|
DBMS에서 Index의 주된 역할은 주어진 값(Key Value)에 대한 정보를 데이터 집합(테이블 또는 …)에서 빠르게 추출하고자 하는 것이다. 전통적으로 RDBMS에서는 B-Tree라는 구조를 가지고 이러한 목적을 충족시켜 왔다. B-Tree Index는 주어진 값(Key Value)와 집합 내에서 해당정보의 물리적 위치(오라클의 경우 ROWID, MS-SQL Server의 경우 RID 등.) 정보를 정렬된 형태로 가지고 있어 원하는 정보를 정렬된 구조에서 빠르게 찾아 해당하는 데이터(테이블의 Row)를 추출하는 역할을 가지고 있다. 하지만, B-Tree Index는 다음과 같은 IT 환경의 변화에 능동적으로 대처하기에는 많은 한계점을 드러내고 있다.
대용량 데이터에 대한 분석 필요성 대두 (Data Warehouse)
비즈니스 환경 변화는 수년간 (historical data) 기업의 서로 다른 운영계 시스템에서 축적된 데이터에 대해서 다양한 각도로 분석을 가능케 하는 (multi-dimensional analysis) 통합 시스템의 필요성이 대두 되고있다. 통합 시스템 필요성의 대두는 대용량의 데이터 처리와 관리 기능을 요구하게 되었다.
사용자 위주의 Computing 환경의 필요성 대두
정보 기술(IT)의 일반화와 비즈니스 영역에서의 경쟁 심화는 기존 몇몇 특수한 사용자(개발자,…)로 접근이 제한되었던 정보를 기업의 구성원 누구나 쉽게 접근하고 활용할 수 있도록 되었다. 또한, 위에서 언급한 통합시스템이 구성됨으로써 각종 정보의 분석이 손쉬워 졌으며, 사용자의 다양한 분석 요구가 증가하게 되었다. 이러한 환경의 변화는 DBMS 벤더로 하여금 보다 유연성 있으면서 일정 성능을 보장할 수 있는 기능을 요구하게 되었다.
위와 같은 정보기술(IT) 환경의 변화는 전통적인 B-Tree Indexing기법으로는 해결할 수 없는 다음과 같은 문제점을 발생하게 되었다.
저장공간의 낭비
B-Tree Index는 테이블 Column값과 집합 내에서 해당정보의 물리적 위치(오라클의 경우 ROWID, MS-SQL Server의 경우 RID 등.) 정보를 정렬된 형태로 가지는 구조이므로 동일 값에 대해서 물리적 주소가 다른 경우 동일 값을 중복해서 가지고 있어야 함으로 저장공간의 낭비가 발생하게 된다. 또한 테이블 Column값의 길이가 큰 경우 Index의 원시 값을 그대로 가짐으로써 Index의 크기가 증가하게 된다. 기존 OLTP 환경에서는 Index의 크기가 문제가 되지 않겠지만 통합시스템에서는 절대적인 데이터 양이 크게 되므로 인덱스의 크기 또한 막대해 질 수 있을 것이다.
유연성(Flexibility)의 부족
B-Tree Index에서는 동일한 테이블에 대한 Access시에 두 개 이상의 Index를 병행해서 사용하는 데에 많은 제약사항이 따른다. 그러나 실제 업무 환경에서는 사용자의 요구 사항은 매우 다양하다. 이러한 요구사항을 만족하기 위해서는 테이블의 모든 컬럼의 조합만큼의 B-tree Index를 만들어야 하며, 이렇게 한다고 하면 테이블의 크기보다 오히려 Index의 크기가 더 커지는 기현상을 초래할 수 있다. 또한, 각각의 인덱스를 관리하는 비용이 테이블 자체를 관리하는 비용보다 커질 수 있을 것이다. 따라서 실제 업무에는 거의 적용하기 불가능한 경우라고 할 수 있겠다.
예를 들어서 설명하면, 분포도가 넓은 컬럼 값(즉, 중복된 데이터가 많은 값)을 선행하는 두개의 B-Tree Index가 있다. 사용자가 각각 인덱스 선행 컬럼에 해당되는 조건을 주고, 두 조건을 동시에 만족하는 값이 적다고 가정하면, 두개의 인덱스를 Access하여 두 조건을 동시에 만족하는 값만 테이블 Access하면 효율적이었을 것이다. 그러나 두개 이상의 인덱스를 동시에 사용하는데 제약사항이 많아 한 개의 인덱스를 사용하게 되면 넓은 범위를 읽게 되어 비효율이 발생하게 될 것이다. 혹자는 "두개의 컬럼으로 구성된 결합인덱스를 만들면 되지 않겠는가?"라고 질문 할 수 있다. 그러나 사용자 요구가 바뀌게 되면 또 다른 인덱스를 만들어야 할 것이다. 이렇게 만들다 보면 최후에는 인덱스의 관리 비용이 테이블의 관리비용을 넘어서게 되는 것이다.
위와 같은 문제점을 극복하기 위한 여러 가지 기술이 선보였으나, 그 중에서 현실적인 대안이 될 수 있는 기술 중 하나인 Bitmap Indexing 기법에 대해서 몇 차례에 걸쳐서 자세히 논의 하고자 한다.본 연재에서는 Oracle 사의 DBMS가 구현한 Bitmap Index를 기준으로 설명하겠다. 이번 연재에서는 Bitmap Index의 개념과 몇 가지 특이한 사용예제를 설명하고, 이후 연재에서 보다 자세한 Bitmap Index 내부구조, 제약사항, 활용방안에 대해서 언급하고자 한다.
Bitmap Index의 개념
Oracle bitmap Index Definition
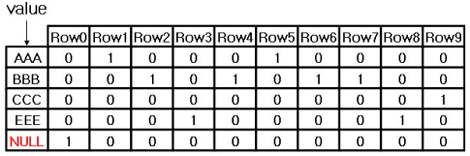
Bitmap이란 어떤 값의 존재 여부를 1과 0으로만 표현된 표를 만든다는 것이다. 즉 아래 그림과 같이 value 값이 AAA, BBB, CCC, EEE, Null이 존재 할 때 각 레코드들이 어떤 값을 가지고 있는지를 1과 0만을 사용하여 표현한 것이다. Oracle사의 경우는 Equality Encoding 방식을 사용하므로 한 레코드는 반드시 하나의 1값을 가져야 한다. DBMS에 따라서는 Range 또는 Interval Encoding 방식을 사용하기도 한다.
Bitmap Index의 경우도 마찬 가지로 표현되어지는 것은 결국 1과 0으로만 구성된 집합이다. 각 값은 한 레코드의 값을 대표하게 된다. 이는 한 레코드를 표현하기 위해서 1bit만 필요하게 되므로 적은 양의 공간으로 많은 수의 레코드 값이 표현 가능한 것이다. 예를 들어서 Value 값이 AAA인 경우를 찾는다고 하면 단순하게 AAA 값의 Bitmap을 읽어서 값이 '1'인 레코드만 추출하면 되는 것이다. 위 그림에서는 10 bit만 읽으면 원하는 결과를 얻을 수 있을 것이다.
Bitmap Index의 특이한 사용 사례
Null 값 비교도 Bitmap Index를 사용한다.
SELECT COUNT(*)
FROM CUSTOMER
WHERE STATE IS NULL
기존 B-Tree Index 에서는 위의 SQL을 실행하게 되면 인덱스를 사용하지 못했을 것이다. B-Tree Index에서는 인덱스를 구성하고 있는 컬럼 값이 Null인 경우에는 저장하지 않는다. 그러나 Bitmap에서는 Null 또한 하나의 값으로 인식하여 저장하게 되므로 인덱스를 사용할 수 있을 것이다.
Not Equal 비교도 Bitmap Index를 사용한다
SELECT COUNT(*)
FROM CUSTOMER
WHERE STATE !='KR'
기존 B-Tree Index에서는 NOT EQUAL 비교 연산을 수행할 때 인덱스를 사용할 수 없었다. 만약 B-Tree Index를 사용해서 비교 연산을 수행한다면 모든 값을 읽어야 할 것이다. 그러나 Bitmap index의 경우는 일어야 할 범위가 EQUAL로 들어 왔을 때와 비슷하다. EQUAL 연산의 경우는 bit 값이 '1'인 것을 추출하면 되고, NOT EQUAL의 경우는 '0'를 추출하면 되기 때문이다,
다음 연재에서는 Oracle 사의 Bitmap인덱스의 내부구조와 저장방식에 대해서 좀더 자세히 살펴 보고자 한다. 약간은 기술적으로 어려운 부분일수 있으나 원리만 잘 이해한다면, 위에서 언급되었던 문제점을 어떻게 극복할 수 있는지, 실제 업무에 어떻게 사용될 수 있는지 알 수 있을 것이다.
|
