|
멀티미디어 데이터베이스 기술
한국과학기술원
양철웅, 양우석, 이윤준, 기명호
목 차
1. 서론
2. 멀티미디어 데이터베이스
3. 멀티미디어 데이터베이스의 질의 처리
4. 멀티미디어 데이터베이스의 트랜젝션 처리
5. 멀티미디어 자료의 색인 기법 및 군집화
6. 결론
1. 서 론
마이크로 프로세서와 같은 하드웨어의 급속한 발전에 따라 개인용 컴퓨터와 노트북, 워크스테이션 등 컴퓨터 전반에 걸쳐 급격한 성능향상이 이루어 졌으며, 몇몇 전문가들에 제한되어 사용 되어 왔던 컴퓨터 통신 등도 보편화되어 누구나 쉽게 쓸 수 있게 되었다. 90년대 초반부터 시작된 멀티미디어에 대한 사용자들의 관심과 시장의 활성화로 초기에는 개별 미디어인 오디오나 비디오의 단순 처리 위주에서 데스크탑 TV 수신, 영상회의, 주문형 비디오 서비스 등과 같은 멀티미디어의 통합처리 위주로 발전되고 있으며, 인터네트의 확산으로 사무실이나 연구실 등에서 이루어지던 전자메일, 정보검색과 같은 정보처리 활동들이 가정에서도 TV의 간편성과 인터네트가 가지는 정보의 검색, 제공성이 결합된 대화형 TV를 통해 다양한 형태의 멀티미디어 정보서비스 활동이 부분적으로 이루어지고 있다.
따라서 멀티미디어와 인터네트라는 용어는 이미 모든 컴퓨터에 있어서 필수적이며, 기본적인 기능으로 인식되고 있으며, 초고속 정보통신망이 구축되는 2000년대에는 초고속 통신망과 결합된 고도의 멀티미디어 정보처리 기술을 통하여 사용자들은 다양한 정보요구에 대한 창의적인 정보서비스를 제공받게 될 것이다.
최근에는 이러한 기술변화의 추세에 따라 멀티미디어와 네트워크 멀티미디어 컴퓨팅 분야에 대한 연구가 활발히 시자되고 있으며, 앞으로의 멀티미디어 시스템들은 네트워크 기반 멀티미디어 처리를 위한 하드웨어, 소프트웨어, 그리고 이에 따른 다양한 응용프로그램들이 개발되리라 전망된다.
따라서 컴퓨터와 네트워크의 기술발전 추세에 비추어 다음과 같은 의문을 먼저 제기할 수 있을 것이다.
첫째, 하드웨어의 급속한 기술발전에 따른 소형화된 컴퓨터는 어떠한 모습으로 어떠한 기능을 제공할 수 있을 것인가?
둘째, 네트워크의 속도와 대역폭이 컴퓨터의 시스팀 버스보다 더 빠른 경우, 컴퓨터는 어떠한 구조를 가질 것인가?
본 고에서는 위의 두가지 의문에 대한 컴퓨터 모습을 네트워크 멀티미디어 컴퓨팅이라는 개념과 이를 위한 하드웨어, 소프트웨어, 네트워크기반 시스팀 구조 등에 대한 내용을 소개함으로써, 초고속 정보통신망에서의 멀티미디어 정보처리를 위한 시스팀 구조를 제시하며, 멀티미디어 관련 핵심분야와 요소기술에 대한 내용을 다룬다.
먼저, 2장에서는 최근에 소개되고 있는 네트워크 컴퓨터 개념에 대한 구체적인 사양과 특성을 분석하여, 이러한 개념을 구현시키기 위한 핵심 기술과 멀티미디어 정보처리를 위한 네트워크 컴퓨터의 요구사항 등에 대하여 살펴본다. 3장에서는 네트워크 멀티미디어 컴퓨팅에 대한 연구 활동 내용을 중심으로 관련 기술동향을 살표보며, 4장에서는 한국전자통신연구소에서 진행중에 있는 지능형 멀티미디어 워크스테이션 기술개발 사업인 콤비스테이션의 주요특성과 구조를 다루며, 5장인 결론에서는 향후 네트워크 멀티미디어 컴퓨팅 기술 분야의 발전전망, 향후 연구방향에 대한 내용을 기술한다.
2. 멀티미디어 데이터베이스
2.1 멀티미디어 데이터베이스
현재 멀티미디어 데이터베이스란 용어가 일반화되고 있는 추세이다. 그러나 이 용어에 대한 명확한 정의는 내려져 있지 않다. 읽기 전용의 대용량 CD-Rom을 멀티미디어 데이터베이스라 하는 사용자도 있고, 대용량 자료(BLOB) 입출력 및 검색 기능을 가진 관계형/객체지향형 데이터베이스를 멀티미디어 데이터베이스라고 지칭하기도 한다. 하지만 실질적으로 다음과 같은 요건을 만족하는 시스템을 멀티미디어 데이터베이스 시스템이라 말할 수 있을 것이다.
* 멀티미디어 자료형의 지원
* 대용량 멀티미디어 자료처리 기능
* 멀티미디어 자료를 위한 저장 시스템
* 멀티미디어 자료 관리시의 무결성 보장
* 멀티미디어 정보 검색 기능
2.2 관계형 데이터베이스에서의 멀티미디어 자료처리
데이터베이스에 멀티미디어 자료 처리의 기능을 지원하는 연구는 현재 널리 사용되고 있는 관계형 데이터베이스 분야에서부터 시작되었다. 관계형 데이터베이스는 기본적으로 여러 속성으로서 가진 튜플들이 모여 테이블 형태를 이루고 있다. 이때 각각의 속성으로서 기존에는 문자 자료형과 이들 자료형은 정해진 크기를 지니고 있어 가변적인 길이를 가지는 멀티미디어자료로의 적용이 부적합하다. 따라서 멀티미디어 자료의 지원을 위하여 가변적인 크기의 속성을 지원하게 되었다.
관계형 테이타베이스에 있어서 가변적인 크기의 속성을 지원하는 방법은 크게 두 가지가 있을수 있는데, 첫 번째는 속성의 최대 크기를 명시하고 그 안에서 가변적인 크기를 가질수 있도록 하는 방법이며 두 번째는 대용량 자료(BLOB) 의 포인터를 속성으로 가지게 하는 방법이다.
가변적 크기를 가지는 속성을 선언하기 위하여 관계형 데이타베이스 언어 표준인 SQL92에서는 문자 데이터를 위하여 CHARACTER자료형 선언을 지원하나, 가변적인 문자 데이터를 위하여CHARACTER VARYING(N) 형태의 자료형 선언을 지원한다. SQL92에서는 문자 자료형 이외에 범용 이진 자료의 저장을 위하여 BIT자료형과 그의 가변적 형태인 BIT VARYING(N) 자료형 선언을 지원하고 있다.
가변적 크기의속성을 사용하는 방법은 최대 크기를 미리 제한해 놓아야 한다는 단점이 있기 때문에 실제 멀티미디어 자료를 저장하기 위해서는 대용량 자료 방법을 사용한다. 대용량 자료 저장의 경우 보통 실제 자료는 데이터베이스 테이블과 다른 위치에 저장이 되며 그의 포인터만을 관리하게 된다. 대용량 자료의 경우 한 번의 데이터베이스 작업에 의해 읽어올수 없는 경우가 대부분이므로 제이타베이스 시스템은 대용량 자료의 일부분을 읽거나 특정 부분으로 검색 위치를 이동하는 등의 기능 제공이 필요하다.
2.3 객체지향 데이터베이스에서의 멀티미디어 자료처리
정보를 객체화하여 관리하는 객체지향 데이터베이스는 많은 종류의 멀티미디어 자료 처리에 있어서 관계형 데이터베이스의 경우보다 많은 장점을 가지고 있다. 1980년도 중반부터 상용 시스템이 나타나기 시작한 객체지향 데이터베이스에서의 멀티미디어 자료처리에 대하여 살펴보자.
멀티미디어 처리에 있어서 관계형 데이터베이스에 비하여 객체지향 데이터베이스가 가지는 장점은 다음과 같다.
* 복잡한 객체를 쉽게 모델링할 수 있다.
*호스트 언어(host language)와의 결합이 용이하다.
* 새로운 자료형 및 연산을 쉽게 정의할 수 있으며 확장할 수 있다.
* 동시성 제어(concurrency control)가 효율적이다.
현재 객체지향 데이터베이스 언어를 위한 표준으로서 SQL3의 초안(draft)이 제안되어 있는 상태이며, 곧 표준으로 제정된 전망이다. SQL3은 SQL92에 비하여 객체지향 모델 및 멀티미디어 자료형 지원, 4GL 수준의 프로그래밍 기능 지원 등을 골자로 하고 있다. SQL3에 제시되어 있는 CREATE TYPE명령어를 사용하면 사용자 정의 멀티미디어 자료형의 지원이 가능하게 된다.
추후 표준으로 제정된다면 SQL3은 멀티미디어 데이터베이스의 표준언어로서 자리잡게 될 것이 기대된다.
현재 발표되어 있는 많은 상용 객체지향 데이터베이스들은 제각기 고유한 방식으로 멀티미디어 자료를 지원하고 있다. UniSQL에서는 Generalized Large Object(GLO)라는 클래스를 기반으로
Large Lbject(GLO)라는 클래스를 기반으로 Large Object(LO)와 File Based Object(FBO)라는 자료형을 멀티미디어 처리를 위하여 지원하고 있다. Illustra에서는 외부화일, 거대 객체, 거대문서 자료형을 멀티미디어 처리를 위하여 제공한다.
2.4 멀티미디어 데이터베이스의 고급 기능
멀티미디어 데이터베이스가 기존의 데이터베이스에 단순히 멀티미디어 자료형에 관한 부분만을 첨가한 것이 아닌, 멀티미디어 정보의 특징을 잘 살릴 수 있는 시스템으로 되기 위해서는 다음과 같은 요건들이 만족되는 것이 바람직하다.
* 대화형 자료 입출력
* 효율적인 멀티미디어 질의처리
* 멀티미디어 특성에 맞는 연산 지원
* 확장성
* 대용량 자료의 효율적 처리
* 멀티미디어 응용 프로그램 개발 도구 및 개발 환경
3. 멀티미디어 데이터베이스의 질의처리
3.1 멀티미디어 자료의 질의 처리
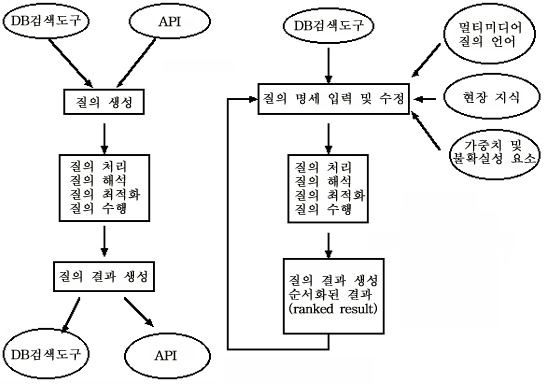
<그림 1> 기존의 데이터베이스와 멀티미디어 데이터베이스에서의 질의 처리과정
멀티미디어 데이터베이스에 저장되어 있는 자료에 대한 질의 처리 메카니즘은 멀티미디어
정보의 특성에 의해 기존의 방법과 달라지게 된다. 그림 1은 기존의 데이터베이스와 멀티미디어 데이터베이스에서의 질의 처리 과정을 나타낸다. 그림 1의 (가)에서 기존의 데이터베이스의 경우에는 데이터베이스 질의 언어나 API를 통해 사용자로부터 질의를 입력받는다. 입력된 질의는 해석되고 신속한 처리를 위하여 최적화되어 파스 트리(Parse tree)를 생성해낸다. 질의 최적화기 (query optimizer)는 파스트리를 생성할 경우 색인 정보를 참조하며, 관계형 데이터베이스의 경우 에 질의는 수행된 후에 사용자에게 결과가 전달되게 된다.
멀티미디어 데이터베이스의 경우의 질의는 관계형 데이터베이스의 경우처럼 질의를 명시하기 어려울 때가 있다. 또한 검색된 결과가 사용자가 원하던 의도와 명확하게 부합될 가능성도 적다.
따라서 멀티미디어 데이터베이스에서는 그림 1의 (나)처럼 반복적으로 질의를 처리하는 구조가 요구된다. 검색을 원하는 멀티미디어 요소의 명확한 기술을 위하여 질의 생성시에 사용자로부터 여러 가지 입력을 받는 과정이 추가된다.
3.2 멀티미디어 질의 종류
멀티미디어 응용 시스템에서 정보 검색이 필요한 경우 가장 빈번한 질의 형태가 무엇인지를
파악하여 그에 맞추어 시스템을 최적화하는 작업이 필요하다. 멀티미디어 질의는 다음과 같이 그 검색 방법에 따라서 세 가지로 분류할 수가 있다.
* 속성 질의
멀티미디어 정보를 기술하는 여러 소성 값을 주고 그에 해당하는 정보를 검색한다. 이 경우 속성은 수치나 문자 등 시스템에서 기본적으로 제공하는 자료형이다.
* 내용 기반 질의(content-based query)
멀티미디어 정보를 기술하는 여러 특징을 주고 그에 부합하는 멀티미디어 요소를 검색한다. 이 질의가 가장 널리 사용되고 있는 것은 문서 검색 시스템이며 점차 영상 및 음성 분야쪽으로 확장되고 있다.
* 구조 질의(structure query)
복잡한 형태를 지니고 있는 멀티미디어 정보에 대해 구조에 대한 조건을 주고 이것에 일치하는 정보를 검색한다. 예를 든다면 " 뉴스 비디오 중에서 다른 뉴스에 참조된 영상이 두 개이상 있는 것을 검색하라" 라는 질의가 있을 수 있다. CAD나 구조화된 영상 자료들에 대하여 이 형태의 질의가 행해질 수 있다.
3.3 문서 자료 검색
문서 자료 검색은 일반적으로 사용자가 찾고자하는 문서의 내용에 적합한 문서들의 객과적 특성에 대한 정보를 얻기 위하여 수행된다. 예를들어 "멀티미디어 또는 객체지향 데이터베이스에서의 질의 처리에 대하여 1995년 이후에 발표된 논문들의 저자, 출판사, 제목은 무엇인가?" 와 같은 질의이다. 이러한 사용자의 질의를 처리하기 위하여 데이터베이스에 저장되는 문서 자료는 일반적으로 문서의 내용을 표현하는 색인어의 집합으로 표현된다.
문서의 내용을 표현하기 위하여 사용되는 색인 어휘는 응용 분야에 따라 제한된 어휘가 사용되거나 일반 사용자들이 사용하는 모든 어휘가 색인 어휘로 사용될 수 있다. 제한된 색인어휘를 사용할 경우에는 단어들 간의 관계, 즉 동의어, 반대어, 상위 개념어, 하위 개념어 등을 이용하여 보다 정확한 문서의 표현과 검색이 가능하다. 그러나 각 응용 분야에서 나타나는 모든주제를 표현할 수 있는 완전한 어휘를 인위적으로 작성하기는 매우 어렵기 때문에 일반적으로 데이터베이스에 있는 문서들에서 나타나는 모든 단어가 색인 어휘로 사용된다. 단 데이터베이스에 있는 거의 모든 문서들에서 나타나는 단어들은 색인 어휘에서 제외된다. 문서의 내용을 표현하는 색인어는 문서의 내용을 표현하는 정도에 따라 가중치가 부여될 수 있다.
색인어의 집합으로 표현된 문서들에 대한 질의 방법은 벡터 질의와 불리안 질의로 구분된다. 위에 언급된 질의에 나타나는 문서의 내용에 대한 벡터 질의는 "멀티미디어, 객체지향, 데이터베이스, 질의처리"와 같이 표현되며, 불리안 질의는 "((멀티미디어 OR 객체지향) AND 데이터베이스 AND 질의 처리)"로 표현된다. 질의에 대한 문서의 적합도는 벡터 질의의 경우 문서와 질의에 동시에 나타나는 색인어들의 가중치 합이며, 불리안 질의는 퍼지 집합 연산의 결과이다.
3.5 동영상 자료 검색
디지탈화된 동영상 자료는 정보의 다른 정보형태보다 뛰어난 표현력으로 인하여 많은 멀티미디어 시스테에서 다루고 있다. 동영상 자료는 여러 프레임들이 모여 구성된 하나의 대용량 자료로 볼수 있지만, 프레임 - 씬(Scene)-영화 등의 계층적 논리적 구조로 볼 수 있다. 동영상 자료의 검색을 위한 색인 생성과, 복잡한 개체들의 조합으로 볼 수 있는 동영상 자료의 효율적인 관리를 위해서, 동여상 자료를 논리적으로 구조화하는 작업은 필요하다. 동영상의 논리적 분류는 픽셀 검사 및 밝기 히스토그램, 색상 히스토그램 등을 이용한 프레임간 검사를 통하여 자동적으로 행해질 수 있다.
데이터베이스에 저장된 동영상에 대하여 적용할수 있는 질의의 종류로는 여러 가지가 있다. 먼저 특정 속성을 검색하는 질의 종류가 있으며, 영상 자료의 경우와 마찬가지로 동영상의 내용을 입력받을 수 있는 메카니즘을 지원하여 그에 해당하는 내용을 검색하는 내용기반 질의 종류가 있다. 마지막으로 복잡한 계층적 구조를 가지는 동영상에 대하여 포함관계나 참조관계 등을 만족하는 자료를 찾는 구조적 질의가 있을 수 있다.
아직까지 동영상에 대한 질의 처리를 효율적으로 수행하는 시스템은 많이 발표되어 있지 않으나, 주문형 비디오 시스템 등 점차 동영상을 기본 매개체로 하는 시스템이 요구됨에 따라 이에 대한 연구가 활발히 진해되고 있다.
4. 멀티미디어 데이터베이스의 트랜잭션 처리
4.1 멀티미디어 데이터베이스에서의 트랜잭션의 특징
기존의 데이터베이스 트랜잭션 처리에 비하여 멀티미디어 데이터베이스에서의 트랜잭션처리에서 나타나는 특징은, 장기 트랜잭션(long transaction)이 많이 나타난다는 것이다. 그것은 멀티미디어 자료의 복잡성에 의하여 한 개체나 그의 일부분을 여러 사용자가 동시에 접근하는 경우가 많다는 이유와, 멀티미디어 자료의 대용량성에 의하여 한 개체를 삽입, 삭제, 갱신하는 데에 소요되는 시간이 기존의 자료형들을 처리할 경우보다 오래 걸린다는 이유에 기인한다.
멀티미디어 정보 처리에 필요한 장기 트랜잭션을 기존의 단기 트랜잭션과 같은 방식으로 처리한다면 여러 가지 비효율적인 점들이 나타날 수 있다. 데이터베이스 연산이 취소되었을 경우에는 전체 트랜잭션이 복귀 처리(rollback process) 되어야 한다. 이것은 트랜잭션의 원자성에 기인하는데, 장기 트랜잭션에 있어서는 복귀 처리의 비용이 일반 트랜잭션에 비하여 무시할 수 없을 만큼 비싸게 된다. 또한 제한된 자원하의 시스템에서 트랜잭션이 커지고 복잡해진다면 다른 트랜잭션과의 자원 경합이 많아지게 된다. 데이터베이스 시스템은 여러 트랜잭션의 자원 요청을 중재, 처리해 주어야 하는데, 자원 경합이 많아질수록 데이터베이스 정보 접근에 드는 비용보다 데이터베이스정보 접근에 드는 비용이 많아지게 된다. 효과적인 데이터베이스 시스템이 되기 위하여는 자원 관리를 능률적으로 진행하여야 한다. 마지막으로 장기 트랜잭션이 발생하는 경우는 복잡한 자료에 대하여 많은 사용자들이 동시에 작업하는 CSCW(Computer Supported Cooperative Work) 분야가 있을 수 있는데, 기존의 트랜잭션 모델은 이러한 분야에 비적합하다고 알려져 있다.
멀티미디어 및 객체지향 데이터베이스에서 빈번히 등장하는 장기 트랜잭션의 효율적인 관리를 위하여 여러 가지 트랜잭션 관리 기법들이 제안되어 왔다. 그들 중 대표적인 것이 중첩 트랜잭션(nested transaction) 방법과 협력 트랜잭션(cooperating transaction)이다. 중첩 트랜잭션이란 제목에서부터 추측할 수 있듯이 트랜잭션을 계층화하여 주 트랜잭션을 여러개의 부 트랜잭션으로 구성하는 방법이다. 협력 트랜잭션은 데이터베이스 자원을 여러 사용자가 동시에 사용함에 있어서 효율적인 자원 관리를 위하여 동시성 제약조건을 완화하여 트랜잭션처리를 수행하는 방법이다. 멀티미디어 데이터베이스는 이들 트랜잭션 처리기법을 수용하여 사용자들이 멀티미디어 자료 처리를 효율적으로 할 수 있도록 하여야 한다.
4.2 동시성 제어
여러 트랜잭션이 동시에 수행되는 경우, 데이터베이스의 일관성을 해치는 경우가 생길수 있다. 이를 방지하기 위해서는 수행의 동시성을 제어해야 한다. 수행의 동시성을 제어하기위하여는 잠금(looking) 기법을 사용한다. 기존의 데이터베이스 시스템과 비교하여 멀티미디어 데이터베이스의 잠금 기법에서 타이가 나는 것은 다단위 잠금(Multigranularity lock-ing)기법의 단위들이다.
다단위 잠금 기법은 여러 사용자들의 로크(lock) 기다림 시간을 최소화하면서 동시에 소요되는 로크의 수를 최소화하기 위하여 과안되었다. 기존의 데이터베이스 시스템에서 다단위 잠금 기법을 위해 선택되는 단위들은 레코드, 블록, 데이터베이스 등의 일반적이며, 멀티미디어 데이터베이스에서는 특성에 맞도록 단위가 설정되어야 한다. 단위를 너무 좁게 설정하면 작업의 동시성은 향상되나 잠금 터리에 소요되는 비용이 많으며, 단위를 너무 넓게 설정하면 잠금 처리에 소요되는 비용은 적게 되나 작업의 동시성이 떨어지게 되므로 응용분야의 특성에 맞는 단위를 설정하는 것이 필요하다.
멀티미디어 데이터베이스에서 설정할 수 ?는 잠금 단위(lock granule)의 설정을 위하여 고려해 보아야 할 점으로는 다음과 같은 것들이 있다. 먼저 물리적 저장 구조 수준의 잠금 다위 설저이다. 블록(block) -클러스터(cluster) - 익스텐트(extent)와 같이 물리적 저장구조의 단위에따라 잠금 단위를 설정할 경우 데이터베이스 저장 시스템을의 접근시 동시성 제어가 용이하다. 다음으로는 객체지향 데이터베이스에 멀티미디어 자료가 관리될 경우, 객체 인스탄스(instance) 및 클래스의 잠금 단위 설정이다. 멀티미디어 자료는 사용자 혹은 새스템이 제공하는 클래스에 의해 자료형이 설정되고 인스탄스(instance) 및 클래스의 잠금 단위 설정이다. 멀티미디어 자료는 사용자 혹은 시스템이 제공하는 클래스에 의해 자료형이 설정되고 인스탄스가 생성되므로 클래스별 및 객테별 잠금 단위 제공은 필수적이다. 또한 클레스 상속 계층(class inheritance hierarchy)에 대하여 잠금 단위 설정이 제공되는 것이 바람직하다. 마지막으로 part-of 관계에 의해 생성된 복합 멀티미디어 객체를 처리해야 하는 경우가 많으므로 객체에 대하여 그 객체를 구성하는 부객체별로 잠금 단위를 설정할수 있다면 복잡한 멀티미디어 정보를 다루는 응용 시스템에서 효율적인 동시성 제어가 가능해진다.
4.3 회복기법
트랜잭션의 수행 취소 또는 시스템의 오류가 발생한 경우 데이터베이스의 일관성을 유지하기 위하여 회복기능이 필요하다. 회복기능을 제공하기 위하여 많은 회복방법들이 개발되었는데, 그중에서도 가장 널리 쓰이고 있는 방법은 '수행기록에 근거한 회복방법(log-based recovery)'이다. 이 방법은 자료의 변화를 수행기록(log)에 기록해 두었다가 회복과정에서 이 수행기록을 이용하는 방법이다. 멀티미디어 데이터베이스에서 회복이 대상이 되는 자료들은 데이터베이스와 세그먼트, 클래스, 멀티미디어 객체와 객체 식별자를 위한 색인이며 이들 자료의 변화는 수행기록으로 남겨지게 된다.
데이터베이스마다 고유의 회복 알고리즘을 사용하여 회복과정이 진행되게 되나, 대용량 멀티미디어 자료의 효율적인 회복을 위하여는 그 머릿종보(header information)의 변화만을 수행기록으로 남기고, 자료의 내용은 shadow-paging기법을 이용하여 이전 자료의 내용을 디스크 내에 남아있게 한 후에 회복시 그를 이용하고 회복의 필요가 없을 경우 검사점(checkpoint)이 수행되는 시기에 그를 삭제하는 방식 등의 별도의 처리과정이 행해지게 된다.
5. 멀티미디어 자료의 색인 기법 및 군집화
5.1 대용량 자료(BLOB)를 위한 색인 기법
대용량 자료는 그 크기가 정해져 있지 않고, 또 일반적으로 디스크의 여러 페이지에 나뉘어 저장되는 경우가 많다. 이러한 대용량 자료의 저장을 위해 간단하게 연결 리스트(linked list)의 사용을 생각할 수 있다. 각 페이지가 연결 리스트의 노드가 되도록 구성하는 것이다. 하지만 대용량 자료는 앞장에서 기술한 바와 같이 한 번에 읽거나 쓰지 못하는 경우가 많기 때문에, 저양된 특정 위치에 대한 접근이 필요하다. 이 경우 연결 리스트로 구성된 자료 형태는 특정 위치에 접근하기 위해서 평균50%의 페이지를 참조하여야 하는 단점이 있다.
연결 리스트가 효율 상에 치명적인 단점이 있음에 비하여 디렉토리 구조를 사용하여 대용량 자료의 페이지를 관리하는 기법은 구현이 간단하면서 효울 면에서 가장 효과적인 방법으로 볼 수 있다. 이 기법은 대용량 자료의 페이지 정보를 디렉토리로 관리하는 형태로, 디렉토리의 크기는 다루고자 하는 대용량 자료의 최대크기를 고려하여 정해진다. 이 기법의 단점은 디렉토리의 크기가 최대 크기로 고정되어 있기 때문에 발생하는 공간의 낭비와 관리의 어려움이다. 예를 들어, 2000,000,000 바이트의 대용량 자료까지 다루고자 하고, 각 페이지에 10,000 바이트씩 저장 가능하다 가정하고, 각 페이지에 10,000바이트씩 저장 가능하다 가정하고, 각 페이지의 포인터를 위해 8 바이트를 사용한다면 한 디렉토리의 크기는 1,600,000바이트로 정해진다. 여기서, 한 대용량 자료를 위하여 1,600,000바이트의 공간을 별도로 사용하여야 하는 낭비를 볼 수 있다.
이를 보완하기 위하여 B? 트리를 응용한 Positional B?트리를 사용할 수 있다. Positi-onal B?트리 기법은 B?트리의 Key 대신에 위치 정보를 기록한 것으로 삽입, 삭제, 접근방법에 있어서 B?트리와 유사한 형태를 가진다.
5.2 내용 검색을 위한 색인 방법
멀티미디어 데이터베이스 응용프로그램들은 속성(attribute) 에 대한 검색만이 아니라 내용
(content)에 대한 검색도 빈번히 사용한다. 즉, 한 멀티미디어 객체는 키워드들의 집합으로 그 내용을 표현할 수 있고, 응용 프로그램들에서는 이들 키워드를 포함한 질의로 찾고자 하는 객체를 표현하나. 이 때, 키워드를 사용한 질의 처리의 응답 시간을 줄이기 위해 색인을 사용한다.
내용 검색을 위한 역색인(inverted index)은 키워드 들에 대해 관련된 객체들의 집합을 조합한 보조 저장 구조이다. 멀티미디어 객체들의 집합이 있고, 각 객체들의 내용에 대한 키워드의 리스트가 존재한다고 가정하자. 이째 역화일 (inveted file)은 키워드들에 대한 정렬리스트(sorted list)형태를 가지며, 각 키워드에 대해 관련있는 모든 객체들의 시별자를 관리한다. 역화일을 사용함으로서 방대한 자료들에 대한 검색 효율을 높일 수 있다. 또, 각 객체에서 키워드가 갖는 가중치를 쉽게 포함시킬 수 있는데, 이는질의에 대한 결과의 순서를 결정하는데 도움을 준다. 하지만, 이런 방식으로 검색 효율을 높이기 위해 별도의 기억공간을 많이 차지하고 있다는 것은 단점으로 나타난다. 원래 파일 크기의 10% 에서 100%, 혹은 그이상의 기억 공간이 역화일을 위하여 필요할 수 있다.
요약 색인(signature index)방법은 역색인 방법에 비해 필요한 기억 공간의 크기 면에서 상당히 유리하다. 이 방법은 각 객체에 대하여 요약 코드를 생성하고 이 요약 코드에 대해 색인한다. 어떤 질의가 사용자에 의해 수행되었을 때, 질의내용에 대해 요약 코드를 생성하고 요약 색인 파일과 대조한다. 이 과정에서 질의와 관계가 전혀 없는 객체를 요약들 사이의 수학적 계산만으로 판단, 제외시킨다. 예를 들어 슈퍼임포즈 코딩(superimposed coing)에 의해 요약 코드를 생성하는 방식에 대해서 살펴보자. 우선 각 키워드에 대해 해슁 함수를 사용하여 이진 코드를 생성한다. 그리고,멀티미디어 객체나 문서들은 관련된 키워드에 대한 이진 코드의 논리합이 요약 코드로 갖는다. 질의를 처리하는 과정은, 질의에 포함되어 있는 키워드의 논리합을 요약 코드로 생성하여 각 객테를 표현하는 요약 코드로 구성된 요약 색인 파일과 대조한다. 대조 과정은 요약 코드들에 대해 간단히 논리곱만을 수행함으로서 관계가 없는 문서들을 확인할 수 있다.
요약 색인 방법은 요약 파일의 크기가 원래 문서보다 월등히 작기 때문에 자료 내용을 스캐닝(scanning)하는 작업에 비해 빠를다. 그러나, 역화일을 사용하는 것보다는 자료들에 대해 일일이 비교하는 과정이 있기 때문에 사용자나 시스템에 의한 별도의 필터링(filter-ing) 과정이 필요할 수 있다. 대신, 역화일보다 기억공간을 적게 필요로 하며 새로운 자료를 쉽게 삽입할 수 있는 장점이 있다.
5.3 군집화(clustering)
많은 멀티미디어 데이터베이스 응용 프로그램들은 설계 도면이나 3차원 그래픽 객체 등을 지원하기 위하여 복합 객체(complex object)를 사용하고 있다. 이러한 복합 객체들을 다루는 과정에서, 군집화는 보조 기억장치의 전테접근 횟수를 줄이기 위하여 동시에 접근되는 횟수가 많은 객체들끼리 인접하여 보조 기억장치에 위치하도록 저장하는 기법이다.
군집화는 데이터베이스 스키마에 지정된 객체의 구조나 타입을 근거로 저장 위치를 결정하는 정적(starically)수행이나 프로그래머가 객체의 저장 위치를 직접 지정하는 동적(dy-namically)수행을 한다. 물론, 응용 프로그램이 객체를 어떤 형태로 읽는가를 잘 알고있는 프로그래머가 객테의 저장 위치를 지정하는 동적 수행이 성능상 좋은 결과를 보인다. 하지만, 일반적인 경우 프로그래머가 데이터베이스에서 자료를 기록할 때 보조기억장치의 기록 위치까지 지정해주지는 않기 때문에, 정적 군집화의 전략을 어떻게 세우는가에 따라 전체적인 성능에 영향을 끼틴다. 다음 세 가지 모델은 정적군집화의 대표적인 전략이다.
* 직접 저장 구조 모델(Direct Storage Model)
이 모델의 특징은 한 복합 객체를 가능하다면 한 장소에 저장을 한다는 점이다. 즉, 부 객체(subobject)들은 가능하다면 그들의 부모 객체와 인접한 곳에 정장한다. 이 과정에서, 깊이우선(depth first)전략이나 넓이 우선(breadth first)넌략 등의 여러 전략이 적용될 수 있다.
이 모델은 전체 복합객체를 아주 효율적으로 추출할 수 있다는 장점을 가진다. 그러나, 객체 영역은 트리 형태가 아니라 그래프 형태이기 때문에, 한 복합 객체가 다른 복합 객체의 부 객체를 같이 공유한다면 복사본을 두던가 참조 푄터를 두고 관리를 위한 부담을 가지고있고, 참조 포인터의 경우 직접 저장 구조 모델의 장점을 잃어버리는 단점을 가지게 된다.
* 정규화 저장 구조 모델(Normalized stor-age Model)
복합 객체 모델을 관계형 데이터베이스의 3차 정규형(3NF)으로 대응하는 형태와 유사한 모델이다. 즉 복합 객체를 분석하여 같은 형태의 자료들끼리 묶어서 저장을 하는 것이다. 이렇게 같은 형태의 자료가 묶이게 됨으로서 다른 부모 객체에 포함되어 있는 자료라도 효율적으로 접근할 수 있다는 장점이 있다.
* 분해 저자 구조 모델(Decomposed Storage Model)
복합 객체의 모든 속성을 분해하여 두 개의 속성만을 가지는 테이블들로 관리하는 모델이다. 이 모델의 장점은 단순성과 일반화이다. 여러 형태의 접근 방법이 존재하는 여러 복합 객체를 저장하는 방법이 단순하고, 여러 다른 타입의 접근에 대해 일정한 성능을 보인다. 물론 가장 큰 단점은, 만일 복합 객체가 재구성될 경우 많은 수의 조인을 발생시킨다는 점이다.
6. 결론
본 논문에서는 멀티미디어 데이터베이스의 개념에 대하여 설명하였고, 멀티미디어 데이터베이스에서 정보를 저장, 관리하기 위한 여러 기술에 대하여 살펴보았다. 지면 관계상 간략히 중요 부분만을 서술하였다.
멀티미디어 데이터베이스 기술은 향후의 정보 시스템 구축의 중요한 부분을 차지한다. 현재 각광받고 있는 정보 시스템인 WWW은 인터넷 상에 존재하는 멀티미디어 정보들을 상용자에게 제공할 수 있는 기능으로 인하여 성공적으로 평가 받았으며, 데이터베이스에 저장된 멀티미디어 정보를 WWW 을 통해 제공하는 연구가 계속 행해지고 있다. 또한 주문형 비디오 시스템 등에 있어서 많이 연구되고 있는 것은 정보 서비스의 근간이 되는 멀티미디어 자료를 관리 및 제공하는 멀티미디어 데이터베이스 기술부분이다.
이와 같이 멀티미디어 정보의 처리 기능과 효율적인 관리 기능에 대한 중요성은 널리 인식되어 있으며, 그 결과로 이 분야의 많은 연구가 진행되고 있다. 향후 각 대학, 업체 그리고 연구소들은 효율적인 멀티미디어 데이터베이스 시스템을 구축하기 위하여 더욱 많은 연구와 개발을 경주할 것으로 예상된다.
참고문헌
[1] 김 명호, 이 윤준, "멀티미디어-개념 및 응용", 홍릉 과학 출판사, 1996.
[2] 오 영환, "패턴 인식론 : 문자, 음성, 화상", 정익사,.1991.
[3] David P. Anderson and george Homsy, "A continuous Media I/O Server and Its Sunchronization Mechanism", IEEE Computer, October 1991.
[4] Prabhat K. Andleigh, Kiran Thakrar, "Multimedia Systems Design", Prentice Hall, 1996.
[5] A. Billris, "An Efficient Database Storage Structure for Large Dynamic Objects", proc. IEEE Intl. Conf. on Data Engineering, Arizona, Feb 1992.
[6] E.A. Fox, "Advances in Interactive Digital Multimedia Systems", IEEE Computer, Vol.24,No. 10, 1991, pp.9-21.
[7] W.B. Frakes, R. Baeza-Yates, "Information Retrieval: Data Structures and Algorithms", Prentice Hall, 1992.
[8] Jim Gray, Andreas Reuter, "Transaction Processing : Concepts and Techniques", Morgan Kaufmann Publishers, 1993.
[9] Illustra, "Illustra User's Guide", Illustra Information Technologies Ic., Oct.1995.
[10] ISO/IEC 9075, "Database Language SQL ", International Standard ISO/IEC9075 :1992,New York, November 1992.
[11] ISO/IEC SQL Revision, "ISO-ANSI Working Draft Database Lanugage SQL(SQL3), document ISO/IEC JTC1/SC21 N6931, ANSI, NY, July 1992.
[12] Setrag Khoshafian, A. Brad BAKER, "Multimedia and Imaging Databaeses", Morgan Kaufmann Publishers, 1996.
[13] Ralf Steinmetz, Klara Nahrstedt, "multimedia : Computing, Communications and Applications",prentice Hall, 1995.
[14] R. Steinmetz, " Analyzing the Multimedia Operating System", IEEE Multimedia, 1995,PP. 68-48
[15] B.O.Szuprowicz, "Multimedia Technology: Combining Sound, Text, Computing, Graphics and Video", technology Research Corporation, 1992.
[16] UniSQL, "UniSQL/X User's Manual", UniSQL iNC, Release 3.1, May 1995.
양 철 웅
1993 한국과학 기술대학 전산하과 학사
1995 한국과학기술원 전산학과 석사
1995 ~ 현재 한국과학기술원 전산학과 박사과정 재학중
관심분야 : 능동 데이터베이스, 멀티미디어, 분산 객체 시스템, WWW-DBMS 연결
양 우 석
1993 한국과학 기술대학 전산학과 학사
1995 한국과학기술원 전산학과 석사
1995 ~ 현재 한국과학기술원 전산하과 박사과정 재학중
관심분야 : 능동 데이타베이스, 디지탈 하이브러리, 멀티미디어, 컴퓨터 애니메이션
이 윤 준
1977 서울대학교 이과대학 계산통계학과 학사
1979 한국과학기술원 전산하과 석사
1983 프랑스 INPG-ENSIMA-G 전산학과 박사
1983 EMAG 연구원
1984~94 한국과학기술원 부교수
1995 ~ 현재 한국과학기술원 정교수
관심분야 :분산 데이터베이스, 정보 검색,트랜잭션처리, 데이터베이스 응용
김 명 호
1982 서울대학교 컴퓨터 공학과 학사
1984 서울대학교 컴퓨터 공학과 석사
1989 MICHIGAN 주립대 연구원
1989~93 KAIST 조교수
1992~93 개방형 컴퓨터통신연구회(OSIA) 분산트랜잭션 처리 분과위(TG-TP)의장
1993~94 한국통신기술협회(TTA) 분산 트랜잭션처리 실무 위원회 의장
관심분야 : 분산데이타베이스, 분산트랜잭션, 멀티미디어 데이터베이스
|
