bundle together both data and code. Conceptually, and sometimes in practice, an object is a package that includes that object’s data values (“properties”) and a copy of all of its code (“methods”). An object’s methods send messages to communicate with other methods of that and other objects. To reduce storage, it is common for objects of the same class to share the same copy of code (e.g., it would be unrealistic for each Invoice object to have its own private copy of code). Also, in Caché, method calls typically result in function calls rather than enduring the overhead of passing messages. However, these implementation techniques are hidden from the programmer; it is always accurate to think in terms of objects passing messages.
What is the difference between an object and a class? A class is the definitional structure and code provided by the programmer. It includes both a description of the nature of data and how it is stored as well as all of the code, but it does not contain any data. An object is a real entity that is a particular “instance” of a class. For example, invoice #123456 is an object of the Invoice class.
Object technology also promotes a natural view of data by not restricting properties to simple, computer-centric data types. Objects may contain other objects, or references to other objects, which makes it easy to build useful and meaningful data models. Here’s a simple example of a Customer object:
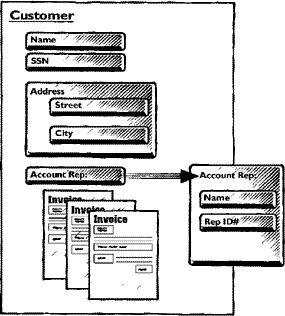
Customer Object:
Name Data can be of a simple, system-defined type such as a string,
integer, etc.
SSN Data can be a programmer-defined, advanced data type (ADT).
For example, SSN can be defined as a nine-digit number that
matches the pattern: NNN-NN-NNNN. ADTs are themselves a
kind of object.
Address: Objects can be embedded within objects. In this example,
Street "Address" is an object that contains the properties "Street"
City and "City."
AccountRep: "Account Rep" is a fairly complex object that exists
independently from "Customer." In this example, "Customer" includes
a reference to the appropriate "Account Rep."
Invoice: References can be made to more than one occurrence of an object,
thus creating a collection.
Relationships can also be used to connect objects; e.g., instead of Invoices being an embedded collection in Customer the invoices can be stored independently and there would be a one-to-many relationship between Customer and Invoices. References are lighter-weight than relationships; relationships are bi-directional, support referential integrity, and require more processing time.
Key Object Concepts
Inheritance is the ability to derive one class of objects from another. The new class (a subclass) contains all of the properties and methods of its superclass, as well as additional properties and methods unique to it. Objects of the subclass should have an “is a” relationship to its superclass. For example, a dog “is a” mammal, so it makes sense for the Dog class to inherit all the properties and methods of the Mammal class. The subclass may have additional properties and methods (e.g., Dog may have a property called DogTagNumber that is not present in the Mammal class). A subclass may also override an inherited definition (e.g., the Print() method for a subclass of the Invoice class may be different from the Print() method of Invoice).
Multiple inheritance means a subclass can be derived from more than one superclass. A dog “is a” mammal, and “is a” pet, so the object class “Dog” can inherit the attributes of both the “Mammal” class and the “Pet” class.
Encapsulation means that, as far as the application is concerned, objects can be viewed as a sort of “black box”. No matter how complex, an object class has a finite number of public properties and methods. Once defined, the application doesn’t need to know the internal workings of an object. It deals only with the properties and methods. Public properties and methods can be accessed by any method, whereas Private properties and methods can only be accessed by methods of the same class.
Polymorphism refers to the fact that methods used in multiple classes can share a common interface, even if the underlying implementation is different. For example, say an application uses several different object classes: Letter, Mailing Label, and ID Badge, all of which contain a method called PrintAddress. The application doesn’t need to contain special instructions about formatting an address for each kind of object. It merely calls the object’s PrintAddress method. Polymorphism ensures that each object carries out the instruction in a manner appropriate for the class to which that object belongs.
Why Choose Objects for Your Data Model?
For new database applications, most developers choose to use object technology because they can develop complex applications more rapidly and more easily modify them later. Object technology provides many benefits:
Objects support a richer data structure that more naturally describes real world data.
Programming is simpler; it is easier to keep track of what you are doing and what you are manipulating.
Customized versions of classes can easily replace standard ones, making it easier to customize an application and support it through new releases. This feature is particularly important for VARs who must support a variety of customized versions.
The black box approach of encapsulation means programmers can improve the internal workings of objects without affecting the rest of the application.
Objects provide a simple way to connect different technologies and different applications.
Object technology is a natural match with Java, allowing easier Web development, and with GUI based user interfaces.
Many new tools assume object technology.
Objects provide a good insulation between the user interface and the rest of the application. Thus when it becomes necessary to adopt a new user interface technology (perhaps Web or some currently unforeseen future technology) you can reuse most of your code.
Object Data Storage…
Unfortunately, although many applications are now being written with object programming languages, they often try to cram object data into flat relational tables. This significantly impairs the advantages of object technology.
Caché provides a multidimensional data structure that naturally stores rich object data. The result is faster data access and faster programming.
…Plus Relational Access
Of course many tools (such as report writers) use SQL, not object techniques, for accessing data, and some developers may want to use some of those tools.
A unique feature of Caché is that whenever a database object class is defined, Caché automatically provides full SQL access to that data. Thus, with no additional work, SQL-based tools will immediately work with Caché data, and even they will experience the high performance advantage of the Cache' Multidimensional Data Server.
The reverse is also true. When a DDL description of a relational database is imported, Caché will automatically generate an integrated relational/object description of the data, enabling immediate access as objects as well as through SQL.
The Caché Unified Data Architecture keeps these access paths synchronized; there is only one data description to edit.
Chapter 2: The Caché Multidimensional Data Server
Multidimensional Data Model
Rich Multidimensional Data Structure
Caché’s high-performance database uses a multidimensional data model that allows efficient and compact storage of data in a rich data structure. With Caché, it is possible to access or update data without performing the complicated and time consuming joins required by relational databases.
Although sometimes described as a “hyper-cube” or “n-dimensional space,” a more accurate description of Caché’s storage model is a collection of sparse multidimensional arrays called “globals”. Data can be stored in a global with any number of subscripts. What’s more, subscripts are typeless and hence can be anything – string, integer, floating point, etc. This means one subscript might be an integer, such as 34, while another could be a meaningful name, like “LineItems”– even at the same subscript level.
For example, a stock inventory application that provides information about item, size, color, and pattern might have a structure like this:
^Stock(item,size,color,pattern) = quantity
Here’s some sample data:
^Stock(“slip dress”,4,”blue”,”floral”)=3
With this structure it is very easy to determine if there are any size 4 blue slip dresses with a floral pattern – simply by accessing that data node. If a customer wants a size 4 slip dress and is uncertain about color and pattern, it is easy to display a list of all of those by cycling through all of the data nodes below ^Stock(“slip dress”,4).
In this example all of the data nodes were of a similar nature (they stored a quantity), and they were all stored at the same subscript level (4 subscripts) with similar subscripts (the 3rd subscript was always text representing a color). However, they don’t have to be. Not all data nodes have to have the same number or type of subscripts, and they may contain different types of data.
Here’s an example of a more complex global with invoice data that has different types of data stored at different subscript levels:
^Invoice(invoice #,”Customer”) = Customer information^Invoice(invoice #,”Date”) = Invoice date
^Invoice(invoice #,”Items”) = # of Items in the invoice^Invoice(invoice #,”Items”,1,”Part”) = part number of 1st Item
^Invoice(invoice #,”Items”,1,”Quantity”) = quantity of 1st Item^Invoice(invoice #,”Items”,1,”Price”) = price of 1st Item
^Invoice(invoice #,”Items”,2,”Part”) = part number of 2nd Item
etc.
Multiple Data Elements per Node
Often only a single data element is stored in a data node, such as a date or quantity, but sometimes it is useful to store multiple data elements together as a single data node. This is particularly useful when there is a set of related data that is often accessed together. It can also improve performance by requiring fewer accesses of the database, especially when networks are involved.
For example, in the above invoice each item included a part number, quantity, and price all stored as separate nodes, but they could be stored in a single node:
^Invoice(invoice #,”LineItems”,item #)
To make this simple, Caché supports a function called $list() which can assemble multiple data elements into a length delimited byte string and later de-assemble them, preserving datatype.
Transaction Processing with a Large Number of Users
Efficient access to data makes the multidimensional model a natural for transaction processing. Caché processes do not have to spend time joining multiple tables, so they run faster.
Logical Locking Promotes High Concurrency
In systems with thousands of users, reducing conflicts between competing processes is critical to providing high performance. One of the biggest conflicts is between transactions wishing to access the same data.
Caché processes don’t lock entire pages of data while performing updates. Because transactions require frequent access or changes to small quantities of data, database locking in Caché is done at a logical level. Database conflicts are further reduced by using atomic addition and subtraction operations, which don’t require locking. (These operations are particularly useful in incrementing counters used to allocate id numbers and for modifying statistics counters, both of which are common “hot spots” in a database that would otherwise cause frequent conflicts between competing transactions.)
With Caché, individual transactions run faster, and more transactions can run concurrently.
Multidimensional Model Enables Realistic Description of Data
The multidimensional model is also a natural fit for describing and storing complex data. Developers can create data structures that accurately represent real-world data, thus making it faster to develop applications and easier to maintain them.
Variable Length Data in Sparse Arrays
Because Caché data is inherently variable length and is stored in sparse arrays, Caché often requires less than ½ of the space needed by a relational database. In addition to reducing disk requirements, compact data storage enhances performance because more data can be read or written with a single I/O operation, and data can be cached more efficiently.
Declarations and Definitions Aren’t Required
No declarations, definitions, or allocations of storage are required to directly access or store data in the database, and there is no need to specify the number or type of subscripts or the type or size of data. The multidimensional arrays are inherently typeless, both in their data and subscripts. Global data simply pops into existence as data is inserted with the SET command.
However, to make use of the object access and SQL access of the database, data dictionary information is required. In specifying the data dictionary for objects and SQL, developers have a choice of letting wizards automatically select the multidimensional data structure best suited to their data, or they can directly specify the mapping.
Namespaces
In Caché, data and Caché ObjectScript code are stored in disk files with the name CACHE.DAT (only one per directory). Each such file contains numerous “globals” (multidimensional arrays). Within a file, each global name must be unique, but different files may contain the same global name. These files may be loosely thought of as databases.
Rather than specifying which CACHE.DAT file to use, each Caché process uses a “namespace” to access data. A namespace is a logical map that maps the names of multidimensional global arrays and routine code to CACHE.DAT files, including the Data Server and directory name for that file. If a file is moved from one disk drive or computer to another, the namespace map is changed.
Usually a namespace specifies sharing of certain system information with other namespaces, and the rest of the namespace’s data is in a single CACHE.DAT used only by that namespace. However, this is a flexible structure that allows arbitrary mapping, and it is not unusual for a namespace to map the contents of several CACHE.DAT files.
The Caché Advantage
Performance
By using an efficient multidimensional data model with sparse storage techniques instead of a cumbersome maze of two-dimensional tables, data access and updates are accomplished with less disk I/O. Reduced I/O means that applications will run faster.
Scalability
The transactional multidimensional data model allows Caché-based applications to be scaled to many thousands of clients without sacrificing high performance. That’s because data access in a multidimensional model is not significantly affected by the size or complexity of the database in comparison to relational models. Transactions can access the data they need without performing complicated joins or bouncing from table to table.
Caché’s use of logical locking for updates instead of locking physical pages is another important contributor to concurrency, as is its sophisticated data caching across networks.
“We did some analysis of what it would take to model physician order entry in the relational database. It pointed to more than 700 tables.”
— Steve Flammini
Director of Application Development
Partners HealthCare System Inc.
Rapid Development
With Caché, development occurs much faster because the data structure provides natural, easily understood storage of complex data and doesn’t require extensive or complicated declarations and definitions. Direct access to globals is very simple, allowing the same language syntax as accessing arrays.
Cost-Effectiveness
Compared to comparably-sized relational applications, Caché-based applications require significantly less hardware and no database administrators. System management and operations are simple.
Integrated Database Access
Multiple Ways to Access Data
Caché gives programmers the freedom to store and access data through objects, SQL, or direct access of multidimensional structures. Regardless of the access method, all data in Caché’s database is stored in Caché’s multidimensional arrays.
Once the data is stored, all three access methods can be simultaneously used on the same data with full concurrency.
Unified Data Architecture
A unique feature of Caché is its Unified Data Architecture. Whenever a database object class is defined, Caché automatically generates an SQL-ready relational description of that data. Similarly, if a DDL description of a relational database is imported into the Data Dictionary, Caché will automatically generate both a relational and an object description of the data, enabling immediate access as objects. Caché keeps these descriptions coordinated; there is only one data definition to edit.
Object Access
Some developers like to think of data as objects. Objects bundle data (“properties”) and code (“methods”), allow the embedding of objects within other objects, and support collections (a property can contain multiple values or multiple embedded objects). Object programming has become the predominant paradigm for the development of new applications.
Caché’s object model is based upon the ODMG standard. Caché supports a full array of object programming concepts, including encapsulation, embedded objects, multiple inheritance, polymorphism, and collections.
SQL Access
Some developers like to think of data as relational tables, which organize data into rows and columns and don’t contain any code. Only the basic Select, Insert, Update, and Delete operations are provided with a relational database.
SQL access is important because so many existing applications and tools use SQL as their query language. Because Caché data is actually stored in efficient, multidimensional structures, applications that use SQL achieve better performance with Caché than when they run against traditional relational databases.
Caché SQL is the query language for Caché. It is an object enhanced implementation of SQL, and it supports ODBC and JDBC. Queries can also be embedded in Caché ObjectScript routines, and thus within the methods of Caché Objects.
Direct Global Access Mode
In addition to using objects or SQL, there are times when it makes more sense to directly use “global references” to set and retrieve data from the Caché multidimensional arrays. This can be accomplished by using the same syntax as would be used to set, retrieve, or search process private arrays.
Direct global access is commonly used when there are unusual or very specialized structure requirements and no need to provide object or SQL access to them, or where the highest possible performance is required.
The Caché Advantage
Flexibility
Caché’s data access modes – Object, SQL, and Direct – can be used concurrently on the same data. This flexibility enables programmers to develop applications that fit their end user’s needs. It also gives programmers the freedom to think about data in the way that makes most sense to them.
Faster SQL Response
Relational applications can enjoy significantly enhanced performance by using Caché SQL to tap into Caché’s efficient post-relational database.
“We estimate that on the same hardware as the Sybase system, Caché is 100 times faster handling transactions, and 20 times faster than Sybase overall.”
— Rolf Streb
IT Manager
Department of Justice
Bern, Switzerland
Rapid Application Development
Object technology is a powerful tool for increasing programmer productivity. Developers can think about and use objects – even extremely complex objects – in simple and realistic ways, thus speeding the application development process. Also, the innate modularity and interoperability of objects simplifies application maintenance, and lets programmers leverage their work over many projects.
Caché is fully object-enabled, providing all the power of object technology to developers of high-performance transaction processing applications.
"Caché offers …object orientation along with SQL access and interoperation with other databases. Sort of the best of all possible worlds. And Caché is fast."
— John Gantz
in ComputerWorld
May 10th, 1999
Object Database Storage
As mentioned earlier, Caché’s Multidimensional Data Server stores all data in the form of multidimensional data structures. Because of their multidimensional nature, these structures are well suited for storing complex data.
Storage Definitions and Storage Classes
In Caché Objects, the way data is stored and accessed through objects is controlled by a “Storage Definition” that uses a “Storage Class”. A Storage Definition contains a description of the database structure for that class and specifies a Storage Class. A Storage Class contains code that generates the Load, Save, and Delete methods for a class of objects based upon the Storage Definition of that class.
The use of Storage Classes and Storage Definitions to control storage structures and how data is saved is very powerful, but if the programmer doesn’t want to bother controlling these storage structures and filing mechanisms then Caché will generate all of this automatically.
Three Storage Classes are provided with Caché.
The most common and highest performance option is CachéStorage. Developers define their data or import a data description and, during compilation, Caché will automatically generate the required multidimensional data structures and database access methods. The storage structure can either be completely generated by the compiler, or the programmer can, within certain limits, lay out the data structure.
Developers can also create class-specific CustomStorage access methods. In this case there is no storage map. This technique is particularly useful for accessing highly specialized data structures or for storage other than disk storage, but SQL cannot then be used on that class.
A third option is CachéSQLStorage. In this case, Caché automatically generates the database access methods with embedded SQL code. This is not the most efficient way to implement persistence, but it allows an application to store data in a relational database.
If these three are not sufficient, a programmer can also implement his or her own Storage Class.
Not all classes have to use the same Storage Class. Most classes probably use CachéStorage, but some may be CustomStorage or CachéSQLStorage. The specification of a Storage Class is on a class-by-class basis.
Caché’s storage is even flexible enough to allow subclasses to use different Storage Classes. For example, a Customer class may be an abstract class with a subclass using CachéStorage and another subclass using CachéSQLStorage. This would permit accessing some customers from a relational database and others from a Caché database without the programmer worrying about where the customer is stored. However, in general such subclass divisions aren’t advisable because it makes SQL queries difficult.
Logical Names for Storage Classes Make it Easier to Support Multiple Sites
A given class may even have more than one Storage Definition, and there are several reasons why one may wish to recompile a class using a different Storage Definition. A VAR may have several customers, each with a slightly different storage structure, so having multiple Storage Definitions for the Invoice class using CachéStorage may be needed.
Also, while CachéStorage gives the highest performance, it may be important to be able to recompile the application to run on another (relational) database.
To make it easier to recompile an application for different sites, Caché supports logical names for Storage Definitions. By simply changing a few logical name values and recompiling, an entire application can be recompiled to use a different combination of storage structures and Storage Classes.
Accessing Relational Databases with Caché Relational Gateway
The Caché Relational Gateway enables an SQL request that originates in Caché to be sent to other databases for processing. Using the gateway, a Caché application can retrieve and update data stored in legacy relational databases.
Additionally, if Caché data structures are compiled using CachéSQLStorage, the gateway allows Caché applications to use relational databases. The ability to run Caché applications against legacy relational databases provides additional deployment flexibility. However, applications will run faster and be more scalable if they access Caché’s post-relational database.
The Caché Advantage
Growth Potential
Caché’s Unified Data Architecture automatically describes data as both objects and tables allowing seamless integration of relational and object technologies. This allows relational programmers to leverage their existing skills and applications, and smoothly introduce object capabilities as products evolve.
Compatibility With Existing Tools
By virtue of the Unified Data Architecture, all Caché data can be automatically accessed via SQL. Caché SQL access provides interoperability with conventional relational applications, including many popular data analysis and reporting tools.
Deployment Flexibility and Database Independence
The Caché Relational Gateway allows Caché applications to run against conventional relational databases, providing deployment options for customers with large in situ relational systems, and for whom performance is not a key issue.
Simple System Management / 24-Hour Database Operation
Caché is designed to run 24 hours a day, every day of the year, on systems ranging from small 4-user systems to systems with tens of thousands of users. Many of the installations are by VARs, who often have a need to install large systems but can’t afford to provide on-going extensive system management support. These requirements place great demands on the needs for simplicity while supporting the operations of large sites.
In Caché there is never a need to perform operations such as periodically rebuilding indexes for performance or reloading a database when a new version is released, as is common with some relational systems. Such operations are neither simple nor conducive to 24-hour operation.
Caché includes a full complement of system management utilities, all of which can be accessed remotely, and major system management functions can be scripted for unattended operation.
Unattended Backup while the Database is being Updated
Caché supports full, incremental, and cumulative incremental back-ups. These backups can be performed while the database is up and running, including while database updates are occurring. These backups can be scripted so they are performed automatically without an operator.
Namespace Maps Provide Hardware and Database Reconfigurations Without Downtime
On each system, Caché maintains “Namespace Maps” that specify where data and code is stored. These can be specified in a Master Namespace Map that broadcasts the locations to all Caché Application and Data Servers.
Changes to the system, even major changes such as adding a database server or switching to a backup server so a data server can be serviced, can be accomplished by revising the Master Namespace Map. Scheduled reconfigurations can be done dynamically, without down time, in a manner completely transparent to applications.
By creating contingency Namespace Maps, system administrators can reconfigure the database to compensate for a variety of failure scenarios.
Fail-over Features for Enhanced Robustness in the Event of Hardware Failure
Caché supports many advanced fail-over features to ensure application robustness, including Shadow Servers and Database Clusters.
The use of Shadow Servers is particularly powerful. With shadowing, each data server has a backup server that constantly reads the journal of the main server and updates the backup server’s database. This backup server is useful for many purposes:
In the event that the main server fails, the backup server can be immediately used, although any open transactions will be rolled back.
The backup server can be used for reports and queries. It is not used for updates when the main server is working.
Database backups can be performed on the backup server, offloading the main server of that burden.
In the event that the connection between the servers is temporarily broken, the backup server catches up when the connection is restored.
Database Clusters support automatic fail-over features. In a Database Cluster, multiple computers access the same disk drives and use cluster management software to coordinate shared or exclusive access to disk blocks. If one computer fails, its processes are lost but the other computers continue to function. The failed computer’s users have their in-progress transactions rolled back, and those users may then sign onto another computer. Often load balancing is used in assigning users dynamically to clustered computers. Although Database Clusters provide operational flexibility and enhanced reliability, they usually require more system management than other systems, and they require special hardware.
ViewPoint for Performance Monitoring and Analysis
ViewPoint is a separately licensed suite of performance analysis tools that allows developers to automatically monitor, analyze, and report on a wide variety of Caché database and application performance factors in real or historical time. It uses a client/server architecture to offload overhead from a monitored host to a PC, thus conserving system resources for use by applications.
The Caché Advantage
Simplified Maintenance
With Caché, applications don’t require a lot of administration to remain up and running at lightning-fast speed. Rebuilding indexes and similar relational database operations aren’t performed in Caché, and many operations functions can be scripted for unattended operation.
Reliability and 24-Hour Operation
On-line backup, Shadow Servers, and Database Clusters support 24-hour operation and seamless recovery from failures. Clients and servers can be added, and networks reconfigured “on the fly” using Dynamic Namespace Mapping.
Demonstrable Performance
Beyond its obvious use as a diagnostic and performance optimization tool, ViewPoint also allows developers to track performance to make sure that performance commitments have been satisfied. These days, performance metrics are often part of application specifications. ViewPoint lets developers prove that their applications have performance meeting or exceeding those metrics.
|
